
Google Webmaster Conference, consigli e spunti per la SEO
Non solo SMXL19 e SEO Doomsday: la scorsa settimana (ben più lontano di Milano!) c’è stato anche un altro importante appuntamento di settore, con la Google Webmaster Conference organizzata per la prima volta nel quartier generale della compagnia a Mountain View. Barry Schwartz su Search Engine Land ha coperto l’evento e ha raccolto spunti e indicazioni arrivati dall’incontro, per cui vediamo insieme quali sono stati i punti centrali su cui si sono concentrati gli speech (e, quindi, cosa Google ha voluto condividere con gli oltre 200 partecipanti).
I temi della Google Webmaster Conference
Sono cinque i temi interessanti che ha notato Schwartz, e riguardano in particolare:
- Dati strutturati
- Ricerca con emoji
- Consigli di deduplicazione
- Consigli di crawling e rendering
- Gestione dei sinonimi
In realtà non c’è stato nessun annuncio roboante, ma i Googler hanno spiegato con più dettagli come funziona tutto il sistema Google, offrendo quindi supporto ai professionisti SEO per organizzare la loro attività quotidiana, ma anche a pensare le strategie future sulla base dei nuovi trend. Ecco in dettaglio quello che è stato evidenziato (foto da twitter).
Il valore dei dati strutturati
L’importanza dei dati strutturati per i siti dovrebbe essere ormai nota a tutti, ma basta soffermarsi sul lavoro che Google sta dedicando da anni a questo fattore per comprenderlo in modo definitivo. Dalla conferenza per i webmaster si comprende che l’impegno prosegue e potrebbero esserci presto espansioni nel supporto di ulteriori markup di dati strutturati per fornire nuovi rich results nelle SERP e per offrire informazioni sia nei risultati di ricerca che nelle ricerche vocali con Assistant.
In concreto, questo significa che potrebbero essere aggiunti nuovi tipi di rich results oltre alle opzioni già ufficialmente supportate, ma anche che Google sta lavorando per migliorare e aggiornare come queste informazioni sono mostrate effettivamente nelle pagine dei risultati di ricerca di Google.

Google comprende anche le emoji!
Il secondo punto potrebbe apparire solo una curiosità, ma non è così: dopo un lavoro di oltre un anno, ora Google è in grado di scansionare, indicizzare e classificare le emoji nel sistema di Ricerca; inoltre, è stato svelato che già attualmente Google vede più di un milione di ricerche al giorno che contengono emoji nella frase di ricerca!
Consigli di deduplicazione: come segnalare la versione canonica delle pagine
Si torna sui consigli di ottimizzazione on page con i “suggerimenti per la deduplicazione“, ovvero sulle strategie per evitare problemi con la duplicazione dei contenuti (come la cannibalizzazione delle keyword). Gli interventi di questa sessione hanno spiegato come il motore di ricerca gestisce i contenuti duplicati e come i webmaster possono aiutare Google a capire quale sia la versione canonica della pagina da prendere in considerazione.
Le indicazioni in questo senso sono:
- Usa i redirect (che sono “quasi perfettamente predittivi dei contenuti duplicati”, dicono gli ingegneri di Mountain View).
- Usa codici di stato HTTP
- Controlla i link rel canonical.
- Usa hreflang per la localizzazione.
- Segnala casi di hijacking nei forum.
- Dipendenze sicure per pagine sicure.
- Mantieni inequivocabili i segnali di canonicalizzazione e di consolidamento degli URL.
Gestione di rendering e fetching
Si è parlato anche di SEO tecnica e, per la precisione, di scansione, rendering e indicizzazione; anche in questo caso Barry Schwartz ha sintetizzato gli spunti più utili raccolti nel corso della sessione.
- Non fare affidamento sulle caching rules (regole di memorizzazione nella cache) perché Google non le segue.
- Google riduce al minimo le fetches, quindi GoogleBot potrebbe non fare fetching di tutto.
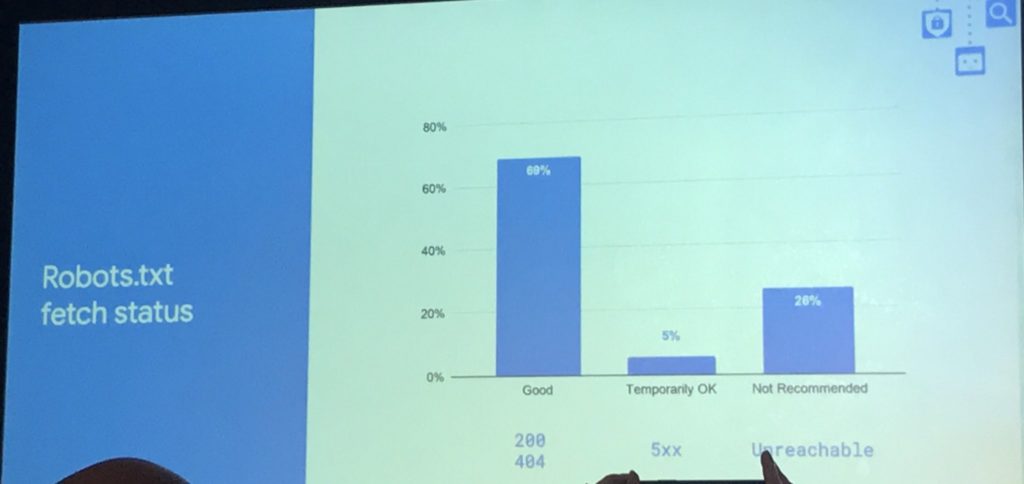
- Google controlla il file robots.txt prima di eseguire la scansione.
- Il 69% delle volte Google riceve un codice di risposta 200 quando tenta di accedere a robots.txt, il 5% delle volte codice di risposta 5XX, il 20% delle volte che il robots.txt non è raggiungibile.
- Un codice 200 è perfetto, ma anche uno status 404 può essere buono perché viene interpretato come assenza di restrizioni nel crawling. Al contrario, se Google non riesce a raggiungere il file robots.txt a causa di un errore 5xx non transitorio (e dopo varie prove), Google non eseguirà la scansione del sito.
- Google esegue il rendering di ciò che generalmente vedi utilizzando il browser Chrome.
- Google esegue 50-60 fetch di risorse per pagina, ovvero una percentuale di cache del 60-70%, oppure circa 20 fetch per pagina.
Google e sinonimi, come evolve il motore di ricerca
L’ultimo focus ha riguardato l’evoluzione dell’algoritmo di Google nella comprensione dei contenuti (anche a seguito del lancio di Google Bert) e Paul Haahr, uno dei leader della sezione Search di Google, ha incentrato la sua presentazione sui sinonimi e su come Google capisce alcune domande, raccontando anche di alcuni errori che il motore di ricerca compieva e che sono stati corretti. Tra gli esempi citati c’è quello della query gm, che ha diversi significati a seconda del contesto in cui è inserito il termine: General Motors, geneticamente modificato e direttore generale. Analizzando il contesto della pagina, Google ora è in grado di determinare quale accezione sia intesa e quindi cataloga al meglio il contenuto.
