
Ricerca semantica, la chiave della SEO moderna
Se ne parla da oltre quindici anni e, come svelato dal compianto Bill Slawski, i primi brevetti di Google in questa direzione risalgono addirittura al 1999: è però solo negli ultimi tempi che la ricerca semantica, o semantic search per dirla all’inglese, è diventata davvero una realtà quotidiana, grazie agli sviluppi della tecnologia e alle applicazioni di Intelligenza Artificiale e machine learning. In qualche modo, se la SEO è ancora l’arte e la scienza di ottimizzare i contenuti online per migliorare la visibilità nei motori di ricerca, molto dipende anche da questa “sottocategoria” che ha spinto i motori di ricerca a concentrarsi sulla comprensione più profonda del significato dietro le parole chiave e le frasi di ricerca, piuttosto che esclusivamente sulla corrispondenza esatta delle parole chiave. Andiamo a scoprire cosa si intende esattamente con ricerca semantica e che tipo di impatto ha sulla SEO.
Che cos’è la ricerca semantica
La ricerca semantica è il processo che i motori di ricerca utilizzano per cercare di comprendere l’intento e il significato contestuale della query di ricerca, con l’obiettivo di fornire risultati che siano accurati, pertinenti e rilevanti, ovvero che corrispondano a ciò che l’utente aveva in mente. In altre parole, la ricerca semantica mira a conoscere il motivo per cui una persona sta cercando quella particolare stringa di termini nella query e che cosa intende fare con le informazioni ottenute.
Per raggiungere questo obiettivo, i motori di ricerca analizzano vari elementi, come il contesto di ricerca, l’ubicazione geografica dell’utente, la variazione delle parole, sinonimi, interrogazioni generalizzate e specializzate, riscontro di concetti, interrogazioni in linguaggio naturale, ma anche la relazione tra le parole e la comprensione delle entità sottese. Proprio questo concetto, entità, è uno dei fulcri per la ricerca semantica di Google: in estrema sintesi, il termine descrive l’essenza o l’identità di un oggetto concreto o astratto, è qualcosa di univocamente identificabile e quindi univocamente significativo.
Alla base dell’evoluzione della ricerca semantica ci sono una serie di valutazioni, ma soprattutto la considerazione sul fatto che le query di ricerca possono essere di natura ambigua, così come le stesse parole; inoltre, le persone parlano e chiedono cose in modi, lingue e toni diversi, che non possono (più) essere uniformati con SERP standard che considerano solo il vecchio exact match.
È importante notare che non dobbiamo confondere la ricerca semantica con l’indicizzazione semantica latente (LSI) o quelle che alcuni potrebbero chiamare parole chiave semanticamente correlate: le LSI possono aiutare a fornire un contesto sull’argomento del contenuto (e potenzialmente aiutare a far corrispondere l’intento di ricerca), ma la ricerca semantica è molto di più (e le LSI non aiutano il ranking, come ribadito in varie circostanze da Google).
Una guida alla SEO semantica
La SEO semantica si riferisce all’uso di tecniche SEO che si concentrano sul significato e l’intento dell’utente dietro una determinata query di ricerca, piuttosto che sulla corrispondenza esatta delle parole chiave. Questo approccio si basa sulla comprensione del contesto in cui le parole chiave vengono utilizzate, piuttosto che sulla loro semplice presenza in un contenuto.
Per esempio, se un utente cerca “apple” potrebbe riferirsi al frutto, all’azienda di tecnologia o a una serie di altre cose: un motore di ricerca che utilizza la SEO semantica cercherà di capire l’intento dell’utente dietro questa ricerca, basandosi su una serie di fattori come la posizione dell’utente, le ricerche precedenti e altri dati contestuali.
In estrema sintesi, la SEO semantica consente ai motori di ricerca di fornire risultati più pertinenti e utili, migliorando l’esperienza dell’utente e aumentando la probabilità che l’utente trovi esattamente ciò che sta cercando.
Cosa significa semantica nel contesto della ricerca
L’espressione “ricerca semantica” fa riferimento alla branca della linguistica chiamata appunto semantica, che studia il significato di parole e frasi (del linguaggio in generale) in determinati contesti e la relazione tra quelle parole.
Applicata alla ricerca web, semantica si riferisce alla connessione tra una query di ricerca, le parole a essa correlate e il contenuto delle pagine del sito web; tutti questi elementi, combinati, aiutano i motori di ricerca a capire cosa significano le query di ricerca al di là di una semplice traduzione letterale, in modo da fornire risultati effettivamente correlati al contesto.
Significato però non è sinonimo di intenzione, e quindi la ricerca semantica non può essere semplicisticamente intesa come interpretazione dell’intento di ricerca: come sottolinea Olaf Kopp, alla sua essenza la ricerca semantica consiste nel riconoscere il significato delle query di ricerca e dei contenuti in base alle entità presenti. Ciò si lega, appunto, alla definizione di semantica come “teoria del significato“, e in questo ambito “significato” è qualcosa di diverso da intento di ricerca – espressione che, come sappiamo, descrive il motivo per cui una persona ha eseguito una ricerca e, contemporaneamente, anche ciò si aspetta dai risultati della ricerca – che può aiutare a riconoscere l’intento e diventa una sorta di vantaggio aggiuntivo della ricerca semantica.
Provando a semplificare, pensiamo alla nostra esperienza quotidiana: quando le persone si parlano, capiscono (spesso automaticamente e senza badarci) più delle semplici parole, perché capiscono il contesto, i segnali non verbali (come espressioni facciali o sfumature della voce) e molto altro ancora. Tutto ciò avviene in modo naturale, quindi non è semplice fare un passo indietro per descrivere ciò che viene comunicato senza l’aiuto di tutti i segnali “oltre le parole”.
Come funzionano i motori di ricerca semantici
Con i motori di ricerca, questo significa passare dalla mera identificazione della query alla comprensione da parte degli algoritmi di ciò che c’è dietro: ad esempio, se cerchiamo “abiti da sposa”, le parole correlate potrebbero includere “matrimonio”, “torta”, “sposa” e “sogno”, mentre se cerchiamo solo “abiti” le parole correlate potrebbero essere “eleganti”, “casual”, “lunghi” e così via.
Pertanto, un motore di ricerca semantico considera il contesto semantico delle query di ricerca e dei contenuti per comprenderne meglio il significato, riuscendo anche ad analizzare e valutare le relazioni tra le entità per restituire i risultati della ricerca. Ciò rappresenta una evidente evoluzione rispetto ai precedenti sistemi di ricerca puramente basati su parole chiave, che invece funzionano ricercando soltanto una corrispondenza tra parole chiave e testo.
I più moderni algoritmi semantici riescono a creare un modello matematico che può individuare un “punteggio di pertinenza di un determinato documento per qualsiasi query di ricerca dell’utente”, come diceva già alcuni anni fa il nostro Ivano Di Biasi; tali algoritmi vengono utilizzati per la ricerca in documenti riguardanti un settore specifico e riescono a garantire funzionalità di ricerca verticale su un settore, anche se ha un numero ridotto di argomenti/topic.
