
Google leak: svelati i segreti degli algoritmi di Google?
Altro che “solo” 200 fattori di ranking! In questi giorni la Rete e i SEO stanno analizzando con minuziosa attenzione un documento interno di Google finito in Rete per errore e svelato da Rand Fishkin e Michael King, che contiene alcuni dei segreti del funzionamento di Google Search! Nelle oltre 2.500 pagine di documentazione API, infatti, sono spiegati 14.014 attributi (funzionalità API) che sembrano provenire dal “Content API Warehouse” interno di Google. In altre parole, questo enorme Google Leak rivela dettagli inediti sul funzionamento degli algoritmi di ricerca del gigante tecnologico, con aspetti importantissimi del motore di ricerca, della sua infrastruttura software, di cosa faccia ogni singolo modulo software e di quali siano i ben 14mila valori che il motore tiene in considerazione per poter costruire ogni SERP!
Google leak: una rivoluzione per la SEO?
I documenti sembrano provenire dall’archivio interno Content API Warehouse di Google e, come detto, sono stati condivisi agli inizi di maggio 2024 da una fonte (inizialmente) anonima con Rand Fishkin e Michael King, due noti esperti di SEO.

Fishkin, co-fondatore della società di audience analysis SparkToro, e King, CEO di iPullRank, hanno ricevuto circa 2.500 pagine di documenti che descrivono dettagli tecnici relativi al funzionamento dell’algoritmo di Google, e hanno analizzato questo contenuto rivelando informazioni che potrebbero cambiare il panorama della SEO.
Questa fuga di notizie ha infatti il potenziale di rivoluzionare il modo in cui comprendiamo e approcciamo l’ottimizzazione per i motori di ricerca, perché offrono una visione senza precedenti dei meccanismi interni di Google. Ecco come il nostro CEO Ivano Di Biasi ha raccontato la notizia e commentato i punti principali che emergono da questo Google Leak!
Cosa c’è nei documenti del Google leak
Negli ultimi venticinque anni, non si era mai verificata una fuga di notizie di tale portata o dettaglio dalla divisione di ricerca di Google. Nello specifico, questi file rivelano dettagli intricati su come Google classifica i contenuti, gestisce i dati degli utenti e utilizza vari segnali per determinare il ranking delle pagine web.
- Clic degli utenti. Una delle rivelazioni più significative riguarda l’uso di metriche di engagement degli utenti, come “goodClicks” e “badClicks”, che sono legate a sistemi chiamati Navboost e Glue. Questi sistemi, menzionati anche durante la testimonianza di Pandu Nayak nel caso Google/DOJ, sono utilizzati per filtrare i clic che Google considera rilevanti per il ranking, escludendo quelli che non lo sono. Inoltre, Google misura la durata dei clic, un indicatore di soddisfazione dell’utente, e le impressioni, fornendo ulteriori prove dell’importanza dei dati di clic nel determinare il ranking. Queste metriche valutano la qualità dell’esperienza utente su una pagina e riflettono il comportamento reale degli utenti e la loro soddisfazione con i risultati di ricerca. Insomma, Google utilizza le informazioni del search journey per affinare il ranking delle pagine, premiando quelle che offrono una migliore esperienza utente.
- Autorità del sito. Molta sorpresa – soprattutto per il contrasto rispetto alle dichiarazioni ufficiali dei Googler – l’ha destata il concetto di Site Authority. Questo termine si riferisce all’autorità complessiva di un sito web, che Google utilizza per valutare la qualità e la pertinenza dei contenuti. La Site Authority è influenzata da vari fattori, tra cui la qualità dei contenuti, i link in entrata e l’engagement degli utenti. Un sito con alta autorità ha maggiori probabilità di posizionarsi bene nei risultati di ricerca rispetto a un sito con bassa autorità – è il principio della nostra Zoom Authority!
- Siti piccoli e blog. A proposito di autorevolezza, il leak rivela l’utilizzo di una funzione chiamata smallPersonalSite: i siti personali o blog di piccole dimensioni potrebbero essere trattati in modo diverso rispetto ai grandi siti commerciali. I documenti suggeriscono infatti che Google potrebbe utilizzare moduli specifici o flag per valutare e classificare questi siti, potenzialmente offrendo loro un trattamento preferenziale o penalizzandoli a seconda della qualità e della pertinenza dei loro contenuti.
- Età e storia del brand. I documenti rivelano anche l’importanza della storia del brande dei domini scaduti. Google tiene infatti conto della storia di un dominio e del brand associato quando valuta la sua autorità e pertinenza. Un dominio con una lunga storia di contenuti di alta qualità e un brand ben riconosciuto avrà un vantaggio rispetto a un dominio nuovo o con una storia meno solida. Questo implica che la continuità e la coerenza nel tempo sono fattori cruciali per il successo nel ranking.
- Dati Chrome. Un altro aspetto cruciale è l’uso dei dati di clickstream raccolti tramite il browser Chrome. Google utilizza questi dati per calcolare metriche che influenzano il ranking delle pagine, come il numero di clic su pagine specifiche, determinando così le URL più popolari e importanti di un sito. Questo approccio permette a Google di avere una visione dettagliata del comportamento degli utenti su Internet, utilizzando queste informazioni per migliorare la pertinenza dei risultati di ricerca.
