
Googlebot: che cos’è e cosa fa il crawler di Google
Sta dietro le quinte, ma è uno dei principali protagonisti del funzionamento di Google Search. Googlebot è il fondamentale software spider con cui Google riesce a eseguire la scansione delle pagine dei siti Web pubblici, seguendo i link che partono da una pagina e la collegano alle altre della Rete e selezionando quindi le risorse che meritano di entrare nell’Indice del motore di ricerca. Il nome fa pensare immediatamente a qualcosa di simpatico e in effetti anche l’immagine coordinata conferma questa sensazione, e dietro di questo si cela un sofisticato algoritmo che scansiona costantemente il web alla ricerca di nuovi contenuti, aggiornamenti o modifiche alle pagine esistenti. Insomma, questo robottino è alla base dell’intero processo di scansione e indicizzazione di Google, da cui poi deriva il sistema di classificazione: in questo articolo scopriremo non solo che cosa è Googlebot, ma anche come funziona, perché è fondamentale per la SEO e quali sono le migliori pratiche per facilitare il suo lavoro.
Che cos’è Googlebot
Googlebot è il web crawler di Google, uno strumento automatico che esplora in continuazione le pagine del web per raccogliere informazioni utili e popolare l’indice del motore di ricerca di Google.

In pratica, Googlebot è il cervello invisibile che permette a Google di conoscere e interpretare gli infiniti dati presenti su miliardi di siti web, scandagliando la Rete alla ricerca di siti e contenuti in modo automatico e continuativo.
Crawler o spider sono altri termini utilizzati per descrivere questo tipo di software, poiché i bot come Googlebot si muovono da un sito all’altro, “scorrendo” tra i collegamenti ipertestuali, in un processo assimilabile al comportamento di un ragno che tesse la propria rete. In questo lavoro incessante, Googlebot scansiona e analizza le pagine per poi determinarne la pertinenza, così che l’algoritmo di ranking possa presentarci i risultati di ricerca più adatti alle nostre query.
Che cosa significa Googlebot
Il nome Googlebot deriva dalla combinazione della parola “Google” (il cui significato non ha bisogno di molte spiegazioni) e “bot”, che semplicemente è un’abbreviazione di robot. Questo termine descrive alla perfezione la natura automatica dello strumento, che opera come un vero e proprio “robottino” in grado di scansionare il web in modo autonomo e predeterminato.
L’immagine ufficiale di Googlebot raffigura appunto un simpatico robottino con lo sguardo vivace e vagamente simile a Wall-E, pronto a lanciarsi in una ricerca per trovare e indicizzare la conoscenza in tutti gli angoli di Web ancora sconosciuti. Da qualche tempo, poi, il team di Mountain View gli ha affiancato anche uno spider-bot, una sorta di spalla o mascotte aggiuntiva chiamata Crawley, che serve a sottolineare ancor di più il “lavoro” eseguito da questi software.
Se vogliamo fornire una definizione di Googlebot, possiamo dire che sostanzialmente è un programma che esegue tre funzioni: la prima è il crawling, l’analisi approfondita del Web alla ricerca di pagine e contenuti; la seconda è indicizzare tali risorse, e la terza è il ranking, di cui però si occupano più precisamente gli appositi ranking systems del motore di ricerca.
In pratica, il bot prende contenuti da Internet, cerca di capire l’argomento dei contenuti e quali “materiali” possono essere proposti agli utenti che cercano “queste cose”, e infine determina quali delle risorse precedentemente indicizzate è effettivamente la migliore per quella specifica query in quel particolare momento.
Dietro al suo aspetto carino c’è pertanto una macchina potente, che esegue la scansione del Web e aggiunge pagine al suo indice costantemente: è quindi (anche) merito suo se possiamo andare su Google e ottenere risultati pertinenti alle nostre ricerche!
Cosa fa Googlebot e a cosa serve
Possiamo chiamarlo spider, crawler o semplicemente bot, ma non cambia l’essenza del suo meccanismo. Googlebot è un software speciale che esegue la scansione del web seguendo i link che trova all’interno delle pagine per trovare e leggere contenuti nuovi o aggiornati e suggerire cosa dovrebbe essere aggiunto all’Indice, la biblioteca con inventario in continua espansione da cui Google estrae direttamente i risultati della ricerca online.
