
Codici di stato HTTP: le tre cifre che decidono la tua visibilità
Mesi di strategia editoriale, ore di scrittura e investimenti in link building possono svanire in meno di cento millisecondi. Tutto il peso del tuo lavoro poggia su un unico pilastro tecnico, spesso ignorato finché non cede: la risposta del server.
Il codice di stato HTTP — quel numero a tre cifre che vedi comparire nei report di scansione o nei log file del server — è il passaporto dei tuoi contenuti. Googlebot e i crawler delle Intelligenze Artificiali lo controllano prima ancora di leggere una sola parola del tuo testo o di analizzare il design della pagina – è il verdetto istantaneo che distingue una risorsa valida da un vicolo cieco.
Oggi questo controllo è diventato spietato. Con la GEO, la tolleranza per l’errore tecnico si è azzerata. Un codice ambiguo, un blocco di sicurezza o un redirect pigro impediscono fisicamente ai Large Language Models come ChatGPT e Gemini di accedere ai tuoi dati. Se l’AI non riceve il segnale corretto, ti esclude dalle fonti e ti cancella dalle risposte generative. È con la gestione corretta degli status code e degli errori che garantisci alle tue pagine la possibilità di essere lette correttamente e di contribuire alla percezione complessiva del brand.
Cosa sono i codici di stato HTTP
Un codice di stato HTTP è la risposta standardizzata che il server invia al client per comunicare l’esito di una richiesta web.
Più precisamente, gli status code HTTP (HyperText Transfer Protocol Status Code) sono brevi messaggi numerici, identificati con un codice a tre cifre, che segnalano l’esito dello scambio di informazioni tra il server e un browser utilizzato da un utente, Googlebot o il crawler di un’intelligenza artificiale.
Ogni pagina del tuo sito risponde con un codice numerico che indica se la richiesta è andata a buon fine, se la risorsa è stata spostata, se il contenuto non esiste più o se c’è un problema tecnico. Questo codice è lo status code HTTP: un’informazione essenziale che guida il comportamento dei browser, degli strumenti di analisi, di Google e dei Motori AI.
È il primo livello di filtro: se questo segnale è negativo o ambiguo, il contenuto della pagina, per quanto ottimizzato, potrebbe non essere nemmeno preso in considerazione.
La gestione strategica di questi segnali impatta direttamente sul crawl budget, ovvero la quantità di attenzione e risorse che Google è disposto a dedicare al tuo dominio. Se il tuo sito restituisce continuamente errori (classi 4xx e 5xx) o costringe i bot a percorsi a ostacoli attraverso catene di reindirizzamenti (3xx), stai di fatto erodendo la fiducia del motore di ricerca. Google reagisce a questa inefficienza riducendo la frequenza di scansione: il risultato è che le tue nuove pagine resteranno nel limbo dell’indicizzazione molto più a lungo e gli aggiornamenti ai vecchi contenuti verranno recepiti con enorme ritardo.
Cosa significano i codici HTTP
Questi codici, noti anche col nome inglese di status code, sono parte integrante del protocollo HTTP, il linguaggio standard che permette la comunicazione tra client (il tuo browser, ad esempio) e server (dove risiedono i siti web).
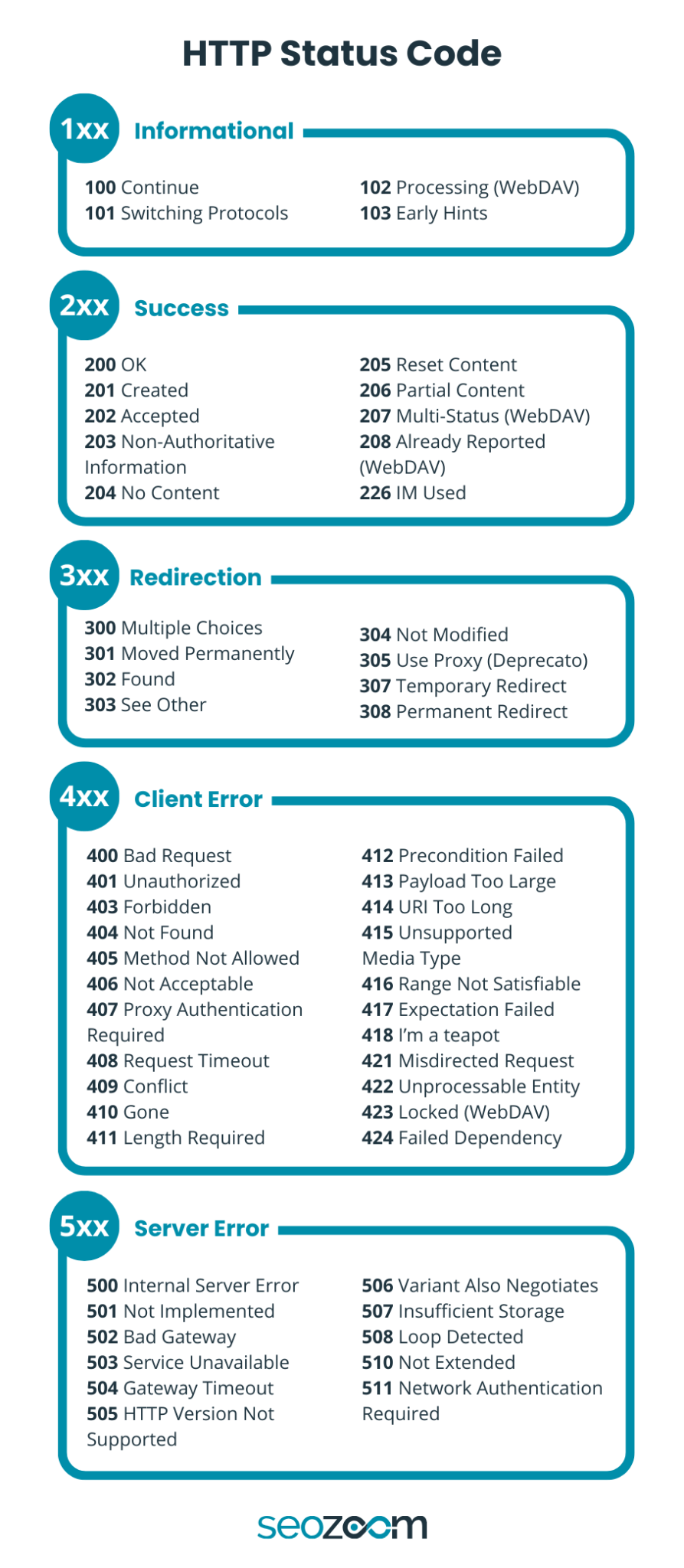
Gli status code seguono una struttura fissa. La prima cifra identifica la categoria:
- 1xx per le risposte informative
- 2xx per le richieste completate
- 3xx per i reindirizzamenti
- 4xx per gli errori legati alla richiesta
- 5xx per i problemi del server.