- Whitelist per settori. I documenti rivelano anche l’esistenza di whitelist per settori specifici come viaggi, COVID-19 e politica. Queste whitelist garantiscono che solo domini affidabili appaiano per query potenzialmente problematiche o controverse, evitando la diffusione di disinformazione. Ad esempio, durante eventi critici come le elezioni presidenziali, Google utilizza queste whitelist per assicurarsi che le informazioni visualizzate siano accurate e affidabili.
- Archiviazione delle versioni delle pagine. Google conserva copie di ogni versione di ogni pagina web che ha mai indicizzato, in modo da “ricordare” ogni modifica apportata a una pagina nel corso del tempo, creando una sorta di archivio storico digitale di tutte le pagine web. Questa pratica consente a Google di monitorare l’evoluzione dei contenuti di una pagina e di valutare come le modifiche influenzano la qualità e la pertinenza della stessa – elemento particolarmente utile per identificare e penalizzare pratiche black hat di manipolazione dei contenuti, come il cloaking, dove il contenuto mostrato ai motori di ricerca è diverso da quello mostrato agli utenti. Inoltre, la conservazione delle versioni delle pagine aiuta Google a valutare la coerenza e l’affidabilità di un sito web nel tempo, premiando potenzialmente i siti che investono nella qualità dei contenuti e nella loro evoluzione continua, piuttosto che quelli che cercano scorciatoie per migliorare temporaneamente il loro ranking. Ad ogni modo, quando si tratta di analizzare i link, Google sembra limitarsi a considerare solo le ultime 20 modifiche di un URL. Questo significa che Google utilizza principalmente le modifiche più recenti per determinare la rilevanza e la qualità dei link.
- Feedback dei Quality Raters. Un altro elemento interessante è l’uso dei feedback dei Quality Rater, raccolti tramite la piattaforma EWOK. I documenti suggeriscono che questi feedback potrebbero essere utilizzati nei sistemi di ricerca di Google, influenzando direttamente il ranking delle pagine (ma non c’è modo di capire quanto siano influenti questi segnali basati sui rater e a cosa servano esattamente). Fishkin evidenzia soprattutto che i punteggi e i dati generati dai valutatori della qualità di EWOK sembrano essere direttamente coinvolti nel sistema di ricerca di Google, piuttosto che rappresentare semplicemente un set di addestramento per esperimenti. Questo indica che le valutazioni umane giocano un ruolo significativo nel determinare la qualità e la pertinenza dei contenuti.
- Entità. Il ruolo delle entità è un altro elemento chiave emerso dai documenti. Google memorizza informazioni sugli autori associati ai contenuti e cerca di determinare se un’entità è l’autore di un documento. Questo indica che Google attribuisce grande importanza all’autorevolezza e alla credibilità degli autori, utilizzando queste informazioni per migliorare la pertinenza e la qualità dei risultati di ricerca.
- Cause di retrocessione. I documenti rivelano anche le cause di “downgrade” di rating (demotion). Google può penalizzare una pagina o un sito per vari motivi, come la presenza di link non pertinenti, segnali di insoddisfazione degli utenti nelle SERP, recensioni di prodotti di bassa qualità, e contenuti pornografici. Questi fattori possono portare a un downgrade del rating, riducendo la visibilità del sito nei risultati di ricerca.
- I backlink. Ancora, i documenti confermano che la diversità e la rilevanza dei link in entrata sono cruciali per determinare l’autorità di una pagina. Google classifica i link in tre categorie (bassa, media, alta qualità) e utilizza i dati di clic per determinare a quale categoria appartiene un documento. I link di alta qualità possono trasmettere segnali di ranking, mentre quelli di bassa qualità sono ignorati.
Da dove arriva il documento segreto di Google
Rand Fishkin ha ricostruito il percorso di questo documento e di come è finito tra le sue mani. Tutto inizia il 5 maggio 2024, quando ha ricevuto un’email da una persona che affermava di avere accesso a una massiccia fuga di documentazione API proveniente dalla divisione Search di Google. L’autore dell’email sosteneva che questi documenti trapelati erano stati confermati come autentici da ex-dipendenti di Google, i quali avevano condiviso ulteriori informazioni private sulle operazioni di ricerca di Google. Fishkin, consapevole che “affermazioni straordinarie richiedono prove straordinarie”, ha deciso di approfondire la questione.
Dopo diversi scambi di email, il 24 maggio Fishkin ha avuto una videochiamata con la fonte anonima. Durante la chiamata, la fonte ha rivelato la propria identità: Erfan Azimi, un praticante SEO e fondatore di EA Eagle Digital. Prima di questo contatto, Fishkin non aveva mai sentito parlare di Azimi. Durante la chiamata, Azimi ha mostrato a Fishkin il leak di Google: oltre 2.500 pagine di documentazione API contenenti 14.014 attributi, apparentemente provenienti dal “Content API Warehouse” interno di Google. La cronologia dei commit del documento indicava che questo codice era stato caricato su GitHub il 27 marzo 2024 e rimosso solo il 7 maggio 2024.