Sempre più spesso, oggi il motore di ricerca analizza il campo semantico di ciascuna parola, tentando di individuare tutte le altre parole pertinenti con la query: è ciò che si chiama espansione del campo semantico, che consente all’algoritmo di riconoscere che singolare e plurale non sono due query diverse (a parte eccezioni speciali, legate agli intenti) e che alcuni verbi hanno lo stesso significato.
La ricerca semantica consente inoltre ai motori di ricerca di distinguere tra diverse entità (persone, luoghi e cose) e interpretare l’intento del ricercatore in base a una varietà di fattori, tra cui cronologia delle ricerche degli utenti, posizione geografica, cronologia delle ricerche globale e variazioni ortografiche. Tutto ciò aiuta Google e gli altri search engines a fornire un’esperienza migliore ai propri utenti, offrendo qualità e dando la preferenza ai risultati di contenuti pertinenti.
L’evoluzione dei search engines
Questo processo si è reso inevitabile per assecondare le crescenti esigenze degli utenti, insoddisfatti dalla tipologia di risposte fornite in precedenza dalle varie SERP costruite su modelli non-semantici.
In precedenza, i motori di ricerca standard lavoravano concentrandosi sulle keyword: ovvero, la loro scansione partiva dall’analisi dell’input fornito dall’utente nella barra ricerca (la query, composta da una o più parole chiave), per ricercare la sua specifica occorrenza all’interno dei documenti presenti nell’indice e, sulla base di una serie di fattori di ranking (compresa, all’epoca, la frequenza con cui la query si ripeteva all’interno del documento), fornire in risposta una SERP con risultati ordinati appunto secondo particolari criteri.
Tutti i documenti elencati – le pagine web – avevano quindi una caratteristica in comune: contenere al loro interno la parola chiave o la stringa indicata dall’utente nella query di ricerca, preferibilmente in formato perfettamente identico alla formulazione dell’input. È quello che si chiama exact matching, ovvero coincidenza letterale con la parola chiave (per quanto sgrammaticata o errata).
Elemento ancora più importante, nella ricerca classica ogni parola è indipendente da tutte le altre, perché gli algoritmi non sono in grado di comprendere elementi quali sinonimi, forme di genere, variazione di singolare o plurale della stessa parola, e spesso escludono alcuni termini dalla ricerca (le classiche stop-word, come articoli o preposizioni). Pertanto, anche query sostanzialmente identiche (secondo la sensibilità attuale) del tipo “come fare siti web”, “come fare un sito web” o “come realizzare siti web” producevano SERP completamente differenti, valutate sulla base delle occorrenze della stringa esatta di termini all’interno del contenuto (e degli altri criteri di ranking dell’algoritmo).
Una mappatura di entità e concetti
Alla base c’è sempre lo stesso problema che muove anche i broad core update e gli altri interventi: Google, insieme agli altri motori di ricerca, sta cercando di (e spesso lotta per) capire cosa vogliono i suoi utenti, senza vederli o ascoltarli effettivamente, con l’obiettivo di soddisfare le ricerche con risultati più accurati. Ed proprio qui che entra in gioco la ricerca semantica, che collega l’intento di ricerca con il contesto dei contenuti per fornire i risultati più rilevanti e utili, rendendo qualsiasi argomento (o query di ricerca) facile da capire per una macchina.
Senza entrare troppo in dettagli tecnici (per cui servirebbero professionisti di analisi semantica), alla base della ricerca semantica per i motori ci sono due concetti principali, come ci spiega Ann Smarty:
- Mappatura semantica, che significa esplorare le connessioni tra qualsiasi parola/frase e un insieme di parole o concetti correlati.
- Codifica semantica, ovvero utilizzare la codifica per spiegare meglio a Google quali tipi di informazioni si possono trovare in ogni pagina.
Più precisamente, la mappatura semantica riguarda la visualizzazione delle relazioni tra concetti ed entità (così come le relazioni tra concetti ed entità correlati), e questa immagine ci fa comprendere la rappresentazione grafica del modello così come pensata da Ramanathan Guha di Google, futuro creatore del progetto Schema.

Questo modello aiuta Google a comprendere meglio qualsiasi query correlata e fornisce utili spunti di ricerca (come grafico della conoscenza, risposte rapide e altri). L’analisi semantica aiuta anche Google a servire meglio gli utenti della ricerca vocale, fornendo loro risposte immediate basate sulla loro comprensione generica di un argomento.
Le nuove risposte dei motori di ricerca e la codifica semantica
Un grande supporto all’evoluzione dei motori di ricerca semantici arriva quindi dal progetto Schema.org, creato nel 2011, che ha offerto ai proprietari di siti ancora più modi per trasmettere il significato di un documento (e delle sue diverse parti) a una macchina. Da quel momento in poi, il sito è stato capace di comunicare direttamente a un crawler di ricerca informazioni sull’autore della pagina, sul tipo di contenuto (articolo, FAQ, recensione e altre pagine simili) e sul suo scopo (verifica dei fatti, dettagli di contatto e altro).
È ancora Smarty a dire in maniera molto incisiva che “il markup semantico esiste per un motivo, il desiderio di comunicare”, perché noi vogliamo spiegare lo scopo e la struttura dei nostri contenuti a un motore di ricerca.
Con l’aiuto del markup semantico, Google è in grado di identificare e utilizzare le informazioni chiave da una pagina; in cambio, per così dire, gli editori web ottengono “rich snippet“, ovvero elenchi di ricerca più dettagliati di quelli che non utilizzano la semantica, e miglior comprensione della risorsa.
In realtà, l’idea alla base dell’utilizzo del codice per esprimere il significato (non solo la presentazione) risale a molto prima del lancio del progetto schema.org, e da anni possiamo usare il cosiddetto HTML semantico per comunicare il significato dei contenuti, e in particolare gli heading H1-H6 che descrivono gli argomenti principali di un documento e gli altri tag HTML, che aiutano tutti i tipi di macchine a comprendere e trasmettere meglio le informazioni che trovano su una pagina web (e che infatti sono anche chiamati tag semantici perché aggiungono significato a un documento).
Che cos’è la SEO semantica
Come e quanto tutto questo impatta sul lavoro di ottimizzazione per i motori di ricerca e, quindi, che cos’è la SEO semantica? Innanzitutto, dobbiamo ricordare che la SEO è e resta essenzialmente una serie di interventi che mirano a spiegare meglio lo scopo e la struttura del nostro contenuto a un motore di ricerca (oltre che rendere semplice la navigazione e la comprensione dell’utente, accompagnandolo a eseguire lo scopo che aveva in mente), ma oggi ciò si arricchisce di ulteriori livelli di analisi, per comprendere l’intento e il comportamento delle persone, così come il contesto (semantico) che c’è dietro le espressioni testuali e le parole.
Possiamo quindi dire che siamo pienamente all’interno dell’era della SEO semantica, perché, per citare ancora Slawski, la ricerca sul Web si è evoluta per concentrarsi maggiormente sulla visualizzazione di risultati che trovano elementi e non stringhe (things instead of strings) o corrispondenza di parole chiave all’interno di query con le parole chiave nei documenti sul Web.