Il server genera uno status code per ogni URL richiesto, indipendentemente dal CMS o dall’infrastruttura che utilizzi. Per te significa avere un indicatore immediato dello stato della pagina: accessibile, spostata, assente, instabile. Per gli algoritmi significa sapere se vale la pena proseguire con analisi, scansione, rendering e valutazione dei contenuti.
Come funziona la trasmissione del codice
Quando un URL viene richiesto, il server restituisce un pacchetto di informazioni che include lo status code.
Quel valore orienta subito il comportamento di chi sta analizzando la pagina: un 200 comunica disponibilità, un 301 indica una nuova posizione, un 404 segnala l’assenza della risorsa, un 503 invita a riprovare. È un’informazione operativa che condiziona tempi di scansione, priorità e modalità di accesso ai contenuti. Per gli utenti, alcune forme di errore sono visibili, come il 404 o il 503, per i quali si creano in automatico pagine HTML sul browser, mentre invece altri problemi sono invisibili e rintracciabili solo tramite scansioni più profonde con strumenti specifici come i SEO audit.
Il browser utilizza lo status code per gestire la navigazione dell’utente. Googlebot lo usa per decidere se continuare a investire risorse su un URL e per definire come trattarlo nei processi di indicizzazione. I Motori AI fanno riferimento alla stessa condizione: i contenuti che rispondono in modo stabile vengono acquisiti con maggiore facilità, quelli che generano errori o segnali incoerenti restano fuori dal loro perimetro informativo.
La gestione degli status code diventa così un requisito tecnico per garantire accesso, analisi e utilizzo dei contenuti da parte di tutti i sistemi che determinano la tua visibilità.
L’evoluzione del protocollo dal 1996 a oggi
La funzione di questi segnali è cambiata radicalmente negli ultimi trent’anni, seguendo il passaggio dalla gestione di documenti statici alla moderna interazione con gli agenti intelligenti. Tutto ha origine nel 1996, quando Tim Berners-Lee e l’IETF (l’organismo internazionale che definisce i protocolli tecnici di Internet) standardizzano i codici di stato per gestire la comunicazione in un’era di pagine HTML semplici. All’epoca il codice rispondeva a una logica binaria elementare: il file c’è (200) o non c’è (404), senza preoccupazioni legate al crawl budget o all’esperienza utente complessa.
L’evoluzione dell’infrastruttura digitale — dalla persistenza di HTTP/1.1 fino alla velocità UDP di HTTP/3 — ha trasformato questi vecchi segnali in strumenti di controllo critici per orchestrare il traffico tra server cloud, CDN e agenti autonomi. Oggi, quella risposta numerica è il primo filtro tecnico per i crawler delle Intelligenze Artificiali come GPTBot o Google-Extended. Prima ancora di valutare la qualità del testo, il bot interroga lo status code per decidere l’ingestione dei dati nel RAG (Retrieval-Augmented Generation): un errore tecnico impedisce l’addestramento sul tuo contenuto, trasformando il codice di stato nel vero gatekeeper della tua visibilità nell’era dell’intelligenza artificiale.
Le cinque classi di status code e il loro impatto sulla tua visibilità
Non serve memorizzare a memoria l’intero protocollo RFC, ma devi saper riconoscere i segnali che impattano sulla strategia ed essere capace di individuare in pochi passaggi quale tipo di intervento serve e quali rischi stai correndo in termini di accesso, scansione e continuità dei segnali.