Questa documentazione non mostra il peso specifico degli elementi nell’algoritmo di ranking né prova quali elementi siano effettivamente utilizzati nei sistemi di ranking. Tuttavia, fornisce dettagli incredibili sui dati che Google raccoglie. Dopo aver illustrato alcuni di questi moduli API, Azimi ha spiegato le sue motivazioni, incentrate sulla trasparenza e sulla responsabilità di Google, e ha espresso la speranza che Fishkin pubblicasse un articolo per condividere questa fuga di notizie e smentire alcune delle “bugie” che Google avrebbe diffuso per anni.
Le successive analisi di Fishkin hanno confermo l’affidabilità delle informazioni. La fuga di notizie sembra provenire da GitHub, e la spiegazione più credibile per la sua esposizione coincide con quanto detto da Azimi durante la chiamata: questi documenti sono stati resi pubblici inavvertitamente e brevemente tra marzo e maggio 2024. Durante questo periodo, la documentazione API è stata indicizzata da Hexdocs (che indicizza i repository pubblici di GitHub) e trovata e diffusa da altre fonti. Secondo le fonti ex-Googler di Fishkin, documentazione di questo tipo esiste in quasi tutti i team di Google, spiegando vari attributi e moduli API per aiutare i membri del team a familiarizzare con gli elementi di dati disponibili. Questa fuga di notizie corrisponde ad altre presenti nei repository pubblici di GitHub e nella documentazione API di Google Cloud, utilizzando lo stesso stile di notazione, formattazione e persino nomi e riferimenti di processi/moduli/funzionalità.
La risposta ufficiale di Google al leak
Questa mattina, Google ha risposto alla fuga di notizie con una dichiarazione che cerca di minimizzare l’impatto delle informazioni trapelate. Un portavoce di Google ha affermato che molte delle informazioni pubblicate sono incomplete o fuori contesto e che i segnali di ranking cambiano costantemente.
Per la precisione, in risposta a The Verge, Davis Thompson di Google ha detto: “Invitiamo a non fare supposizioni inaccurate sulla Ricerca basate su informazioni fuori contesto, obsolete o incomplete. Abbiamo condiviso ampie informazioni su come funziona la Ricerca e sui tipi di fattori che i nostri sistemi considerano, lavorando anche per proteggere l’integrità dei nostri risultati dalle manipolazioni”.
Questo non significa che i principi fondamentali del ranking di Google siano stati alterati, ma piuttosto che i segnali specifici e individuali che contribuiscono al ranking sono soggetti a modifiche continue.
Google ha sottolineato che ha sempre condiviso informazioni dettagliate su come funziona la ricerca e sui tipi di fattori che i suoi sistemi considerano, pur lavorando per proteggere l’integrità dei risultati dalle manipolazioni.
Tuttavia, Google ha evitato di commentare sui dettagli specifici dei documenti trapelati. Non ha confermato né smentito quali elementi siano accurati, quali siano obsoleti o quali siano attualmente in uso. La ragione di questa reticenza, secondo Google, è che fornire dettagli specifici potrebbe permettere a spammer e attori malintenzionati di manipolare i risultati di ricerca.
I dubbi sul leak: errore umano o mossa strategica?
Questa fuga di documenti interni ha sollevato numerosi dubbi e perplessità, non solo per il contenuto rivelato, ma anche per le circostanze in cui è avvenuta. Una delle principali questioni riguarda l’affidabilità dei documenti stessi e la possibilità che la loro pubblicazione sia stata il risultato di un errore umano o, come pure alcuni sospettano, una mossa strategica deliberata da parte di Google, orchestrata per distogliere l’attenzione da questioni più pressanti e aggiornamenti significativi nel mondo della SEO.
Da un lato, la spiegazione ufficiale suggerisce che i documenti siano stati resi pubblici inavvertitamente, forse a causa di un errore di configurazione su GitHub. Questa versione dei fatti è supportata dalla cronologia dei commit del documento, che mostra come il codice sia stato caricato e poi rimosso dopo un breve periodo. Tuttavia, la natura dettagliata e complessa della documentazione, insieme alla sua rapida diffusione, ha portato alcuni a ipotizzare che potrebbe esserci di più dietro questo leak.
Tuttavia, la datazione delle informazioni trapelate ha alimentato lo scetticismo: Trevor Stolber ha osservato che i dati provengono da una base di codice deprecata e risalgono al 2019, rendendoli obsoleti e in gran parte irrilevanti per le attuali pratiche di SEO, e Kristine Schachinger ha confermato che i dati sono datati e non offrono nuove informazioni utili.
Inoltre, i documenti trapelati sono stati identificati come documenti API contenenti una lista di chiamate, piuttosto che un dump di codice dell’algoritmo di ranking. Questo significa che i dati non forniscono informazioni dirette su come Google classifica i siti web, limitando ulteriormente la loro utilità per i professionisti della SEO.
Immancabili quindi le dietrologie: secondo alcune teorie, Google potrebbe aver volutamente lasciato i documenti online come una sorta di “arma di distrazione di massa“. Questa ipotesi si basa sul fatto che Google sta attualmente affrontando una serie di problemi significativi, tra cui la causa federale negli Stati Uniti e il rilascio di AI Overview, una nuova funzionalità che ha suscitato molte critiche da parte dei professionisti SEO e dei proprietari di siti web. AI Overview, infatti, fornisce risposte sintetiche alle query degli utenti direttamente nella SERP, riducendo ulteriormente i clic verso i siti originali e sollevando preoccupazioni riguardo all’appropriazione indebita dei contenuti.