Questo software consente a Google di compilare oltre 1 milione di GB di informazioni in una frazione di secondo. In pratica, senza questa attività Google non avrebbe modo di creare e aggiornare il proprio indice con miliardi di pagine provenienti da tutto il mondo, e di farlo con la rapidità richiesta oggi.
Più precisamente, poi, Googlebot è il nome generico di due diversi tipi di crawler: un crawler desktop che simula un utente che usa un dispositivo desktop, e un crawler mobile che simula un utente che usa un dispositivo mobile.
A volte il nostro sito è visitato da entrambe le versioni di Googlebot (e nel caso possiamo identificare il sottotipo di Googlebot esaminando la stringa dello user agent nella richiesta), ma con il passaggio all’approccio mobile-first di Google, la quasi totalità delle richieste di scansione di Googlebot viene effettuata usando il crawler mobile.
Inoltre, sempre dal punto di vista tecnico, sia Googlebot desktop che Googlebot mobile condividono lo stesso token di prodotto (token dello user agent) nel file robots.txt, quindi non possiamo impostare selettivamente come target Googlebot per smartphone o Googlebot per desktop usando il file robots.txt.
Perché è rilevante nella SEO
La rilevanza di Googlebot nella SEO è immediatamente comprensibile: senza una scansione accurata e regolare delle nostre pagine web, Google non è in grado di includerle nel proprio indice, precludendoci la possibilità di essere visibili nelle SERP. Per dirla in altri termini, un sito che non viene correttamente scansionato da Googlebot è come se non esistesse.
Per chi si occupa di SEO, però, Googlebot rappresenta molto più di un semplice strumento da cui dipendere: è il “visitante” più importante che un sito possa ricevere, perché le sue scansioni determinano se e come il nostro sito sarà visibile sugli schermi di miliardi di utenti. Ma c’è di più: non basta che Googlebot visiti il sito, è cruciale che riesca a comprenderlo correttamente. Ed è qui che entra in gioco la nostra capacità di ottimizzare al meglio le pagine web.
La SEO, quindi, dovrebbe basarsi prioritariamente sulla capacità di ottimizzare i propri contenuti affinché Googlebot li trovi, li scandagli e li indicizzi correttamente.
In pratica, Googlebot è il filo diretto tra il nostro sito e il vasto mondo delle ricerche su Google. Ottimizzando le nostre pagine per far sì che il crawler le scansioni correttamente, diamo modo a Google di mostrarle agli utenti giusti, al momento giusto, con il risultato di migliorare nettamente tanto le visite quanto la visibilità complessiva del nostro sito.
Quali sono gli altri bot di Google
Googlebot è soltanto il principale crawler di Google, ma non è l’unico e anzi esistono diversi robot, che hanno compiti specifici e che possono essere inclusi in tre grandi categorie, come spiega il documento ufficiale di Mountain View. Google infatti utilizza crawler e fetcher (strumenti come un browser che richiedono un singolo URL quando richiesto da un utente) per eseguire azioni per i suoi prodotti, automaticamente o attivate su richiesta dell’utente.

La lista di questi strumenti comprende:
- Crawler comuni, tra cui spicca appunto Googlebot, che vengono utilizzati per creare gli indici di ricerca di Google, eseguire altre scansioni specifiche del prodotto e per l’analisi. Per caratteristica distintiva, rispettano sempre le regole del file robots.txt, hanno come maschera DNS invertita “crawl-***-***-***-***.googlebot.com o geo-crawl-***-***-***-***.geo. googlebot.com” e l’elenco degli intervalli IP si trova nello specifico file googlebot.json.

- Crawler per casi speciali: crawler che eseguono funzioni specifiche, utilizzati da prodotti specifici in cui esiste un accordo tra il sito sottoposto a scansione e il prodotto in merito al processo di scansione, e che possono o meno rispettare le regole di robots.txt. Ad esempio, AdSense e AdsBot controllano la qualità degli annunci, mentre Mobile Apps Android controlla le app Android, Googlebot-Image segue le immagini, Googlebot-Video i video e Googlebot-News le notizie. La loro maschera DNS inversa è “rate-limited-proxy-***-***-***-***.google.com” e l’elenco degli intervalli IP si trova nel file special-crawlers.json (ed è diverso da quelli dei crawler comuni).