I principali motori di ricerca – Google, Bing, Yahoo e Yandex, tra gli altri – seguono tutti i markup dei dati strutturati di schema.org, che possono essere utilizzati per mostrare risultati multimediali nei risultati di ricerca. È (anche) questo che rende visibile la ricerca semantica: oggi nelle SERP vediamo risultati SEO semantici come snippet in primo piano, risultati multimediali, risultati strutturati, pannelli di conoscenza, sostituzione di sinonimi ed elaborazione di query speciali di entità. Inoltre, la SEO semantica implica anche l’inclusione di fatti o attributi di entità nelle pagine, e possiamo anche identificare la classe di entità, collegarci alle informazioni su quell’entità e alle informazioni che le persone dovrebbero conoscere su tali entità – ciò che alimenta la valutazione di E-A-T per Google, volendo semplificare.
Dal punto di vista pratico, la SEO semantica è il processo di utilizzo di argomenti ed entità correlati per aiutare i motori di ricerca a comprendere meglio i contenuti del sito, e aiuta a fornire ai motori di ricerca più contesto su una determinata pagina, rendendo il contenuto più completo. Una pagina dei risultati di ricerca SEO semantica può includere:
- Knowledge panels.
- Caroselli di ricerca pieni di entità.
- Featured snippets che possono rispondere a domande sulle entità in una query.
- Domande correlate (box di domande “People also ask” che potrebbero essere simili alle risposte dello snippet in primo piano).
- Entità correlate
e altro ancora.
Come ottimizzare i contenuti per la SEO semantica
La SEO Semantica come disciplina si è diffusa sempre più nel corso degli ultimi anni, anche se prevalentemente lo studio e le ottimizzazioni hanno riguardato piuttosto il copywriting, oggi sempre più inteso come “copy strategico” in un’ottica olistica che riunisce anche interventi più ampi sulla pagina.
In effetti, nei discorsi sulla SEO semantica rientrano spesso l’ottimizzazione semantica dei contenuti, ma anche l’uso dei dati strutturati e la struttura dei mondi topici semantici, e sostanzialmente “ha senso mostrare a Google che con i vostri contenuti coprite completamente determinati argomenti e, quindi, dimostrate competenza”, come sintetizza ancora Kopp.
Inoltre, alcuni brevetti di Mountain View riguardano il confronto tra i grafi di conoscenza interni dei documenti e il Google Knowledge Graph di Google, e la teoria che sembra sottostare è che un alto livello di corrispondenza tra le entità utilizzate in un testo e le strutture di relazione dell’entità principale nel database semantico di Google porti a migliori classifiche. Ciò sembrerebbe anche logico, ma in fondo attualmente l’ottimizzazione basata sulle parole chiave non differisce in modo significativo dall’ottimizzazione dei contenuti basata sulle entità.
Allo stesso tempo, l’esperto sostiene che anche la struttura dei mondi topici ha senso, anche se va detto che, in tempi di passage ranking, non possiamo trascurare aspetti quali l’effettivo livello di suddivisione di un tema in vari sottotemi e la gestione stessa del topic (ovvero, se sono prodotti contenuti separati per ogni sottotema o se, al contrario, viene creato solo un contenuto globale).
In modo simile, oggi i dati strutturati possono aiutare Google a comprendere le relazioni semantiche, ma solo fino a quando il motore di ricerca non ne avrà più bisogno – e questo avverrà presto, prevede lo stesso Kopp, perché “Google è talmente bravo nell’apprendimento automatico che utilizza i dati strutturati per addestrare gli algoritmi più velocemente”.
È quindi solo questione di tempo prima che Google non abbia più bisogno dei dati strutturati, mentre diverso è il discorso sulle “relazioni” e sulla visione globale delle entità come editori e autori. Qui giocano un ruolo più i segnali off-page che quelli on-page: in base alle relazioni tra entità autorevoli e credibili, Google vuole determinare quali domini e autori sono le migliori fonti di qualità per un argomento secondo l’E-A-T, e in particolare comprendere
- Chi è collegato a chi.
- Chi raccomanda chi.
- Chi frequenta chi.
I link e le co-occorrenze di Google possono essere utilizzati come fattori di prossimità tra entità autorevoli, e la SEO semantica dovrebbe prendere in considerazione anche la loro ottimizzazione.
A proposito di co-occorrenze, prosegue l’autore, è bene considerare anche il funzionamento dell’NLP (Natural Language Processing o elaborazione del linguaggio naturale) nell’ottimizzazione dei contenuti: Google utilizza la NPL per identificare le entità e il loro contesto, attraverso strutture grammaticali di frasi, triple (espressioni formate da soggetto->predicato->oggetto) e tuple (elementi di una relazione con attributi in un database relazionale) composte da nomi e verbi.
Per questo motivo, anche nella SEO semantica dovremmo prestare attenzione a una struttura grammaticale semplice delle frasi, e quindi usare frasi brevi, senza pronomi personali e senza annidamenti: in questo modo si rende un servizio in termini di leggibilità agli utenti e ai motori di ricerca.
Passando alla fase di keyword research, invece, quando studiamo le parole chiave da inserire nei contenuti non dobbiamo fissarci su un singolo termine, ma analizzare e creare i cosiddetti “cluster di parole chiave“, o gruppi di parole chiave correlate, che siano direttamente correlati alla ricerca semantica, perché assicurano che i nostri contenuti coprano una gamma più ampia dell’argomento – e, potenzialmente, possono posizionare ampliare il posizionamento, aumentando il numero di parole chiave per pagina riconosciute da Google come utili per il contesto e per l’esigenza dell’utente.
L’idea è che l’utilizzo di tali termini nel copy aiuta a inserire il contenuto nel focus individuato dal modello semantico di Google, che quindi comprende immediatamente che il nostro documento è in linea con l’intento del ricercatore.
Addio alla vecchia SEO
Questo nuovo processo di ricerca di parole chiave, che già tempo fa avevamo sintetizzato nella frase “la keyword non esiste“, dovrebbe essere ormai lo standard dell’attività SEO e segna la grande differenza concettuale che c’è nel lavoro odierno rispetto a quello del passato.
Fino a una decina di anni fa (ma c’è ancora chi ha continuato…) i SEO di tutto il mondo seguivano un processo relativamente simile: nella prima fase, eseguivano la keyword research per trovare il termine potenzialmente più appetibile e le altre parole correlate; successivamente, si inserivano (forzatamente o addirittura casualmente) quelle parole chiave nel testo di una pagina quante più volte possibile, e si lavorava per portare a quella URL il numero massimo possibile di backlink, da qualsiasi tipo di sito referring; infine si aspettava il posizionamento, che poteva anche essere positivo – almeno fino all’introduzione degli algoritmi Panda e Penguin.
La storia della semantic search
Insomma, ciò che stiamo vedendo oggi non è una rivoluzione improvvisa, ma una delle fasi di un processo avviato ormai da tanti anni e che ha dovuto in qualche modo “attendere” gli adeguati sviluppi tecnologici.