In questo contesto, la fuga di documenti potrebbe servire a sviare l’attenzione dai problemi più pressanti che Google sta affrontando. La causa federale, in particolare, rappresenta una minaccia significativa per l’azienda, con potenziali implicazioni legali e finanziarie di vasta portata. Allo stesso tempo, le critiche crescenti verso AI Overview e altre questioni legate al sistema di ricerca potrebbero danneggiare ulteriormente la reputazione di Google.
Insomma: in assenza di prove concrete, tutte le considerazioni restano solo speculazioni. Ciò che è certo è che la fuga di documenti ha generato un dibattito acceso nella comunità SEO e tra i professionisti del settore, sollevando interrogativi sulla trasparenza e sulle pratiche di Google.
Google leak: quali sono le implicazioni per la SEO
Le analisi preliminari dei documenti confermano alcune pratiche sospettate da tempo, come l’importanza dei link e dei contenuti di qualità, ma rivelano anche nuove informazioni, come l’uso dei dati di Chrome per il ranking. Ad esempio, i documenti indicano che Google utilizza dati raccolti tramite il browser Chrome per influenzare le sue SERP (Search Engine Results Page), nonostante l’azienda abbia sempre sostenuto che tali dati non abbiano una rilevanza particolare nella determinazione del ranking. Inoltre, emerge che Google memorizza le informazioni sugli autori associati ai contenuti, indicando l’importanza di questi ultimi nel processo di classificazione.
Quello che non sapevamo: Super Root, Twiddlers e Chrome
Iniziamo dal presentare alcune delle cose più sorprendenti emerse da questo leak, quindi dalle informazioni per così dire nuove.
- Super Root: il cervello di Google Search
Il sistema di ranking di Google è molto più complesso di quanto si possa immaginare. Non si tratta di un singolo algoritmo, ma di una serie di microservizi che lavorano insieme per generare la SERP. Al centro di questa enorme struttura del motore Google c’è un core che si chiama Super Root, che essenzialmente funge da ponte tra tutti i servizi di Google. Quindi, prima di arrivare a qualsiasi tipo di risposta, si passa da questo modulo che va a interrogare le mappe, YouTube e tutti i servizi collegati a Google.
Inoltre, emerge anche che Google non ha già una lista prestabilita di risultati di ricerca da fornirci quando inseriamo una query: l’elenco viene creato e rifinito ogni volta che lanciamo una query. Quindi, se noi interroghiamo Google, gli algoritmi selezionano un insieme di documenti e poi applicano i loro fattori di ranking per riordinare i risultati e fornirceli nell’ordine in cui li vediamo in SERP.
Secondo la documentazione trapelata, esistono oltre cento diversi sistemi di ranking, ciascuno dei quali potrebbe rappresentare un “fattore di ranking”. L’elemento chiave di questa architettura è appunto il Super Root, che può essere considerato il cervello di Google Search. Super Root è responsabile dell’invio delle query ai vari sistemi e della composizione dei risultati finali. In realtà, come ricorda King, una presentazione di Jeff Dean (ingegnere di Google) spiegava già che le prime versioni di Google inviavano ogni query a 1000 macchine per elaborarla e rispondere in meno di 250 millisecondi. Il diagramma dell’architettura del sistema mostra che Super Root invia le query ai vari componenti, come i server di cache, il sistema pubblicitario e i vari servizi di indicizzazione, per poi riunire tutto alla fine.
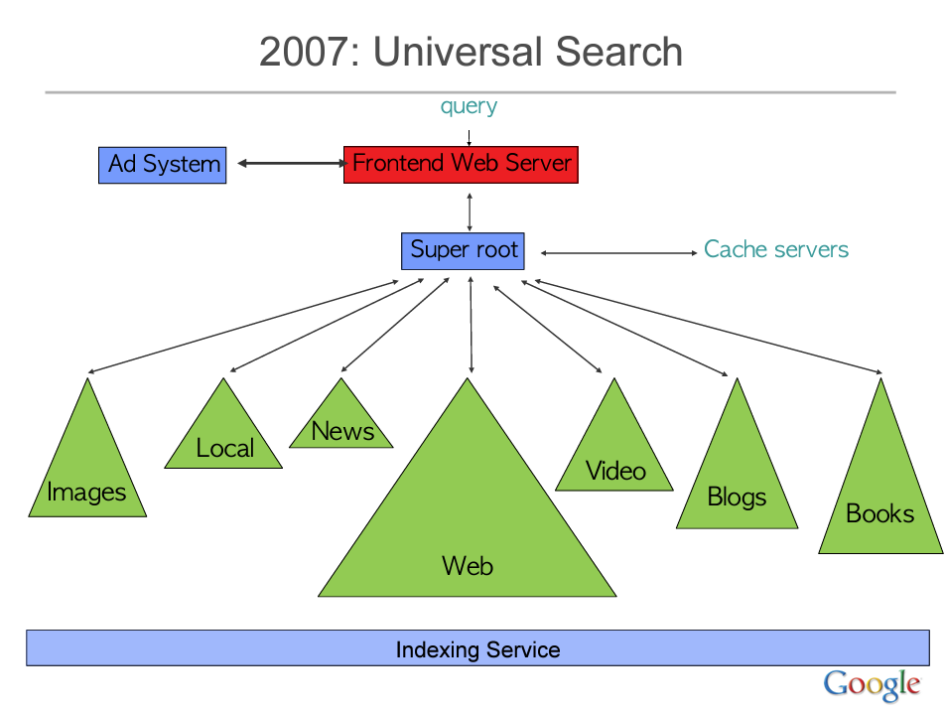
Questa architettura modulare permette a Google di gestire in modo efficiente la complessità del suo sistema di ricerca, consentendo una scalabilità praticamente infinita. Super Root funge da coordinatore centrale, assicurando che ogni componente lavori in sinergia per fornire i risultati di ricerca più pertinenti e accurati.