In generale, distinguiamo cinque principali categorie di risposta di status code, identificate dalla prima cifra del codice, come detto; ogni classe indica un comportamento diverso e determina quanto facilmente i contenuti possono essere letti, interpretati e riutilizzati nei processi che oggi regolano la ricerca.
- 1xx: risposte informative. Il server comunica al client che la richiesta è stata ricevuta e che il processo di elaborazione delle informazioni è in corso. Sono risposte intermedie che non incidono sulla visibilità del sito, perché non veicolano alcuna informazione utile per la valutazione del contenuto. Tuttavia, una presenza anomala di 1xx nei log può segnalare latenze o configurazioni da verificare, soprattutto in ambienti con alto volume di richieste o infrastrutture distribuite.
- 2xx: risposte corrette e contenuti accessibili. L’operazione è stata completata con successo. Quindi, il server ha ricevuto, elaborato e accettato l’input del client, e l’utente in genere visualizza direttamente la pagina web o la risorsa richieste. Il 200 è il punto di partenza dell’intero processo di analisi: senza una risposta pulita, Google non prosegue e i Motori AI non acquisiscono informazioni. In questa categoria rientrano anche situazioni ingannevoli, come pagine che rispondono 200 ma non contengono contenuti utili o restituiscono errori lato applicazione: condizioni che Google interpreta come soft 404 e che, nel tempo, escludono la pagina dai processi di indicizzazione e dalle risposte generative.
- 3xx: reindirizzamenti e gestione della continuità. Il server riceve la richiesta, ma sono necessarie altre azioni e passaggi lato client per completarla in modo corretto, perché sono presenti inoltri e redirect. I codici 3xx comunicano che la risorsa si trova altrove. Il 301 e il 308 identificano uno spostamento permanente; il 302 e il 307 una condizione temporanea. Nel lavoro quotidiano questa categoria è centrale: determina quale versione dell’URL diventa la tua “versione di riferimento” per Google e quali segnali passano alla destinazione. Catene lunghe o configurazioni incoerenti rallentano la scansione, disperdono segnali e riducono la chiarezza con cui gli algoritmi ricostruiscono la struttura del sito.
- 4xx: errori lato client che interrompono l’accesso alla pagina. È la prima categoria di errori: la richiesta non può essere completata perché ci sono problemi lato client, come sintassi sbagliata o pagina rimossa. L’utente visualizza una pagina html automatica che segnala l’errore. La classe 4xx indica problemi legati alla richiesta. In questa categoria rientrano situazioni molto diverse, ma tutte con un effetto chiaro: la risorsa non è disponibile. Un 404 segnala l’assenza della pagina, un 410 comunica la rimozione definitiva. Per Google significa non poter proseguire con la scansione; per i Motori AI significa non poter acquisire o aggiornare informazioni. Errori ricorrenti in questa categoria riducono la quantità di segnali utili, alimentano incoerenze nella struttura interna e compromettono la visibilità della sezione interessata.
- 5xx: errori lato server. Questa tipologia di codice segnala problemi lato server, che non consente di portare a termine correttamente una richiesta apparentemente valida. L’errore del server può essere momentaneo o definitivo, e anche in questo caso l’utente riceve una pagina html che segnala la circostanza. Sono tra i segnali più critici per la valutazione della qualità tecnica del sito. Un 500, un 502 o un 503 impediscono la lettura del contenuto e vengono trattati come indicatori di instabilità. Nel tempo, queste risposte riducono la frequenza di scansione, mettono in pausa la valutazione degli URL coinvolti e degradano la percezione complessiva di affidabilità, sia per Google sia per i sistemi AI che utilizzano i contenuti per costruire contesto e autorità.
Guida ai principali codici di stato HTTP e agli errori più critici
Completata la panoramica generale, scendiamo nei dettagli.
L’immagine ti mostra l’elenco esaustivo dei codici di stato HTTP, compresi i meno frequenti, mentre qui puoi leggere i codici specifici e gli HTTP error più frequenti che incontrerai durante un audit tecnico o analizzando il report “Indicizzazione” della Search Console. Si tratta di un rapido vademecum dei principali status code che si presentano nel corso della gestione di un sito Web, quelli che è fondamentale conoscere (ed eventualmente correggere) per evitare problemi lato SEO e GEO.
- Codici di successo e redirect (tutto bene o spostato)
Questi segnali confermano che il server sta lavorando correttamente o sta smistando il traffico.
- 200 OK. La richiesta ha avuto successo. È il codice standard per ogni pagina funzionante e indicizzabile. Tutti i dati richiesti sono stati identificati sul server web e trasmessi al client senza problemi. Visitatori, bot e spider non trovano errori e navigano le pagine in modo fluido.
- 301 Moved Permanently. La risorsa è stata spostata definitivamente. È il redirect fondamentale per la SEO perché trasferisce il valore (link juice) al nuovo URL e istruisce Google a sostituire il vecchio indirizzo nel suo indice. Gli utenti non visualizzano il codice, ma l’URL richiesto viene automaticamente modificato sulla barra degli indirizzi e il vecchio non più valido.