Basti pensare che già nel 2001 l’inventore del Web, Tim Berners-Lee, aveva pubblicato una revisione della sua visione originale del Web e iniziato a scrivere sul Web semantico, con un articolo ospitato su Scientific American intitolato proprio “The Semantic Web“, in cui diceva che “il Web Semantico non è un Web separato, ma un’estensione di quello attuale, in cui alle informazioni viene dato un significato ben definito, consentendo ai computer e alle persone di lavorare meglio in cooperazione”.
Semantic Search e Google
Ma quando Google ha iniziato a lavorare sulla SEO semantica? Secondo Bill Slawski, i primi tentativi sono datati 1999 (un anno dopo il brevetto dell’algoritmo PageRank), quando Sergy Brin ha depositato un brevetto provvisorio per un algoritmo chiamato “Dual Iterative Pattern Relation Expansion”, che è il primo passo verso l’evoluzione successiva.
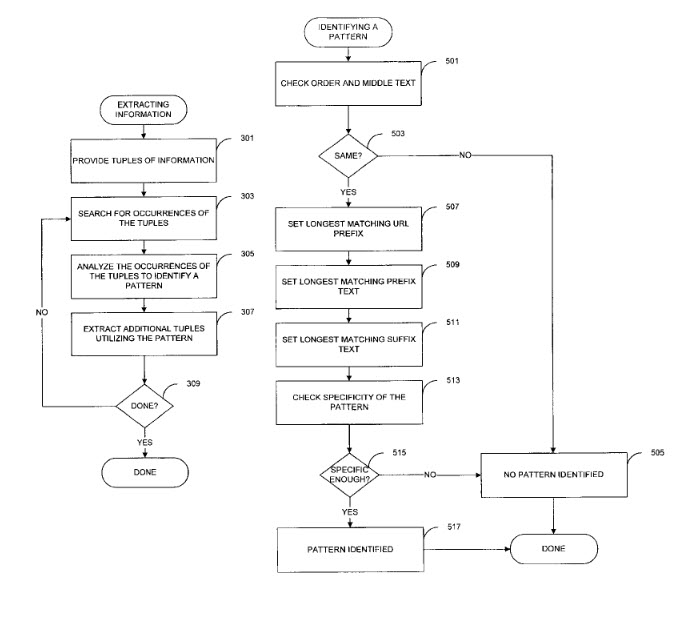
Comprendere la SEO semantica significa anche conoscere le tecnologie e gli approcci di Google per estrarre informazioni sulle entità dal Web, espressi visivamente dai knowledge graph che sono costruiti usando quella tecnologia.
Proprio l’introduzione del Knowledge Graph nel 2012 ha iniziato a concretizzare infatti l’impegno di Google verso un nuovo approccio semantico alla ricerca, seguito l’anno successivo dal fondamentale update del suo algoritmo di ranking, noto come Hummingbird: tutte le altre principali innovazioni successive, come RankBrain, E-E-A-T, BERT e MUM, supportano direttamente o indirettamente l’obiettivo di diventare un motore di ricerca completamente semantico. E oggi, introducendo l’elaborazione del linguaggio naturale (NLP) nella ricerca, Google si sta muovendo a una velocità esponenziale verso questo obiettivo.
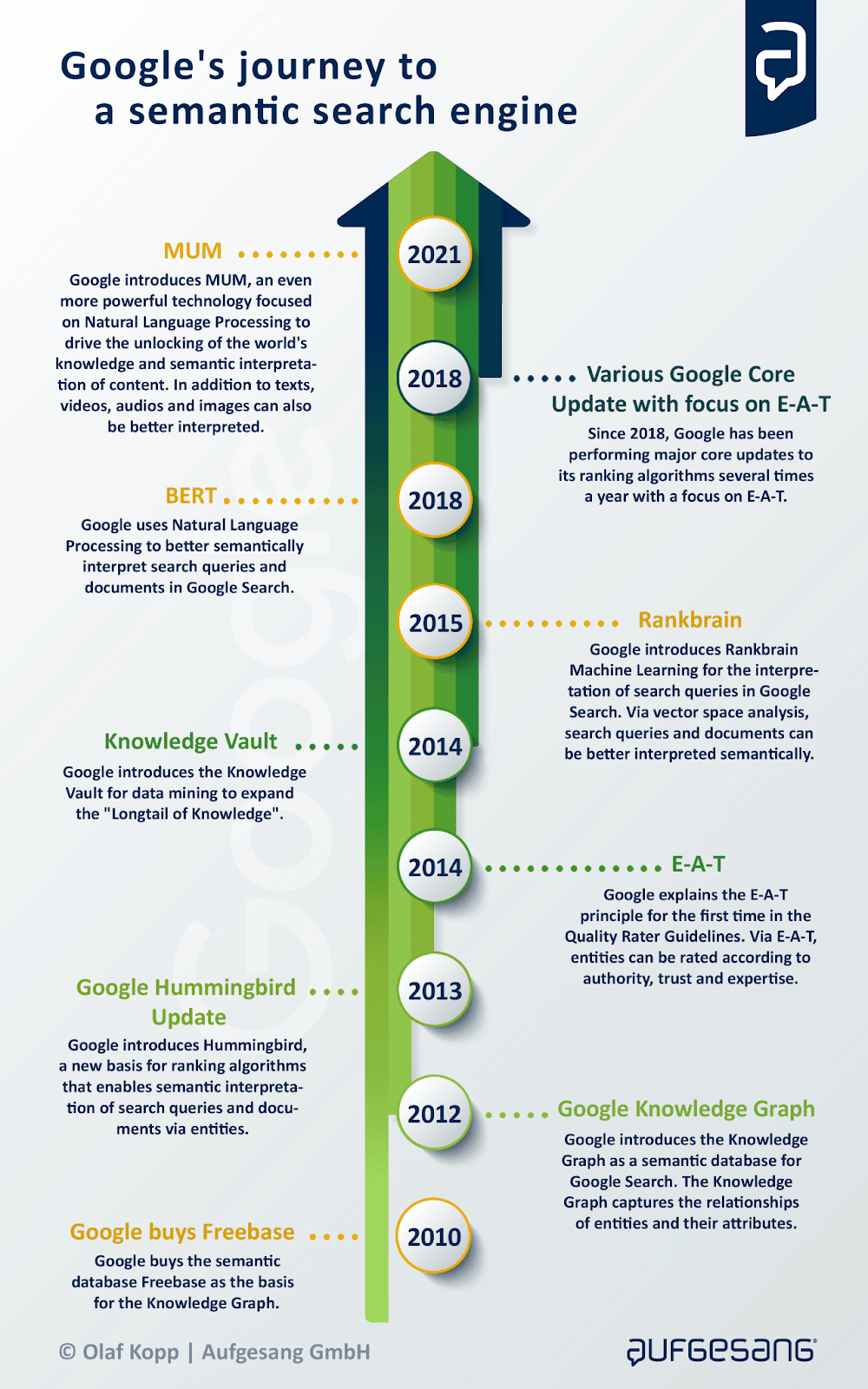
Hummingbird è il segnale di partenza dell’evoluzione di Google in un motore di ricerca semantico, perché prima del 2013 Google si occupava principalmente della corrispondenza tra parole chiave e documenti per il posizionamento, e non era in grado di riconoscere il significato di una query di ricerca o di un contenuto.