- Twiddlers: funzioni di reranking
Un altro aspetto cruciale emerso dai documenti trapelati è il ruolo dei Twiddlers. Questi sono funzioni di reranking che operano dopo l’algoritmo di ricerca primario, noto come Ascorer. I Twiddlers funzionano in modo simile ai filtri e alle azioni in WordPress, dove ciò che viene visualizzato viene regolato proprio prima di essere presentato all’utente. Essi possono modificare il punteggio di recupero delle informazioni di un documento o cambiare il ranking di un documento.
I Twiddlers sono utilizzati per implementare molti degli esperimenti live e dei sistemi nominati che conosciamo. Ad esempio, un ex ingegnere di Google ha raccontato di aver disabilitato i Twiddlers nel servizio Super Root, causando un’interruzione della ricerca su YouTube per alcune ore, a riprova della centralità di tali Twiddlers per il funzionamento di vari sistemi di Google.
I Twiddlers possono anche offrire vincoli di categoria, promuovendo la diversità limitando specificamente il tipo di risultati. Ad esempio, un Twiddler potrebbe essere configurato per consentire solo tre post di blog in una determinata SERP, chiarendo quando il ranking è una causa persa basata sul formato della pagina.
Quando Google afferma che un aggiornamento come Panda non fa parte dell’algoritmo principale, ciò significa probabilmente che è stato lanciato come un Twiddler, come una funzione di boost o demotion di reranking, e successivamente integrato nella funzione di scoring primaria. Questo è simile alla differenza tra il rendering lato server e il rendering lato client.
Tra i Twiddlers identificati nei documenti trapelati, troviamo:
- NavBoost: Sistema di reranking basato sui log dei clic degli utenti.
- QualityBoost: Sistema che migliora il ranking basato sulla qualità dei contenuti.
- RealTimeBoost: Sistema che adatta il ranking in tempo reale.
- WebImageBoost: Sistema che migliora il ranking delle immagini web.
Questi Twiddlers, come suggeriscono i loro nomi, sono progettati per ottimizzare vari aspetti dei risultati di ricerca, migliorando la pertinenza e la qualità delle informazioni presentate agli utenti.
In sintesi, i documenti trapelati rivelano che il sistema di ranking di Google è una complessa rete di microservizi coordinati da Super Root, con i Twiddlers che giocano un ruolo cruciale nel fine-tuning dei risultati di ricerca. Queste informazioni offrono una nuova prospettiva sulla complessità e la sofisticazione degli algoritmi di Google, evidenziando l’importanza di considerare una vasta gamma di fattori e segnali nel processo di ottimizzazione per i motori di ricerca.
- La relazione tra Chrome e la SEO
I documenti trapelati dal Content API Warehouse di Google hanno rivelato dettagli sorprendenti sulla relazione tra il browser Chrome e la SEO, sollevando nuove questioni su come Google utilizza i dati di navigazione per influenzare il ranking dei risultati di ricerca.
In particolare, una delle scoperte più rilevanti è che Google utilizza i dati di clickstream raccolti tramite il browser Chrome per calcolare metriche che influenzano il ranking delle pagine web. I documenti suggeriscono che Google raccoglie informazioni dettagliate sui clic degli utenti, inclusi il numero di clic su pagine specifiche e la durata dei clic. Questi dati sono utilizzati per determinare le URL più popolari e importanti di un sito, influenzando così il posizionamento nei risultati di ricerca.
I Google leaks fanno riferimento a metriche di engagement degli utenti come “goodClicks” e “badClicks”, che sono legate a sistemi chiamati Navboost e Glue. Queste metriche riflettono il comportamento reale degli utenti e la loro soddisfazione con i risultati di ricerca. Ad esempio, un “goodClick” potrebbe indicare che un utente ha trovato utile il contenuto di una pagina e ha trascorso del tempo su di essa, mentre un “badClick” potrebbe indicare che l’utente ha rapidamente abbandonato la pagina, insoddisfatto del contenuto. Google utilizza queste informazioni per affinare il ranking delle pagine, premiando quelle che offrono una migliore esperienza utente. E ciò riabilita in certi sensi anche l’analisi di comportamenti come il pogo-sticking (ovvero quando un utente clicca su un risultato e poi clicca rapidamente sul pulsante indietro, insoddisfatto della risposta trovata) e le impressioni.
Infine, i dati di Chrome sono usati anche per determinare i Sitelink, ovvero i link aggiuntivi che appaiono sotto il risultato principale di una ricerca. Google utilizza una metrica chiamata “topUrl”, che rappresenta una lista delle URL più cliccate in Chrome, per determinare quali pagine includere nei Sitelink. Questo implica che le pagine più visitate e popolari di un sito hanno maggiori probabilità di apparire come Sitelink, migliorando la visibilità e l’accessibilità del sito nei risultati di ricerca.