- 302 Found. La risorsa è spostata temporaneamente. Il server sposta visitatori e bot sulla nuova pagina, ma la vecchia pagina e il vecchio indirizzo restano ancora validi. Non passa valore SEO immediato e mantiene indicizzato il vecchio URL. Va usato con estrema cautela e solo per situazioni realmente transitorie.
- 304 Not Modified. Indica al browser che la pagina non è cambiata dall’ultima visita, permettendo di caricarla dalla cache. È vitale per risparmiare banda e velocizzare il caricamento.
- Codici di rrrore del client (4xx)
Quando trovi questi errori, il problema risiede nella richiesta: spesso un link rotto, una pagina rimossa o un blocco di sicurezza.
- 401 Unauthorized. Manca l’autenticazione (ad esempio, richiesta password). Se questo codice blocca Googlebot su pagine pubbliche, impedisce l’indicizzazione.
- 403 Forbidden. Il server capisce la richiesta ma si rifiuta di eseguirla. Spesso è causato da plugin di sicurezza o firewall configurati male che bloccano erroneamente i crawler legittimi.
- 404 Not Found. Il classico “Pagina non trovata”. I dati richiesti della pagina non sono stati localizzati sul server. Se isolato è fisiologico, ma se diffuso su link interni diventa un vicolo cieco per l’utente e per il bot.
- 410 Gone. La risorsa è stata rimossa volontariamente e per sempre. È un segnale più forte del 404 per velocizzare la deindicizzazione di contenuti obsoleti. Tutti i link che puntano a una pagina 410 portano bot e utenti verso risorse morte, quindi per una gestione migliore bisogna rimuovere ogni riferimento dai contenuti.
- 429 Too Many Requests. Il client ha inviato troppe richieste in poco tempo. Attenzione: se il tuo server invia questo codice a Googlebot, stai rallentando attivamente la scansione del tuo sito (Rate Limiting).
- Codici di errore del server (5xx)
Questi status code sono allarmi rossi: il sito non funziona e Google potrebbe rimuovere le pagine per proteggere i suoi utenti.
- 500 Internal Server Error. Un errore generico che indica che il server ha “rotto” qualcosa ma non sa specificare cosa. Ad avere problemi non solo le pagine del sito, ma il server stesso, che non riesce a soddisfare una richiesta apparentemente valida. Richiede l’analisi immediata dei log di errore del server e provare a capire se sono necessari interventi, riparazioni o segnalazioni per ripristinare la situazione di normalità.
- 502 Bad Gateway. Un server che agisce da gateway ha ricevuto una risposta non valida da un altro server (spesso accade con configurazioni CDN o Proxy instabili).
- 503 Service Unavailable. Il server è temporaneamente sovraccarico, in manutenzione o comunque temporaneamente non funzionante. È l’unico errore 5xx “buono” se usato correttamente durante i lavori tecnici, perché dice a Google di tornare più tardi senza penalizzare la pagina o il sito, che saranno inattivi solo per un breve periodo.
- 504 Gateway Timeout. Il server non ha ricevuto una risposta tempestiva da un altro server a monte. È tipico di siti lenti, database sovraccarichi o script PHP che vanno in timeout.
Gli errori 5xx indicano che il server non riesce a gestire la richiesta. Se compaiono in modo sporadico, il problema può essere legato al carico, a moduli temporaneamente instabili o a configurazioni non ottimizzate. Se sono frequenti, vale la pena intervenire sull’infrastruttura: controllo delle risorse, ottimizzazione del database, riduzione dei colli di bottiglia, verifica degli script che rallentano la generazione della pagina. Ripristinare una risposta stabile è essenziale per mantenere aperto il flusso dei segnali e per evitare che Google riduca la frequenza di scansione.
L’impatto sui Motori AI e la citabilità delle fonti
Mentre i motori di ricerca tradizionali utilizzano i codici di stato per gestire l’indicizzazione, i crawler delle intelligenze artificiali — come GPTBot, Google-Extended o ClaudeBot — li interpretano come filtri binari per l’ingestione dei dati nei sistemi RAG. La differenza è sostanziale: un browser può tollerare un errore momentaneo e riprovare, ma un agente AI, progettato per l’efficienza computazionale, tende a scartare immediatamente la fonte se incontra ostacoli tecnici.
Un’infrastruttura che risponde con codici puliti (200 OK) è l’unico segnale che autorizza l’agente intelligente a investire risorse per processare e apprendere il contenuto. Al contrario, errori di connessione, latenze eccessive (Timeout 504) o blocchi di sicurezza (403) escludono il dominio dal dataset di risposta in tempo reale. Nel tempo, questi vuoti deformano il quadro complessivo: informazioni non aggiornate, temi che sembrano poco presidiati, contenuti che perdono forza all’interno delle risposte AI. È un effetto lento ma progressivo, che deriva da una base tecnica fragile.
Possiamo quindi dire che oggi la stabilità del codice di stato diventa il prerequisito tecnico per la citability: senza un accesso garantito a livello di server, il tuo brand rimane invisibile nelle interfacce conversazionali, indipendentemente dalla qualità del testo.