Hummingbird ha fondamentalmente sostituito gran parte degli algoritmi di ranking esistenti ed è stata, come sostiene Kopp, “la più grande modifica mai apportata da Google all’elaborazione delle query di ricerca e al ranking, che ha interessato oltre il 90% di tutte le ricerche già nel 2013”. Grazie a questo update, Google è stato immediatamente in grado di includere le entità registrate nel Knowledge Graph per l’elaborazione delle query, il ranking e l’output delle SERP.
Il ruolo del Knowledge Graph nella ricerca semantica Google
Il ranking basato sulle entità richiede anche un’indicizzazione basata sulle entità, e lo strumento usato da Google è il citato Knowledge Graph, che rappresenta appunto l’indice delle entità di Google e tiene conto delle relazioni tra loro.
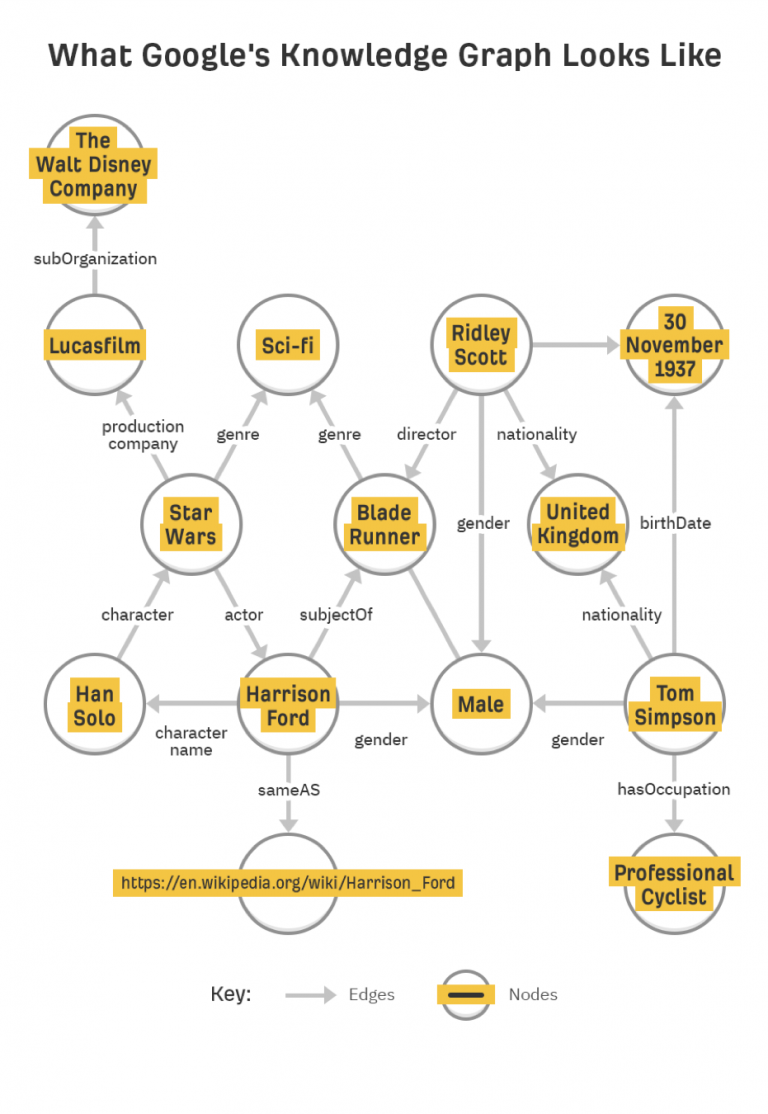
Gli indici classici sono organizzati in forma tabellare e, pertanto, non consentono di mappare le relazioni tra i set di dati: al contrario, il Knowledge Graph è un database semantico in cui le informazioni sono strutturate in modo tale da creare conoscenza dalle informazioni, e qui le entità sono nodi correlati tra loro tramite bordi, dotati di attributi e altre informazioni e inseriti in contesti tematici o ontologie.
Le entità sono l’elemento organizzativo centrale dei database semantici, come il Knowledge Graph di Google; oltre alle relazioni tra le entità, Google utilizza il data mining per raccogliere attributi e altre informazioni sulle entità e organizzarle intorno a queste ultime.

Le fonti, gli attributi e le informazioni che Google considera per un’entità variano a seconda del tipo di entità stessa: semplificando, le fonti di un’entità di una persona sono diverse da quelle di un’entità di un evento o organizzazione, e ciò influisce sulle informazioni visualizzate in un knowledge panel nella SERP.
La struttura di un indice basato sulle entità consente di rispondere a query che cercano un argomento o un’entità non menzionati nella domanda.
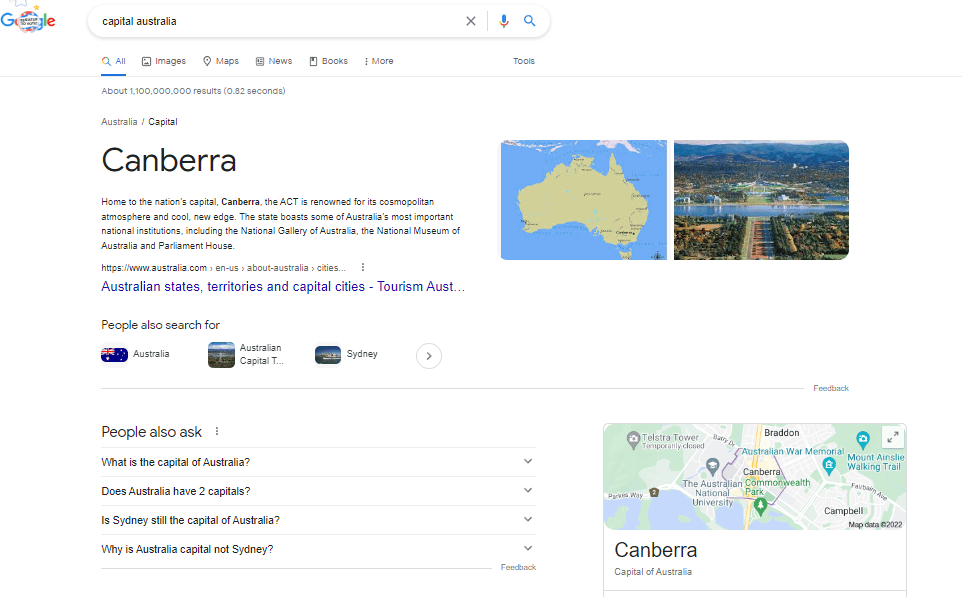
In questo esempio, “Australia” e “Canberra” sono le entità e il valore “capitale” descrive la natura della relazione. Un motore di ricerca basato su parole chiave non avrebbe potuto fornire questa risposta.
Alla base di un Knowledge Graph di Google ci sono tre livelli:
- Catalogo delle entità. Memorizza tutte le entità che sono state identificate nel corso del tempo.