- Fetcher attivati dall’utente: strumenti e funzioni di prodotto in cui l’utente finale attiva un recupero (fetch), come Google Site Verifier che agisce su richiesta di un utente. Poiché il recupero è stato richiesto da un utente, questi fetcher ignorano le regole di robots.txt. La loro maschera DNS inversa è “***-***-***-***.gae.googleusercontent.com” e l’elenco degli intervalli IP si trova nel file user-triggered-fetchers.json. I crawler controllati da Google hanno origine dagli IP nell’oggetto user-triggered-fetchers-google.json e si risolvono in un nome host google.com. Gli IP nell’oggetto user-triggered-fetchers.json si risolvono nei nomi host gae.googleusercontent.com. Questi IP possono essere utilizzati, ad esempio, quando un sito ospitato su Google Cloud (GCP) deve recuperare feed RSS esterni su richiesta di un utente.

Questo specchietto ufficiale ci aiuta a tenere sotto’occhio tutti i possibili visitatori (per lo più desiderati) del nostro sito e delle nostre pagine, suddivisi nelle tre categorie appena descritte.
La guida chiarisce anche che esistono due metodi per verificare i crawler di Google:
- Manualmente: per le ricerche singole, attraverso gli strumenti a riga di comando. Questo metodo è sufficiente per la maggior parte dei casi d’uso.
- Automaticamente: per le ricerche su larga scala, con una soluzione automatica per confrontare l’indirizzo IP di un crawler con l’elenco degli indirizzi IP di Googlebot pubblicati.
Come funziona Googlebot: il processo di crawling e indicizzazione
Come detto, il cuore dell’attività di Googlebot è il cruciale processo cruciale del crawling, la fase in cui il bot inizia a muoversi attraverso le pagine del nostro sito, seguendo i collegamenti interni ed esterni, alla ricerca di nuovi contenuti o aggiornamenti da aggiungere al suo database.
Il crawling di Google è un’attività continua e metodica, progettata per garantire che il motore di ricerca abbia sempre una visione aggiornata del web.
Tuttavia, Googlebot non scansiona ogni angolo di ogni sito allo stesso modo, con la stessa priorità né con la stessa frequenza – è il concetto alla base del crawl budget. Alcune pagine possono essere visitate più spesso, altre di meno, e alcune potrebbero non essere scansionate affatto (a meno di precise istruzioni, come i file robots.txt o l’attributo noindex).
In pratica, Googlebot inizia il suo processo selezionando un elenco di URL da visitare. Questo elenco viene costantemente aggiornato con nuove pagine, che possono essere segnalate da vari fattori come l’esistenza di nuovi collegamenti, sitemap o interventi diretti tramite la Search Console. Una volta avviato, il bot segue i link interni di un sito web “scorrendo” da una pagina all’altra: questo comportamento è il motivo per cui spesso ci si riferisce a Googlebot come a uno spider, una denominazione che sottolinea la sua abilità simile a un ragno nel “tessere” la rete, catturando link e contenuti man mano che procede.
Durante il crawling, Googlebot legge il codice HTML delle pagine e raccoglie informazioni cruciali su di esse, come il contenuto testuale, le immagini, i file CSS e JavaScript. Per esempio, una pagina appena pubblicata o aggiornata può essere analizzata per verificarne la qualità, la rilevanza e persino la struttura dei link interni ed esterni. Queste scansioni aiutano Google a determinare se una pagina è valida per essere inserita nel suo indice. Il suo obiettivo principale è garantire che Google disponga di un inventario aggiornato e rilevante delle risorse online, consentendo al motore di ricerca di restituire i risultati più pertinenti alle query degli utenti.
Il crawler serve a individuare, esaminare e “fotografare” il contenuto di un sito per prepararlo alla fase successiva, ovvero l’indicizzazione. Per questo, le ottimizzazioni in chiave SEO non devono soltanto focalizzarsi sui contenuti visibili agli utenti, ma anche su quegli aspetti tecnici che permettono a Googlebot di trovare e comprendere le pagine nel miglior modo possibile. Un sito con una navigazione complessa o pagine non interlinkate infatti potrebbe risultare difficile da scansionare, danneggiando l’indicizzazione automatica di Google.