Il paradosso dei soft 404: quando il sito mente ai bot
Tra tutti gli errori tecnici, il soft 404 è il più insidioso per la GEO perché rappresenta una falsificazione della realtà: la pagina esiste, il server la considera valida restituendo un codice 200 OK, ma gli algoritmi la trattano come inesistente.
Vengono interpretate come risorse poco rilevanti, vuote, o incapaci di soddisfare l’intento di chi le raggiunge. Per questo finiscono nel gruppo delle pagine che non meritano indicizzazione. In pratica, è come se la pagina ci fosse ma non contasse più nulla ai fini della visibilità.
Per Googlebot questo disallineamento devasta il crawl budget, costringendo il motore a scansionare e indicizzare risorse inutili. Per i Large Language Models, il rischio si sposta sull’inquinamento semantico. Se un LLM scansiona una pagina vuota che risponde “200”, potrebbe ingerire il testo di default (come “Spiacenti, nessun prodotto qui”) e associarlo erroneamente al tuo brand o al topic della pagina. L’AI apprende così che il tuo sito è “vuoto” o irrilevante per quel tema, oppure utilizza il messaggio di errore come se fosse il contenuto reale, generando allucinazioni che danneggiano la tua autorità semantica nel lungo periodo.
Perché Google classifica una pagina come soft 404
Google utilizza una combinazione di segnali per capire se una pagina risponde davvero alle aspettative. Se la struttura è presente ma il contenuto è insufficiente, se gli elementi principali non vengono caricati, o se la pagina comunica implicitamente un errore (“pagina non trovata”, “contenuto assente”, “nessun risultato”), viene considerata irrilevante.
Le cause tecniche più frequenti includono:
- Contenuti scarni: pagine quasi vuote o con righe descrittive prive di valore reale.
- Risorse bloccate: file essenziali (immagini, script, CSS) non disponibili o bloccati dal file robots.txt.
- Layout incompleto: la pagina non restituisce gli elementi principali di navigazione o contenuto.
- Errori applicativi: problemi del CMS mascherati da un codice 200.
- Pagine di ricerca vuote: risultati interni che non generano contenuti.
- Template di errore: layout che mostrano avvisi generici pur mantenendo lo status di successo.
In tutti questi casi, Google tratta la pagina come un errore logico: non la considera nella costruzione della mappa informativa, riduce la frequenza di scansione e rimuove l’URL dall’indice, creando vuoti tematici che indeboliscono la struttura del sito, soprattutto nei topic cluster.
Impatto sulla scansione, sull’indicizzazione e sui sistemi AI
Una pagina classificata come soft 404 esce dai radar. Il crawler riduce la frequenza degli accessi e la pagina viene esclusa dall’indice. Ma il danno maggiore oggi è lato AI: la pagina diventa invisibile ai sistemi che raccolgono dati per generare risposte.
Nella SEO for AI questa categoria di errore è critica. I sistemi generativi operano preferendo contenuti chiari, stabili, completi. Se una pagina è tecnicamente raggiungibile ma non fornisce materiale sufficiente, non partecipa alla costruzione del contesto: gli algoritmi non vedono il tema, non riconoscono il contributo informativo e non associano la pagina agli argomenti rilevanti, riducendo la copertura complessiva del brand.
Come individuare e correggere i soft 404
La diagnosi parte dalla verifica dei contenuti e delle risorse principali, spesso evidenziati nel report Indicizzazione delle pagine di Google Search Console direttamente come “Soft 404”. Devi controllare che la pagina restituisca informazioni utili, che i media siano caricati correttamente e che non vi siano template o messaggi che segnalano implicitamente un errore. Anche il layout influisce: sezioni vuote, blocchi non popolati o risultati interni privi di elementi significativi possono attivare la classificazione.
La correzione dipende dalla causa:
- Se la pagina non deve esistere, configura il server per restituire un 404 o un 410. È la soluzione più pulita.
- Se la pagina deve esistere, assicurati che il contenuto sia completo, denso e che le risorse principali vengano caricate senza errori.
- Se fa parte di una ricerca interna vuota, mostra alternative rilevanti o prodotti correlati invece di una pagina bianca.
- Se il contenuto c’è ma non si vede (è invisibile agli algoritmi), verifica il caricamento delle risorse (JavaScript/CSS) e l’assenza di blocchi nel file robots.txt che impediscono al bot di renderizzare la pagina.
La revisione di queste pagine ha un impatto immediato: una volta ristabilita una risposta coerente, la pagina torna a essere valutabile da Google e rientra nel flusso che alimenta segnali, indice e risposte AI.
Oltre il codice di stato: gli errori di rete e DNS
Prima ancora che il server possa elaborare una richiesta ed emettere un codice HTTP, deve avvenire la connessione. Esiste una famiglia di errori “invisibili” che impedisce a Google e ai Motori AI di bussare alla tua porta: i fallimenti di rete e DNS. Se il DNS (Domain Name System) non riesce a risolvere il nome del dominio in un indirizzo IP, o se il server va in timeout prima di stabilire la connessione, per il motore di ricerca il tuo sito smette istantaneamente di esistere.
Per i bot delle intelligenze artificiali, che operano con finestre di timeout molto ristrette per massimizzare l’efficienza, un DNS lento equivale a un sito offline. Mentre un browser umano potrebbe attendere qualche secondo in più, un crawler come GPTBot tende a interrompere la connessione e passare alla fonte successiva, causando l’esclusione immediata dai processi di RAG.