- Archivio della conoscenza (knowledge repository). Le entità sono riunite in un deposito di conoscenza con informazioni o attributi provenienti da varie fonti. Si tratta principalmente di unire e memorizzare descrizioni e creare classi semantiche o gruppi sotto forma di tipi di entità. Google genera i dati attraverso il Knowledge Vault, dove opera il data mining da fonti non strutturate.
- Knowledge Graph. Le entità sono collegate ad attributi e vengono stabilite relazioni tra loro.
Google può utilizzare diverse fonti per identificare le entità e le informazioni ad esse associate, come mostra anche l’immagine esplicativa realizzata dallo stesso Kopp.
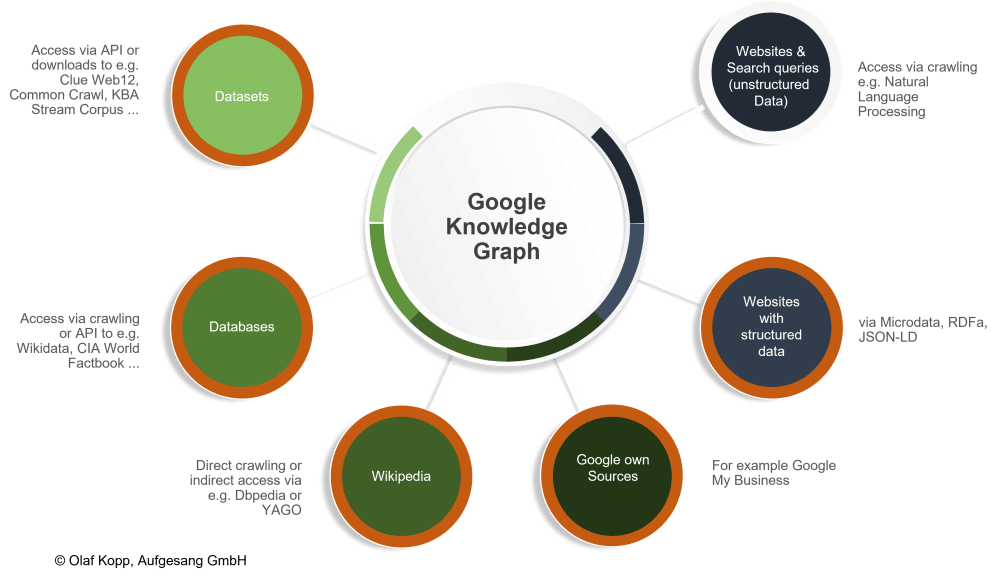
È bene comprendere, comunque, che non tutte le entità contenute nel Knowledge Repository sono incluse nel Knowledge Graph, e alcuni criteri possono influenzarne l’inclusione nel Knowledge Graph, come:
- Rilevanza sociale sostenibile.
- Un numero sufficiente di risultati di ricerca per l’entità nell’indice di Google.
- Percezione pubblica persistente.
- Inserimento in un dizionario o in un’enciclopedia riconosciuti o in un’opera di consultazione specializzata.
Si può ipotizzare che Google abbia registrato un numero significativamente maggiore di entità a coda lunga in un archivio di conoscenze come il Knowledge Vault rispetto al Knowledge Graph e che le utilizzi per la ricerca semantica, sostiene l’autore.
Grazie al crawling dell’Internet aperto e all’elaborazione del linguaggio naturale, Google è in grado di eseguire un’estrazione scalabile di entità e dati indipendentemente dai database strutturati e semistrutturati. Ciò fornisce al Knowledge Vault sempre più informazioni, anche sulle entità a coda lunga.
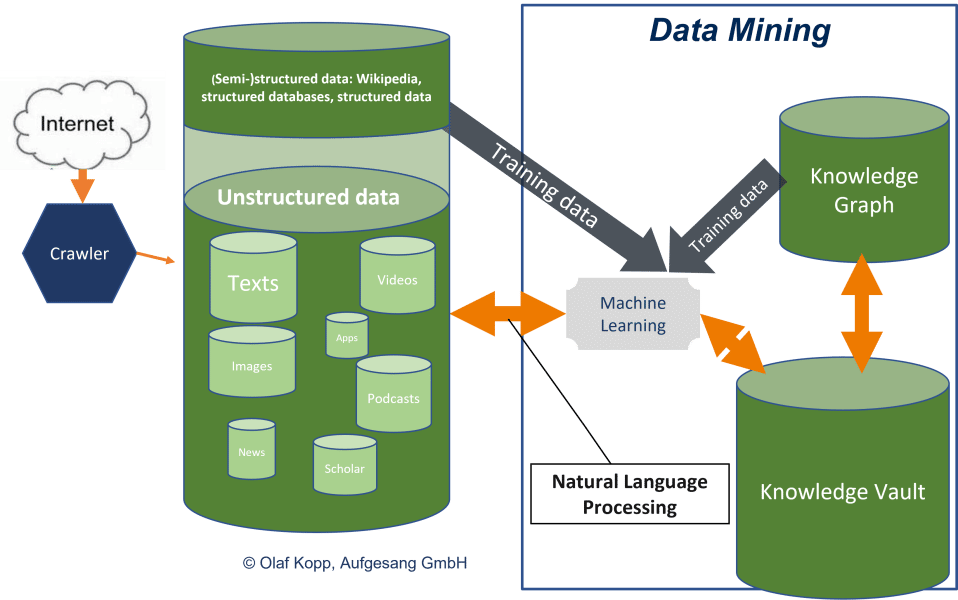
Google come motore di ricerca semantico
Allo stato attuale, Google utilizza la ricerca semantica in alcune aree:
- Comprensione delle query di ricerca o delle entità nell’elaborazione delle query di ricerca.
- Comprensione del contenuto delle entità per il ranking.
- Comprensione di contenuti ed entità per il data mining.
- Classificazione contestuale delle entità per la successiva valutazione E-E-A-T.
La ricerca su Google si basa ora su un processore di query di ricerca per l’interpretazione delle query di ricerca e la compilazione di corpus di documenti rilevanti per la query di ricerca: è qui che possono entrare in gioco BERT, MUM e RankBrain.
Nell’elaborazione delle query di ricerca, i termini di ricerca vengono confrontati con le entità registrate nei database semantici e, se necessario, perfezionati o riscritti. Nella fase successiva, si determina l’intento di ricerca e si determina un corpus adeguato di contenuti X.
Google utilizza l’indice di ricerca classico e il proprio database semantico sotto forma di Knowledge Graph e, secondo Kopp, è “probabile che avvenga uno scambio tra questi due database tramite un’interfaccia”.
Esiste poi un motore di valutazione composto da diversi algoritmi basati sull’algoritmo principale di Hummingbird, che è responsabile della valutazione dei contenuti e del loro ordinamento in base al punteggio. Il punteggio riguarda la rilevanza dei contenuti in relazione alla query di ricerca o all’intento di ricerca.
Poiché Google vuole valutare anche la qualità dei contenuti oltre alla pertinenza, è necessario effettuare anche una valutazione secondo i criteri E-E-A-T, che esaminano e valutano la competenza, l’esperienza, l’autorevolezza e l’affidabilità del dominio, dell’editore e/o dell’autore. I database di entità semantiche possono essere la base per questo tipo di lavoro.