In che modo Googlebot organizza le informazioni
Una volta completato il processo di crawling si passa alla fase di indicizzazione, durante la quale tutte le informazioni raccolte vengono ordinate, archiviate e rese ricercabili nel vastissimo database di Google.
Questo processo consente a Google di attribuire un “posto” a ciascuna pagina scansionata all’interno della sua “biblioteca” online, dalla quale vengono successivamente estratti i risultati di ricerca.
Pensiamo all’indice come a una sorta di archivio consultabile in tempo reale: dopo che una pagina è stata scansionata, Googlebot decide cosa fare delle informazioni raccolte. Non tutte le pagine, infatti, vengono immediatamente indicizzate o mostrate nelle SERP, perché Google utilizza una serie di fattori per determinare se una pagina merita di essere archiviata permanentemente e visualizzata tra i risultati – i celeberrimi 200 fattori di ranking.
Siamo portati a considerare crawling e indicizzazione come due attività separate, ma in realtà sono strettamente correlate: il successo dell’indicizzazione dipende dalla qualità e dall’accuratezza del crawling iniziale. Se Googlebot non riesce a scansionare un sito in modo corretto, ad esempio a causa di errori tecnici o pagine bloccate, la conseguenza naturale sarà un’indicizzazione incompleta o difettosa, che ostacola il nostro potenziale posizionamento.
Infine, l’indicizzazione consente a Google di creare un’istantanea di una pagina web, come una copia digitale che può essere successivamente consultata e presentata nei risultati in millisecondi, quando un utente inserisce rilevanti query.
Ranking su Google e Googlebot: qual è il rapporto?
È opportuno a questo punto chiarire meglio il concetto di Googlebot e ranking, facendo riferimento anche a un (vecchio) video di SEO Mythbusting, la serie su YouTube realizzata da Martin Splitt che, spinto dalle richieste di tanti webmaster e sviluppatori e dalla domanda precisa di Suz Hinton (all’epoca Cloud Developer Advocate presso Microsoft), si è dilungato a chiarire alcune caratteristiche di questo software.
In particolare, il developer advocate del Google Search Relations team ha specificato che l’attività di ranking su Google è informata da Googlebot, ma non è parte di Googlebot.
Questo significa dunque che durante la fase di indicizzazione il programma assicura che il contenuto sottoposto a scansione sia utile per il motore di ricerca e il suo algoritmo di posizionamento, che utilizza, come abbiamo detto, i suoi specifici criteri per classificare le pagine.
Un esempio per capire la relazione: la Ricerca come una biblioteca
Torna quindi utile la già citata similitudine con una biblioteca, in cui il responsabile “deve stabilire quale sia il contenuto dei vari libri per dare le giuste risposte alle persone che li chiedono in prestito. Per farlo, consulta il catalogo di tutti i volumi presenti e legge l’indice dei singoli libri”.
Il catalogo è dunque l’Indice di Google creato attraverso le scansioni di Googlebot, e poi “qualcun altro” usa queste informazioni per prendere decisioni ponderate e presentare agli utenti il contenuto che richiedono (il libro che vogliono leggere, per proseguire nell’analogia fornita).
Quando una persona chiede al bibliotecario “qual è il miglior libro per imparare a fare torte di mele in modo molto veloce”, quest’ultimo deve essere in grado di rispondere adeguatamente studiando gli indici degli argomenti dei vari libri che parlano di cucina, ma sa anche quali sono i più popolari. Quindi, in ambito Web abbiamo l’indice fornito da Googlebot e la “seconda parte”, la classificazione, che si basa su un sistema sofisticato che studia l’interazione tra i contenuti presenti per decidere quali “libri” raccomandare a chi chiede informazioni.
Una spiegazione semplice e non tecnica della scansione
Splitt è tornato successivamente a chiarire l’analogia sul funzionamento di Googlebot e un articolo di SearchEngineLand riporta le sue parole per spiegare in modo non tecnico il processo scansione del crawler di Google.