Strategie di gestione per non disperdere valore
Una volta stabilita la connessione, il server risponde con uno status code. La differenza tra un sito ottimizzato e uno che perde posizionamento risiede nella capacità di scegliere il codice esatto per ogni scenario, governando il flusso di navigazione dei bot invece di subirlo.
- Distinguere strategicamente 404 e 410
Molti gestori di siti utilizzano 404 Not Found e 410 Gone in modo intercambiabile, ignorando che per Googlebot rappresentano istruzioni operative distinte.
- 404 (Not Found). Comunica un’assenza temporanea o indefinita. Google non rimuove subito l’URL dall’indice, ma torna a scansionarlo più volte (anche per giorni) per verificare se l’errore fosse accidentale. È la scelta corretta per contenuti che potrebbero essere ripristinati.
- 410 (Gone). È una dichiarazione definitiva di rimozione. Istruisce il motore di ricerca a deindicizzare la risorsa immediatamente e a non tornare più.
La strategia corretta per la gestione dei contenuti e in particolare per il pruning (la pulizia di contenuti obsoleti o prodotti fuori catalogo senza sostituti) è utilizzare il 410. Lasciare un 404 su migliaia di pagine eliminate costringe i crawler a un lavoro di verifica inutile, erodendo il Crawl Budget che dovresti dedicare alle nuove pubblicazioni.
- Governare i redirect: 301 contro 302
La scelta del reindirizzamento determina se la link juice acquisita da una pagina viene trasferita o dispersa.
- 301 (Permanente). È un trasferimento di valore totale. Indica a Google che il vecchio URL è stato sostituito dal nuovo in modo definitivo. È l’unica opzione valida per migrazioni, cambi di dominio o consolidamento di contenuti, poiché garantisce che il ranking della vecchia pagina passi alla nuova.
- 302 (Temporaneo). Mantiene indicizzata la vecchia URL e non trasferisce immediatamente l’autorità alla nuova. Utilizzarlo per spostamenti definitivi è un errore tecnico grave che “congela” il valore SEO sulla risorsa dismessa, costringendo la nuova pagina a ripartire da zero.
- Salvare il ranking durante la manutenzione (503)
Quando il sito deve andare offline per interventi tecnici, restituire un codice generico di errore (500) è rischioso. La soluzione corretta è configurare il server per rispondere con un 503 Service Unavailable. Questo codice ha un significato specifico per i bot: “Sono in pausa, torna più tardi”. Google interpreta il 503 come uno stand-by pianificato: non deindicizza i contenuti e programma una nuova scansione a breve termine, preservando il posizionamento acquisito anche durante il disservizio.
Diagnosi operativa: come analizzare gli status code
Il monitoraggio degli status code deve essere una parte stabile della manutenzione tecnica del sito, utile per prevenire problemi di visibilità e per individuare rapidamente le pagine che stanno inviando segnali incoerenti.
Un sito di medie dimensioni genera migliaia di risposte HTTP ogni giorno e controllarle manualmente una per una è tecnicamente impossibile oltre che inefficiente. L’unica procedura affidabile per mantenere il controllo sull’infrastruttura è automatizzare il rilevamento simulando periodicamente il comportamento di Googlebot, così da intercettare le anomalie di risposta — interne ed esterne — prima che impattino sul posizionamento organico.
Hai diversi strumenti a disposizione, ognuno con un ruolo preciso. Capire come usarli ti permette di ottenere una lettura completa del comportamento delle pagine e di intervenire quando emergono anomalie.
I browser moderni includono strumenti di sviluppo che ti permettono di osservare in tempo reale la risposta del server. Nella sezione “Network” puoi controllare lo status code restituito per ogni risorsa della pagina, verificare il caricamento degli script, individuare richieste che falliscono e confrontare i tempi di risposta. È un metodo rapido per capire se la pagina presenta errori di caricamento, se alcune risorse non vengono restituite correttamente o se il server impiega più tempo del previsto a generare la risposta.
I log del server offrono una visione più profonda del comportamento delle singole richieste. Qui trovi informazioni su errori 5xx, tentativi di accesso falliti, problemi di configurazione e pattern temporali utili per interpretare la stabilità dell’infrastruttura. Analizzare i log ti permette di distinguere fra singoli episodi e condizioni strutturali: un picco di 503 può dipendere da carico eccessivo; una serie continua di 500 può indicare un problema nell’applicazione o in un modulo del server. È una fonte fondamentale nei progetti che richiedono continuità operativa.
Per un’analisi più approfondita puoi utilizzare software specifici come Wireshark o strumenti di monitoraggio del server come cPanel o Plesk, che registrano i log delle richieste HTTP. Ancora, piattaforme come Screaming Frog permettono di eseguire scansioni dei siti web per identificare i codici di stato e comprendere la loro incidenza sul posizionamento nei motori di ricerca. Questi strumenti sono particolarmente utili per individuare problemi di accessibilità delle pagine, catene di redirect o link interrotti che possono influenzare negativamente l’esperienza dell’utente e, di conseguenza, il ranking del sito.