I risultati della ricerca vengono poi liberati dai duplicati tramite un motore di pulizia e si tiene conto di eventuali penalizzazioni.

La linea di fondo di questo percorso – ben messa in luce anche da Adriana Stein – è che Google ha come obiettivo sempre quello di offrire agli utenti la migliore esperienza di ricerca possibile. Per farlo, oggi serve la ricerca semantica, che permette di:
- Identificare e squalificare contenuti di bassa qualità.
- Ottenere una migliore comprensione dell’intento di ricerca degli utenti – ad esempio, l’utente sta cercando di navigare su una pagina particolare? Sta cercando per approfondire informazioni su un argomento? È interessato a comprare?
- Formulare risposte alle domande.
- Determinare quali dati rilevanti estrarre dal Web semantico.
- Comprendere i siti Web e le pagine in termini di argomenti anziché di parole chiave.
- Integrare le tecnologie di Google in cui la ricerca semantica gioca un ruolo come Knowledge Graph, Hummingbird, RankBrain, BERT.
- Formattare opportunamente i dati per l’inclusione nei risultati della ricerca.
- Connettere con query di significato esteso e ampio quando l’intento di ricerca non è chiaro o univoco.
Ricerca semantica, motori di ricerca e SEO
Oggi, la comprensione dei motori di ricerca si è evoluta e di conseguenza abbiamo cambiato il modo in cui dobbiamo lavorare per l’ottimizzazione dei contenuti e delle pagine, perché i giorni del semplice reverse engineering dei contenuti che si classificano più in alto sono alle spalle e l’identificazione delle parole chiave non è più sufficiente.
Con la SEO semantica diventa necessario comprendere il significato di tali parole chiave, fornire informazioni dettagliate che contestualizzino le keyword e comprendere a pieno l’intento dell’utente, elementi vitali in un’era in cui l’apprendimento automatico e l’elaborazione del linguaggio naturale stanno aiutando i motori di ricerca a comprendere meglio il contesto e i consumatori.
In parole povere, oggi analisi semantica è un tentativo di colmare il divario tra l’algoritmo di ricerca, le pagine Web che restituisce e gli utenti del motore di ricerca.
La persona che lancia una query vuole trovare qualcosa e un motore di ricerca ha due compiti da risolvere: capire cosa vuole l’utente e abbinare quell’intento a documenti web che fanno il lavoro migliore soddisfacendo questa esigenza (e fornendo un’esperienza positiva nel complesso).
Da parte sua, il motore di ricerca deve capire cosa vogliono trovare le persone, usando l’analisi semantica per comprendere meglio l’intento della query di ricerca; allo stesso tempo, come detto, deve far corrispondere l’intento della query con le pagine Web che ha nell’indice, usando la codifica semantica che spiegare al motore di ricerca cosa si trova nella pagina e se corrisponde effettivamente all’intento della query.
In tal senso, quindi, la semantica serve a rendere più facili le interazioni tra il motore di ricerca e i suoi utenti, ma anche ad aiutare il motore di ricerca a comprendere (e utilizzare) meglio le informazioni su qualsiasi pagina.
Nei prossimi anni, molto probabilmente, assisteremo a un crescente impatto delle entità nella ricerca su Google, ed è facile ipotizzare che più entità vengono registrate nel Knowledge Graph, maggiore sarà la loro influenza sulle SERP. La stessa comparsa delle ricerche basate sulle entità mostra chiaramente come Google stia gradualmente organizzando l’indicizzazione delle informazioni e dei contenuti intorno a un’entità, e le innovazioni più recenti, come MUM, seguono l’idea di una ricerca semantica.
Ci sono però ancora molte sfide in corso, e in particolare quella di conciliare completezza e accuratezza: oggi, il punteggio effettivo dei documenti viene assegnato da Hummingbird secondo le regole classiche dell’information retrieval, perché in questo ambito le entità a livello di documento non svolgono un ruolo importante, ma rappresentano piuttosto un importante elemento organizzativo per la costruzione di corpora di documenti non ponderati sul lato dell’indice di ricerca. Al contrario, a livello di dominio l’influenza delle entità sul ranking è molto più elevata, ed è qui che entra in gioco l’E-E-A-T e le sue continue evoluzioni.
Quanto conta HTML semantico per il ranking, le parole di Google
Sul tema dell’HTML semantico è intervenuto di recente anche John Mueller di Google, che ha dedicato un episodio della serie #AskGooglebot a spiegare il peso che gli elementi semantici possono avere in termini di benefici potenziali di ranking e visibilità organica. In sintesi, il Search Advocate consiglia di utilizzare l’HTML semantico perché, pur non essere un fattore di ranking diretto, aiuta i motori di ricerca a comprendere i contenuti e aumenta l’accessibilità.
In linea di massima, in questo contesto HTML semantico “è quando gli elementi HTML vengono utilizzati per strutturare i contenuti sulla base sul significato di ogni elemento, non sul loro aspetto”; ad esempio, spiega il video, “invece di ingrandire il testo potresti utilizzare un elemento HTML di intestazione”.
Ci sono molte sfumature su questo ambito, quindi il nostro discorso sarà semplificato ai soli scopi SEO.
Che cosa significa HTML semantico
L’espressione HTML semantico fa riferimento all’utilizzo di specifici elementi HTML che servono a rinforzare il significato del contenuto in un sito web, piuttosto che solo per la sua presentazione, perché descrivono chiaramente il loro contenuto ai browser e ai motori di ricerca, rendendo il web più accessibile e aiutando i motori di ricerca a comprendere il contesto dei contenuti.
Per esempio, gli elementi semantici come <header>, <footer>, <article> e <section> indicano chiaramente la struttura di una pagina web, così come tag quali <nav> per la navigazione, <main> per il contenuto principale e <aside> per il contenuto secondario forniscono ulteriori dettagli sulla struttura e il contenuto di una pagina.
Come evidenzia anche Matt Southern, gli elementi HTML semantici forniscono significato e struttura al contenuto web, aiutando i motori di ricerca e i browser a comprendere meglio il contenuto e le relazioni sulla pagina.
Quali sono gli elementi del semantic HTML
Tra gli elementi semantici più comuni in HTML possiamo quindi citare:
- Le intestazioni o heading, che servono a indicare l’importanza delle varie sezioni e paragrafi, creando una gerarchia dove <h1> è la parte più importante e, progressivamente, <h6> è quella meno rilevante.
- I paragrafi sono usati per rappresentare blocchi di testo; l’elemento <p> definisce un paragrafo.
- Gli elenchi vengono utilizzati per organizzare gli elementi; <ul> e <ol> creano rispettivamente liste non ordinate e ordinate, mentre <li> definisce un elemento dell’elenco.
- Le tabelle strutturano dati tabulari; <table> crea una tabella, <tr> definisce le righe, <th> definisce le intestazioni di colonna e <td> definisce le celle di dati.
- I link o gli ancoraggi (<a>) creano collegamenti ipertestuali tra le pagine e aiutano a mostrare le connessioni tra i contenuti.