- La sandbox per i siti nuovi o sconosciuti
Sarebbe confermata la presenza di una sandbox, ovvero di un ambiente in cui i siti web vengono segregati in base alla loro giovane età o alla mancanza di segnali di fiducia.
Questo significa che i nuovi siti web o quelli che non hanno ancora accumulato segnali di fiducia sufficienti possono essere temporaneamente limitati nei loro posizionamenti nei risultati di ricerca. La sandbox serve come una sorta di periodo di prova, durante il quale Google valuta la qualità e l’affidabilità del sito prima di permettergli di competere pienamente nei risultati di ricerca.
Quello che i SEO sospettavano: le conferme sui fattori di ranking
Questo leak di Google ci permette anche di avere conferme a “vecchi” sospetti che avevamo da tempo circa il funzionamento di ciò che c’è sotto il cofano di Search.
Non sono infatti delle “novità” queste rivelazioni – che, tra l’altro, sono anche alla base del funzionamento di alcuni degli strumenti principali di SEOZoom!
- Qualità dei contenuti ed esperienza utente
Un’implicazione significativa riguarda l’importanza della qualità dei contenuti e dell’esperienza utente. I documenti confermano che creare contenuti di alta qualità e offrire una buona esperienza utente sono fattori cruciali per ottenere un buon posizionamento nei risultati di ricerca. Questo significa che i professionisti della SEO devono continuare a concentrarsi sulla produzione di contenuti che siano non solo pertinenti e informativi, ma anche coinvolgenti e utili per gli utenti. Inoltre, l’ottimizzazione dell’esperienza utente, come la velocità di caricamento delle pagine e la facilità di navigazione, rimane un elemento chiave per migliorare il ranking.
- Peso dei link e diversità delle fonti
I documenti trapelati confermano che la diversità e la rilevanza dei link rimangono fondamentali per il ranking. Google classifica i link in tre categorie (bassa, media, alta qualità) e utilizza i dati di clic per determinare a quale categoria appartiene un documento. I link di alta qualità possono trasmettere segnali di ranking, mentre quelli di bassa qualità sono ignorati. Questo implica che le strategie di link building devono concentrarsi sulla qualità e sulla diversità dei link, piuttosto che sulla quantità.
- Ruolo delle entità e autorevolezza degli autori
Google memorizza informazioni sugli autori associati ai contenuti e cerca di determinare se un’entità è l’autore di un documento. Inoltre, Google misura le entities per “fama” usando i clic e i link.
Questo indica che Google attribuisce grande importanza all’autorevolezza e alla credibilità degli autori, utilizzando queste informazioni per migliorare la pertinenza e la qualità dei risultati di ricerca. I professionisti della SEO devono quindi lavorare per costruire e mantenere la loro autorevolezza e credibilità nel loro settore, attraverso la produzione di contenuti di alta qualità e la partecipazione attiva nelle comunità online. Tutto questo sembra suggerire un collegamento diretto con il concetto di E-E-A-T, in particolare per gli aspetti di Fiducia e Autorevolezza, e implica che l’autorevolezza del dominio e dell’autore possono influenzare in maniera significativa il posizionamento di un contenuto.
- Peso del Brand (e vantaggi dei domini scaduti)
I documenti rivelano anche l’importanza della storia del brand e dei domini scaduti. Google tiene conto della storia di un dominio e del brand associato quando valuta la sua autorità e pertinenza, utilizzando segnali consolidati per valutare questi aspetti.
Questo approccio – correlato evidentemente alla sandbox – avvantaggia i siti più vecchi e consolidati, che hanno una lunga storia di contenuti di alta qualità e un brand riconosciuto.
La storia del brand si riferisce alla longevità e alla reputazione di un marchio nel tempo: Google tiene conto di quanto tempo un brand è stato attivo online, della qualità dei contenuti che ha prodotto e della sua riconoscibilità nel settore. Un brand con una lunga storia di contenuti di alta qualità e una forte presenza online è considerato più affidabile e autorevole rispetto a un brand nuovo o meno conosciuto.
Questo significa che i siti web associati a brand consolidati tendono a ottenere un miglior posizionamento nei risultati di ricerca. Google premia la continuità e la coerenza, valutando positivamente i siti che hanno dimostrato di mantenere un alto standard di qualità nel tempo. Questo approccio favorisce i brand che hanno investito nella costruzione di una solida reputazione e nella produzione di contenuti di valore per gli utenti – che è quello che abbiamo notato anche con il nostro recente studio sul posizionamento, che partiva empiricamente dal veder emergere sempre gli stessi siti ai primi posti su Google.
Inoltre, Google utilizza segnali consolidati a livello di homepage per valutare l’autorità di un sito. La homepage di un sito è spesso considerata la pagina più importante e autorevole, e i segnali associati ad essa, come il PageRank e la qualità dei link in entrata, influenzano il ranking dell’intero sito. Questo significa che i siti più vecchi, che hanno avuto più tempo per accumulare link di alta qualità e costruire una solida reputazione, sono avvantaggiati rispetto ai siti nuovi.