Identificare gli errori con gli strumenti SEOZoom
SEOZoom centralizza l’attività di debug attraverso due motori di scansione distinti che coprono sia la salute del sito sia la stabilità delle connessioni in ingresso.

Il SEO Spider è lo scanner che replica il passaggio del crawler di ricerca all’interno dell’architettura del sito. La sua funzione è analizzare in profondità la struttura dei link interni per portare a galla gli errori di stato che interrompono la navigazione dei bot.
Per eseguire una diagnosi efficace, avvia una nuova scansione impostando i parametri di profondità e cortesia adeguati alle dimensioni del tuo dominio. Al termine dell’elaborazione, la dashboard dei risultati raggruppa automaticamente le criticità in Errori (problemi gravi) e Warning (avvisi).
- Analisi dei codici 4xx: seleziona il filtro “Errori” per isolare immediatamente le pagine che restituiscono status 404 o 410. Lo strumento non si limita a segnalare l’URL rotto, ma ti indica la pagina di provenienza del link (Inlink), permettendoti di correggere il collegamento alla fonte.
- Verifica dei redirect 3xx: nella tab dei Warning il SEO Spider evidenzia le anomalie sui reindirizzamenti. Qui puoi verificare se stai utilizzando redirect 302 (temporanei) su percorsi che dovrebbero essere definitivi (301) e individuare le catene di redirect che disperdono risorse di scansione.
- Monitoraggio errori server 5xx: il filtro dedicato ti permette di individuare subito le pagine che rispondono con errori interni (come il 500 o 503), segnali critici di instabilità dell’hosting che richiedono un intervento sistemistico immediato.
L’analisi incrociata fra SEOZoom SEO Spider e Search Console ti permette di avere una visione completa: ciò che esce dal server e ciò che Google riconosce come valido. Search Console permette di verificare come Google interpreta gli status code – il report di indicizzazione segnala gli URL che hanno restituito errori 4xx e 5xx durante la scansione e mostra eventuali soft 404. È uno strumento utile per capire non solo la risposta del server, ma anche la lettura che Google ne ha fatto. Se un URL che risponde correttamente con 200 viene classificato come errore, questo indica un problema di contenuto o di caricamento delle risorse.
Il controllo di stabilità off-site con Link Monitor
I codici di stato impattano anche le risorse esterne che puntano al tuo sito, e un backlink che atterra su una pagina di errore o che proviene da una risorsa rimossa smette di trasmettere valore. Link Monitor è lo strumento progettato per verificare automaticamente lo stato dei link nel tempo, proteggendo il capitale di autorevolezza acquisito.
Inserendo nel monitoraggio i backlink strategici ottenuti da campagne di Digital PR o link building, lo strumento esegue controlli ciclici sulla pagina ospitante. Se il server del sito partner restituisce un errore, se la pagina viene rimossa (404) o se il link cambia stato, Link Monitor attiva un avviso visivo (stato rosso). Questo sistema di allerta ti consente di intervenire tempestivamente, contattando il sito ospitante per ripristinare la risorsa o aggiornando la destinazione del link, recuperando così un collegamento che altrimenti verrebbe svalutato da Google.
Il manifesto operativo: gestione SEO e GEO degli errori
Gestire gli errori HTTP non significa solo “riparare cose rotte”, ma guidare i motori di ricerca attraverso l’architettura del sito. La strategia moderna di gestione, valida sia per Google che per le AI generative, si basa su tre regole d’oro che devono guidare ogni tua decisione tecnica:
- Onestà del server: se una pagina non c’è, il server deve dire che non c’è (404/410). Mentire con un Soft 404 o un redirect automatico alla Home confonde l’algoritmo e diluisce la rilevanza tematica del sito.
- Efficienza dei percorsi: ogni redirect 301 consuma una frazione di millisecondo e di risorse. Elimina le catene: il link A deve puntare direttamente a C, senza passare per B.
- Stabilità come ranking factor: un sito che risponde occasionalmente con errori 500 o timeout DNS non è affidabile. Per i motori AI, l’affidabilità tecnica è il prerequisito fondamentale per la citability (la probabilità di essere citati come fonte).
FAQ e chiarimenti sui dubbi più frequenti
I codici di stato HTTP sono quindi le fondamenta invisibili su cui poggia l’intera architettura del tuo sito. Un contenuto eccellente ospitato su una pagina che restituisce un errore tecnico è, per Google e per i Motori AI, un contenuto inesistente. Mantenere un profilo di codici pulito — con 200 OK sulle pagine attive, 301 rigorosi sulle migrazioni e 410 consapevoli sulle rimozioni — è la prima, indispensabile forma di ottimizzazione. Usa il SEO Spider oggi stesso per scattare una radiografia del tuo sito: potresti scoprire che il vero freno alla tua crescita organica non è la qualità dei testi, ma un semplice numero a tre cifre.
Una parte del lavoro, quindi, consiste nel prevenire gli errori; l’altra è capire come intervenire quando emergono comportamenti anomali. Gli status code ti indicano con precisione cosa succede a livello tecnico e ti permettono di agire prima che gli effetti diventino visibili nei dati di traffico o nella classificazione degli algoritmi.