“Tu stai scrivendo un nuovo libro e il bibliotecario deve concretamente prendere il libro, capire di cosa tratta e anche a cosa si riferisce, se ci sono altri libri che potrebbero essere stati fonte di partenza o potrebbero essere referenziati da questo libro”, ha detto il Googler. Nel suo esempio, il bibliotecario è il web crawler di Google, ovvero Googlebot, mentre il libro è un sito o una pagina Web.
Semplificando, il processo dell’indicizzazione funziona quindi in questo modo: “Devi leggere [il libro], devi capire di cosa si tratta, devi capire come si collega agli altri libri, e poi puoi ordinarlo nel catalogo”. Pertanto, il contenuto della pagina web viene memorizzato nel “catalogo“, che rappresenta fuor di metafora l’indice del motore di ricerca, da dove può essere classificato e pubblicato come risultato per le query pertinenti.
In termini tecnici, ciò significa che Google ha “un elenco di URL e prendiamo ciascuno di questi URL, facciamo loro una richiesta di rete, quindi guardiamo la risposta del server e poi lo renderizziamo (fondamentalmente, lo apriamo in un browser per eseguire JavaScript); quindi guardiamo di nuovo il contenuto e poi lo inseriamo nell’indice a cui appartiene, in modo simile a quello che fa il bibliotecario”.
La storia e l’evoluzione di Googlebot
Quando pensiamo a Googlebot oggi, lo immaginiamo come un sofisticato crawler capace di gestire quantità enormi di dati distribuiti su miliardi di pagine web. Ma non è sempre stato così. La storia di Googlebot è caratterizzata da un’evoluzione costante, alimentata dall’esigenza crescente di offrire risultati di ricerca sempre più rilevanti e precisi agli utenti. Le prime versioni di questo spider di Google erano decisamente meno complesse rispetto a quelle attuali, ma ogni trasformazione ha segnato progressi fondamentali nell’ottimizzazione del crawling e, di conseguenza, delle strategie SEO.
Inizialmente, Google si è concentrata su un bot che poteva raccogliere informazioni di base dalle pagine web e metterle a disposizione per l’indicizzazione. Pur trattandosi già di una tecnologia avanzata rispetto a molti altri bot degli anni ’90, Googlebot si limitava a scansionare testi, ignorando elementi più complessi che vediamo oggi come centrali, ad esempio file JavaScript o CSS. Con il tempo, però, il suo ruolo si è progressivamente ampliato. Man mano che il web evolveva, diventando sempre più dinamico e interattivo, anche Googlebot ha dovuto adattarsi. La SEO stava cominciando a prendere piede, e le aziende e i webmaster cercavano continuamente nuovi modi per ottimizzare i loro siti web.
Uno dei principali cambiamenti che ha caratterizzato questo bot è stata la capacità di gestire contenuti dinamici creati attraverso JavaScript, una sfida che ha richiesto un notevole miglioramento in termini di risorse computazionali e potenza di elaborazione. Con l’introduzione del cosiddetto Googlebot Crawl potenziato, Google ha iniziato a rendere possibile la lettura e l’interpretazione di siti web molto più complessi e interattivi, contribuendo in maniera diretta a migliorare le capacità SEO di tutti coloro che sfruttavano siti Static Sites Generators o framework avanzati.
Con il tempo, Google ha anche dato ai webmaster strumenti più avanzati per monitorare da vicino le interazioni di Googlebot sui propri siti. Ogni accesso di Googlebot al sito è potenzialmente visibile tramite il server log, dove è possibile individuare gli IP di Googlebot e controllare quali parti del sito vengono scansionate, con che frequenza e che tipo di risposta il server invia. Questo ha avuto un impatto profondo sul monitoraggio della SEO tecnica, permettendo di correggere errori critici ed evitare che i crawler si perdano nelle sezioni meno rilevanti del sito.
Un’altra evoluzione significativa arriva con la transizione dell’indicizzazione verso il mobile-first, che ha segnato un punto di svolta per Googlebot. Con l’aumento esponenziale degli utenti che navigano da dispositivi mobili, Google ha introdotto specifiche varianti del bot, come Googlebot mobile, pensato per scansionare la versione mobile di un sito e valutarne l’usabilità, la leggibilità e la velocità. In questo modo, Google scopre i contenuti utilizzando un user agent mobile e una viewport mobile, che serve al motore di ricerca per assicurarsi di servire qualcosa di visibile, utile e carino alle persone che navigano da dispositivo mobile.