Altra implicazione di questa situazione riguarda la pratica dell’acquisto e restyling di domini scaduti. Quando un dominio scade e viene riacquistato, la sua storia precedente può infatti influenzare il suo ranking nei risultati di ricerca. Se un dominio ha una storia di contenuti di alta qualità e link autorevoli, questi segnali possono essere mantenuti anche dopo la scadenza e il riacquisto del dominio. Tuttavia, se il dominio ha una storia di contenuti di bassa qualità o pratiche di spam, questi segnali negativi possono penalizzare il nuovo proprietario.
- Importanza dei link
Nonostante le numerose evoluzioni degli algoritmi di ricerca, i link continuano a giocare un ruolo cruciale nel determinare l’autorità e la pertinenza di una pagina. In particolare, la diversità dei link, ovvero la varietà delle fonti che puntano a una pagina, è un indicatore chiave della sua autorevolezza. Un sito che riceve link da una vasta gamma di fonti affidabili è considerato più autorevole rispetto a un sito che riceve link da poche fonti, magari poco rilevanti.
Il concetto di PageRank, introdotto da Google nei suoi primi anni, è ancora molto vivo e rilevante. Il PageRank misura l’importanza di una pagina in base al numero e alla qualità dei link che riceve. Anche se Google ha introdotto molti altri fattori di ranking nel corso degli anni, il PageRank rimane un pilastro fondamentale del suo algoritmo. I documenti trapelati suggeriscono che il PageRank della homepage di un sito è considerato per ogni documento del sito, il che sottolinea l’importanza di avere una homepage forte e ben collegata.
- Metriche di engagement degli utenti
Google usa metriche di engagement degli utenti per influenzare il ranking delle pagine. In particolare, vengono citate “goodClicks” e “badClicks”, che servono a valutare la qualità dell’esperienza utente su una pagina. “GoodClicks” si riferisce ai clic che indicano un’interazione positiva con il contenuto, come un lungo tempo di permanenza sulla pagina o ulteriori clic all’interno del sito. Al contrario, “badClicks” si riferisce ai clic che indicano un’interazione negativa, come un rapido ritorno alla pagina dei risultati di ricerca o un bounce rate elevato.
Queste metriche di engagement sono cruciali perché riflettono il comportamento reale degli utenti e la loro soddisfazione con i risultati di ricerca. Google utilizza queste informazioni per affinare il ranking delle pagine, premiando quelle che offrono una migliore esperienza utente. Ad esempio, una pagina che riceve molti “goodClicks” è considerata più utile e pertinente, e quindi può essere posizionata più in alto nei risultati di ricerca. Al contrario, una pagina con molti “badClicks” può essere penalizzata.
L’uso delle metriche di engagement degli utenti rappresenta un’evoluzione significativa rispetto ai tradizionali fattori di ranking basati sui contenuti e sui link. Riflette l’approccio di Google orientato all’utente, che mira a fornire i risultati di ricerca più utili e pertinenti. Tuttavia, solleva anche questioni sulla trasparenza e sulla privacy, poiché implica la raccolta e l’analisi di dati dettagliati sul comportamento degli utenti.
Le reazioni della community SEO: preoccupazione, delusione, rabbia!
Questo Google leak ha scatenato una tempesta di reazioni nella comunità SEO, portando a sentimenti di delusione, preoccupazione e rabbia, alimentati principalmente dalle discrepanze tra le dichiarazioni ufficiali di Google fornite negli anni e le informazioni rivelate dai documenti trapelati.
Per anni, infatti, Google ha sostenuto pubblicamente che alcuni dati, come i clic degli utenti e i dati raccolti tramite il browser Chrome, non venivano utilizzati direttamente nei suoi algoritmi di ranking. Tuttavia, la fuga di informazioni contraddice queste affermazioni. Ciò è stato confermato anche dall’audizione federale del VP di Google Pandu Nayak, che ha ammesso che “goodClicks” e “badClicks” fanno effettivamente parte dei sistemi di ranking di Google. Inoltre, allargando il quadro, l’uso dei dati di Chrome per influenzare il ranking solleva anche questioni sulla trasparenza e la privacy.
Questa discrepanza solleva dubbi sulla trasparenza di Google e sulla veridicità delle sue dichiarazioni pubbliche, che hanno spesso minimizzato o negato l’importanza di certi segnali di ranking (portando molti SEO a basare le loro strategie su informazioni incomplete o fuorvianti).
Molti professionisti si sentono quindi traditi da Google, che continua a perdere fiducia e stima soprattutto per quanto riguarda la trasparenza e l’integrità dei suoi meccanismi, praticamente ai minimi storici. Tutto questo è amplificato anche dalla percezione che Google stia utilizzando il lavoro dei creatori di contenuto per migliorare i propri servizi senza riconoscere adeguatamente il loro contributo, come avviene con l’introduzione di AI Overview.
E la risposta di Google non aiuta certo ad azzerare le preoccupazioni sulla trasparenza e l’affidabilità delle informazioni fornite dall’azienda – né tutto può essere ridotto al messaggio “non commentiamo gli elementi specifici del documento, al fine di mantenere il sistema di ranking sicuro e protetto”.
Cosa significa per la SEO: come cambiano le strategie?
Questa situazione ha inevitabilmente portato a un dibattito acceso nella comunità SEO su come interpretare e utilizzare le informazioni trapelate – e addirittura a uno scontro tra la denominazione di questo caso, visto che c’è anche chi contesta l’espressione “Google leak” parlando più propriamente di “documenti rivelati” o scovati.