Molti dubbi ricorrenti nascono proprio da questo punto: cosa succede quando un codice cambia? Qual è la scelta migliore in situazioni specifiche? Come reagiscono Google e i sistemi AI? Qui trovi le risposte ai quesiti più comuni, utili per orientare le tue decisioni quotidiane.
- Quali sono i codici di errore HTTP e cosa significano?
I codici di errore HTTP si dividono in due classi: i 4xx (Errori del Client), come il 404, indicano che la risorsa non è stata trovata o la richiesta è errata; i 5xx (errori del server), come il 500, segnalano che il server ha riscontrato un problema interno e non è riuscito a completare l’operazione.
- I Motori AI (come ChatGPT o Gemini) leggono i codici di stato?
Assolutamente sì. I crawler delle AI (come GPTBot) rispettano i codici di stato. Anche se non seguono il crawling tradizionale, se il tuo sito risponde con un errore 5xx o 403, il bot non può scansionare il contenuto, che quindi non entra nel database di conoscenza (RAG) e non può essere usato per generare risposte.
- La SEO for AI richiede una gestione diversa degli status code?
Richiede maggiore attenzione alla stabilità. Una pagina che alterna codici diversi o presenta problemi di caricamento non viene considerata affidabile nei sistemi AI. La continuità tecnica influisce sulla quantità di dati che i modelli recuperano e sulla loro interpretazione del tuo brand.
- Gli status code influenzano la visibilità in AI Overview?
Sì. AI Overview privilegiano contenuti accessibili e coerenti. Se il server restituisce errori ricorrenti, catene di redirect o pagine incomplete, quelle informazioni vengono ignorate e il tuo sito perde spazio nelle sintesi generate.
- Qual è la differenza tra i codici di stato HTTP 401 e 403?
La differenza sta nell’autenticazione. L’errore 401 Unauthorized significa “non so chi sei” (il server richiede un login). L’errore 403 Forbidden significa “so chi sei, ma non puoi entrare”: il server ha riconosciuto il client, ma nega l’accesso per mancanza di permessi o blocchi di sicurezza (come firewall).
- È meglio usare un 404 o un 410 quando una pagina non esiste più?
Il 410 comunica una rimozione definitiva, il 404 una semplice assenza. Google tratta entrambi come pagine non disponibili, ma il 410 accelera l’aggiornamento della mappa degli URL. Può essere utile quando vuoi eliminare una risorsa in modo chiaro.
- Un errore 404 danneggia la SEO o la visibilità nei Motori AI?
Un 404 non danneggia il sito se rappresenta correttamente una pagina rimossa. Diventa un problema quando riguarda risorse importanti o quando compare per errore: in quel caso interrompe la trasmissione dei segnali e la pagina viene esclusa sia dall’indice sia dai sistemi AI che raccolgono contenuti attendibili.
- Dopo quanto tempo Google deindicizza una pagina 404 o 410?
Con un 404, Googlebot potrebbe ripassare più volte per verificare che l’errore non sia momentaneo. Con un 410 (Gone), la rimozione dall’indice è molto più rapida perché segnali esplicitamente che la risorsa è stata eliminata per sempre.
- Cos’è un errore Soft 404 e come lo correggo?
Il Soft 404 si verifica quando una pagina dice all’utente “non trovato” ma restituisce al server un codice 200 OK. La pagina esiste ma non viene considerata utile. È un problema perché spreca crawl budget e inquina i dati per l’AI. Per correggerlo, assicurati che la pagina restituisca effettivamente un codice 404 o 410, oppure imposta un redirect 301 se il contenuto è stato spostato.
- Come faccio a sapere se ho risolto un errore 500?
L’errore 500 è generico e lato server. Dopo aver verificato i log del server (error_log) e corretto il problema (un plugin in conflitto, file .htaccess corrotto o memoria PHP esaurita), usa lo strumento “Controllo URL” di Search Console per testare la pagina in tempo reale. Se il codice restituito torna a essere 200 OK, la correzione è avvenuta.
- Gli errori 5xx hanno effetti immediati?
Gli errori 5xx riducono la frequenza di scansione e segnalano instabilità dell’infrastruttura. Se persistono, le pagine coinvolte perdono continuità nei processi di valutazione e finiscono fuori dai sistemi che aggiornano i segnali.
- Una catena di redirect può influire sulla visibilità?
Sì. Catene lunghe rallentano la scansione e creano incertezza su quale sia la versione di riferimento. Consolidare i percorsi è essenziale per ridurre ambiguità e mantenere i segnali coerenti.
- Un codice 200 garantisce che la pagina verrà indicizzata?
No. Un 200 permette a Google di leggere il contenuto, ma la decisione di indicizzare dipende dalla qualità, dalla chiarezza e dalla rilevanza informativa. Se la pagina resta vuota o incompleta, può essere classificata come soft 404.
- Cosa succede se Search Console segnala un errore che il server non mostra?
In questi casi significa che Google ha incontrato un comportamento anomalo durante la scansione: risorse non caricate, timeout, template incompleti o contenuti non disponibili al momento della richiesta. Serve verificare il caricamento delle risorse e la stabilità della pagina.