Questo spostamento ha profondamente cambiato il modo in cui gli sviluppatori e i SEO specialisti progettano e implementano le loro strategie di ottimizzazione, essendo ormai cruciale garantire che i siti siano perfettamente ottimizzati per i dispositivi mobili, poiché Googlebot mobile ha la precedenza nel crawling. In tal senso, diventa centrale il concetto di mobile readiness o mobile friendliness: rendere una pagina mobile friendly significa assicurarsi che tutti i contenuti rientrino nell’area viewport, che i “tap targets” siano sufficientemente larghi da evitare errori di pressione, che i contenuti possano essere letti senza dover necessariamente allargare lo schermo e così via, come già spiegava Splitt, anche perché questi elementi sono un indicatore di qualità per Google. Anche se alla fine il consiglio che dà l’analyst è di “offrire buoni contenuti per l’utente“, perché è la cosa più importante per un sito.

Il Googlebot evergreen, per rispondere alle evoluzioni tecnologiche
A partire dal maggio 2019 per il crawler di Big G c’è stata una fondamentale novità tecnica: per assicurare il supporto alle più nuove feature delle web platform, infatti, Googlebot è diventato evergreen e in continuo aggiornamento, dotato di un motore capace di gestire costantemente l’ultima versione di Chromium quando esegue il rendering delle pagine Web per la Ricerca.
Secondo Google, questa funzione era la “richiesta numero uno” da parte di partecipanti a eventi e community sui social media rispetto alle implementazioni da apportare al bot, e dunque il team californiano si è concentrato sulla possibilità di rendere GoogleBot sempre aggiornato all’ultima versione di Chromium, portando avanti un lavoro durato anni per intervenire sull’architettura profonda di Chromium, ottimizzare i layer, integrare e far funzionare il rendering per la Search e così via.
In termini concreti, da quel momento Googlebot è diventato capace di supportare oltre mille feature nuove, come in particolare ES6 e nuove funzionalità JavaScript, IntersectionObserver per il lazy-loading e le API Web Components v1. Fino al maggio 2019 GoogleBot era stato volutamente mantenuto obsoleto (per la precisione, il motore era testato su Chrome v41, rilasciato nel 2015) per garantire che indicizzasse le pagine Web compatibili con le versioni precedenti di Chrome. Tuttavia, i sempre più frequenti disservizi per i siti web costruiti su framework con funzionalità non supportate da Chrome 41 – che quindi subivano l’effetto opposto e incontravano difficoltà – ha reso necessaria la svolta.
La scelta di rendere evergreen GoogleBot e il suo motore di ricerca risolve questo problema e, allo stesso tempo, rappresenta una notizia positiva per gli utenti finali, che possono ora fruire di esperienze più veloci e maggiormente ottimizzate.
Come scritto su quello che all’epoca si chiamava ancora Twitter da Ilya Grigorik, Web performance engineer di Google, non ci saranno più “transpiling di ES6″ o “centinaia di web features che non richiedono più il polyfilling o altre soluzioni alternative” complesse, a vantaggio anche dei tanti siti che hanno inviato lo stesso codice transpiled a tutti.
Ma la storia dell’evoluzione di Googlebot è tutt’altro che conclusa. Oggi, con l’emergere di tecnologie come l’intelligenza artificiale, Googlebot è diventato ancora più “intelligente”. Con l’introduzione di componenti AI nel crawling e nell’indicizzazione, la capacità di Googlebot di comprendere linguaggi naturali e rispondere alle query degli utenti in modo contestuale e semantico è in continua espansione, avvicinando il motore di ricerca a uno “spider” che non si limita più a scansionare meccanicamente pagine, ma è in grado di interpretare e comprendere le intenzioni dietro a ogni segnale sul web.
Googlebot e la scansione dei siti: gestione e ottimizzazione del crawl budget
Lo abbiamo detto – e lo ricordava anche Martin Splitt nel citato video: Googlebot non scansiona semplicemente tutte le pagine di un sito allo stesso momento, sia per limitazioni di risorse interne sia per evitare di sovraccaricare il servizio del sito.