In linea di massima, alcuni esperti suggeriscono di prendere le rivelazioni con cautela, altri vedono in esse una conferma delle loro teorie di lunga data, all’insegna del “Io l’avevo detto”. In ogni caso, la fuga di notizie ha messo in luce i limiti di trasparenza da parte di Google, soprattutto per la smentita delle precedenti dichiarazioni ufficiali.
Rand Fishkin e Michael King, che hanno dato il via all’analisi dei documenti trapelati, hanno messo in luce alcuni aspetti utili per le strategie SEO che derivano da questi documenti.
In particolare, Fishkin ha evidenziato come la memorizzazione delle versioni delle pagine e l’uso dei dati di Chrome rappresentino aspetti cruciali per comprendere il funzionamento degli algoritmi di Google. Per Rand, “il Brand Conta Più di Ogni Altra Cosa”: Google ha numerosi modi per identificare, ordinare, classificare, filtrare e utilizzare le entità, che includono i brand (nomi di marchi, i loro siti web ufficiali, account social associati, ecc.), e come abbiamo visto nella nostra ricerca Google sta seguendo un percorso inesorabile verso il ranking esclusivo e l’invio di traffico ai grandi marchi potenti che dominano il web, a discapito dei siti piccoli e indipendenti.
Inoltre, sembra che contenuti e link siano secondari rispetto ai fattori dell’intenzione dell’utente. I fattori di ranking classici come PageRank, anchor text (PageRank tematico basato sul testo di ancoraggio del link) e text-matching hanno perso importanza negli anni – anche se i titoli delle pagine rimangono ancora piuttosto importanti – rispetto al search intent. Google è sempre più orientato a comprendere cosa gli utenti vogliono realmente trovare e a fornire risultati che soddisfino queste intenzioni. Pertanto, è cruciale creare contenuti che non solo siano ottimizzati per i motori di ricerca, ma che rispondano anche alle reali esigenze e intenzioni degli utenti.
Inoltre, questi leak sembrano suggerire che la SEO può rappresentare una sfida significativa soprattutto per le piccole e medie imprese e i nuovi creatori/editori: fino a quando un sito non riesce a costruire una forte credibilità, una domanda di navigazione e una reputazione solida tra un pubblico ampio, è probabile che veda scarsi risultati dai suoi sforzi di ottimizzazione. Questo significa che, oltre a concentrarsi sulle tecniche SEO tradizionali, queste imprese devono investire nella costruzione del loro brand e nella creazione di contenuti di alta qualità che attraggano e coinvolgano gli utenti.
Come sintetizza Fishkin, il miglior consiglio universale “ai marketer che cercano di migliorare ampiamente i loro ranking di ricerca organica e il traffico” è: “Costruisci un brand noto, popolare e ben riconosciuto nel tuo settore, al di fuori della ricerca su Google”.
King, d’altra parte, ha sottolineato l’importanza delle metriche di engagement degli utenti, come “goodClicks” e “badClicks”, nel determinare il ranking delle pagine. Entrambi concordano sul fatto che, nonostante le nuove informazioni, i principi fondamentali della SEO rimangono invariati: creare contenuti di alta qualità e offrire una buona esperienza utente.
Lily Ray di Amsive ha invitato invece alla calma. Per lei, il leak “è interessante da approfondire, ma ci sono troppe incognite riguardo alle informazioni trapelate per prendere decisioni sulla SEO. Non sappiamo se gli attributi elencati nella fuga siano effettivi fattori di ranking, o in che misura siano attualmente utilizzati, se lo sono”. Ad ogni modo, “vale la pena esplorare le informazioni, poiché rivelano almeno alcune convenzioni di denominazione interessanti che Google utilizza per la sua documentazione API interna, inclusi molti termini di cui i SEO hanno discusso e dibattuto per anni”.
Il suo consiglio per i brand è comunque di non perder troppo tempo ad analizzare documenti tecnici, ma piuttosto “concentrarsi sull’assicurarsi che le loro pratiche SEO di base siano solide, come garantire che i contenuti corrispondano all’intento di ricerca, includere parole chiave e immagini, collegare internamente e costruire URL forti”.
Ryan Jones è stato uno dei primi a consigliare cautela, invitando le persone a valutare le informazioni in modo obiettivo e senza preconcetti. L’ex Googler Pedro Dias è sulla stessa linea. Per lui “non c’è nulla di peggio delle informazioni senza contesto” e può essere pericoloso saltare a conclusioni affrettate dai dati senza considerare tutte le possibilità. Per questo, ha evitato di commentare specifici elementi proprio a causa dell’assenza di contesto e della difficoltà di interpretazione, aggiungendo che l’impatto di questa fuga alimenta teorie complottistiche e interpretazioni semplicistiche della Ricerca. Dean Cruddance ha affermato che non c’è nulla nei documenti che sveli i segreti dell’algoritmo di Google.
Tra le fonti più scettiche c’è Search Engine Journal, che ha riportato che non ci sono prove concrete che i dati trapelati siano effettivamente di Google Search e che non siano in alcun modo correlati al ranking dei siti web. Molti SEO hanno infine concordato che le informazioni non rappresentano un dump di dati dell’algoritmo.