- Le immagini (<img>) rappresentano risorse multimediali di tipo foto o grafica; l’attributo alt fornisce una descrizione testuale dell’immagine, che aiuta con l’accessibilità e la SEO.
- Gli articoli (<article>) rappresentano contenuti indipendenti e riutilizzabili come post di blog o notizie.
- Le sezioni (<section>) raggruppano i contenuti correlati all’interno di un documento, ad esempio capitoli o parti di un documento.
- Gli aside (<aside>) contengono contenuti tangenzialmente correlati al contenuto principale, come le barre laterali o gli inserti.
- Le figure (<figure> e <figcaption>) rappresentano un’immagine, un diagramma o un’illustrazione, insieme a una didascalia; mostrano la relazione tra i media e il testo circostante.
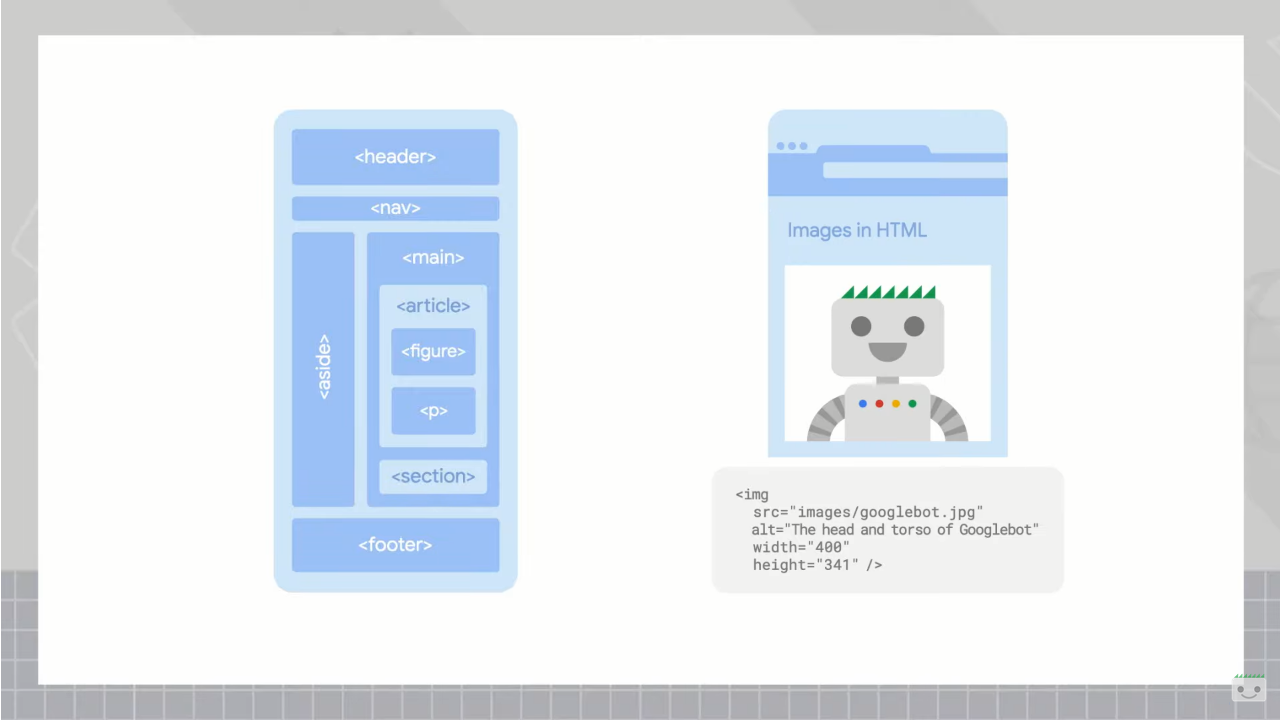
È comunque opportuno considerare che i sistemi di Google non sono particolarmente esigenti o fiscali rispetto all’utilizzo di elementi simili: ad esempio, quando si raggruppa il testo, la maggior parte degli elementi sono trattati allo stesso modo, indipendentemente da che si tratti di un sezione, di un articolo o di un elemento div, perché l’elemento specifico utilizzato è meno importante di una chiara struttura e di una precisa relazione tra gli elementi nel complesso.
HTML semantico: importante per la SEO, ma non fattore di ranking diretto
E quindi, l’utilizzo di elementi di HTML semantico ha una notevole funzione pratica, perché aiuta i motori di ricerca ad analizzare il contenuto e la struttura della pagina, ma non è un fattore di ranking diretto, chiarisce Mueller, che spiega:
“L’HTML semantico aiuta a capire una pagina. Tuttavia, non è un moltiplicatore magico per migliorare il posizionamento di un sito web”.
Ciò premesso, sotto forma di relazione indiretta questi elementi possono comunque influire positivamente sulla visibilità organica di un sito, perché possono migliorare la navigazione degli utenti e l’accessibilità, che restano best practices fondamentali per raggiungere un buon livello di user experience. Inoltre, non meno importante, solitamente portano a codice HTML valido, che è generalmente una buona pratica su tutta la linea.
Più precisamente, l’uso corretto di elementi HTML semantici può aiutare sia Google che gli utenti del nostro sito.
- HTML semantico e Google
Se usati in modo appropriato, gli elementi di semantic HTML possono favorire (anche) la SEO, e ad esempio:
- Le intestazioni permettono di strutturare passaggi di testo.
- Specificare le immagini consente di inserirle nel contesto di parole e contenuto rilevanti.
- I tag di tabella per le tabelle di dati permettono di posizionare non solo il contenuto.
- Inserire anchor link anziché collegamenti che funzionano tramite JavaScript
- HTML semantico e le persone
Gli elementi di semantic HTML migliorano notevolmente l’esperienza degli utenti di diversa estrazione, compresi quelli con disabilità, in particolare in questi modi:
- L’HTML semantico aiuta il software screen reader a trasmettere contenuti Web a utenti non vedenti o ipovedenti.
- L’HTML semantico garantisce la navigabilità da tastiera. Elementi come i collegamenti <a> e i moduli <input>/<button> sono accessibili tramite i controlli da tastiera, che aiutano gli utenti con problemi motori.
- Le tecnologie assistive come i lettori Braille e il software di sintesi vocale traggono vantaggio dalla struttura e dal significato chiariti dall’HTML semantico.
- Gli elementi semantici facilitano il responsive web design, assicurando che il contenuto sia accessibile su vari dispositivi.
- L’HTML semantico rende i contenuti a prova di futuro aderendo agli standard web. Ciò significa che tutti gli utenti saranno probabilmente in grado di accedere al contenuto anche con il progredire della tecnologia.
Gli sviluppatori possono creare contenuti Web comprensibili agli esseri umani e alle macchine seguendo i principi dell’HTML semantico, portando a un’esperienza Web inclusiva.
Anche per questi motivi, Mueller conclude il video con un appello ai proprietari di siti web affinché utilizzino l’HTML semantico, anche se non è un fattore di ranking diretto: “Per favore, usate HTML semantico. Non è un fattore di ranking, ma può aiutare i nostri sistemi a comprendere meglio i vostri contenuti”, dice il Search Advocate.