Dunque, cerca di capire quanto può spingersi nella scansione, quante risorse proprie ha a disposizione e quanto può stressare il sito, determinando quello che abbiamo imparato a definire crawl budget e che spesso è difficile determinare.
Il crawl budget rappresenta il quantitativo di risorse che Googlebot dedica per scansionare un sito web. In altre parole, è una sorta di “budget di tempo e risorse” che Google assegna a ciascun sito per decidere quante pagine scansionare e con che frequenza. La gestione ottimale di questo budget è essenziale per evitare che Googlebot spenda inutilmente tempo su pagine di minore rilievo, penalizzando l’indicizzazione di quelle più importanti.
Il crawl budget dipende da vari fattori: la dimensione del sito, il numero di modifiche che vengono apportate con frequenza alle pagine, le performance del server e l’autorità generale del sito stesso. I siti di grandi dimensioni, ad esempio con migliaia di pagine prodotti editoriali o e-commerce, devono prestare particolare attenzione all’ottimizzazione del crawl googlebot, poiché è molto facile che pagine di scarso valore o pagine duplicate consumino inutilmente risorse, influenzando negativamente l’efficacia della scansione da parte di Googlebot.
“Ciò che facciamo – spiegava Splitt – è lanciare una scansione per un po’, alzare il livello di intensità e quando iniziamo a vedere errori ridurre il carico“.
Quando Googlebot scansiona un sito? E quanto spesso Googlebot esegue la scansione?
Nello specifico, Splitt descriveva anche come e quando un sito viene sottoposto a scansione da Googlebot: “Nella prima fase di crawling arriviamo alla tua pagina perché abbiamo trovato un link su un altro sito o perché hai inviato una Sitemap o perché in qualche modo sei stato inserito nel nostro sistema”. Un esempio di questo tipo è usare la Search Console per segnalare il sito a Google, un metodo che dà un suggerimento e uno sprone al bot e lo sprona (hint and trigger).
Collegato a questo tema c’è un altro punto importante, la frequenza della scansione: il bot prova a capire se tra le risorse già presenti nell’Indice c’è qualcosa che ha bisogno di essere controllato più spesso. Ovvero, il sito offre notizie di attualità che cambiano ogni giorno, è un eCommerce che propone offerte che cambiano ogni 15 giorni, o addirittura ha contenuti che non cambiano perché è il sito di un museo che si aggiorna raramente (magari per mostre temporanee)?
Ciò che fa Googlebot è separare i dati dell’indice in una sezione che viene chiamata “daily or fresh” che viene inizialmente sottoposta a scansione in modo assiduo per poi ridurre la frequenza col tempo. Se Google si accorge che il sito è “super spammy o super broken“, Googlebot potrebbe non scansionare il sito, così come le regole imposte al sito tengono lontano il bot.
Il mio sito è visitato da Googlebot?
Questa è la crawler part dello spider di Google, a cui seguono altre attività tecniche più specifiche come il rendering; per i siti, però, può essere importante sapere come capire se un sito è visitato da Googlebot, e Martin Splitt spiega come fare.
Google usa un browser a due fasi (crawling e vero rendering), e in entrambi i momenti presenta ai siti una richiesta con intestazione dell’user agent, che lascia tracce ben visibili nei log referrer. Come si legge nei documenti ufficiali di Mountain View, Google usa una decina di token dello user-agent, responsabili di una parte specifica di crawling (ad esempio, AdsBot-Google-Mobile controlla la qualità dell’annuncio nella pagina web Android).
I siti possono scegliere di offrire ai crawler una versione non completa delle pagine, ma un HTML pre-renderizzato appositamente per facilitare la scansione: è quello che si chiama rendering dinamico, che significa in pratica avere contenuti visualizzati lato client e contenuti pre-visualizzati per specifici user-agent, come si legge nelle guide di Google. Il rendering dinamico o dynamic rendering viene consigliato soprattutto per siti che hanno contenuti generati con JavaScript, che restano di difficile elaborazione per molti crawler, e offre agli user-agent dei contenuti adatti alle proprie capacità, come ad esempio una versione HTML statica della pagina.
Come facilitare la scansione da parte di Googlebot
Ottimizzare la scansione del sito web è uno degli obiettivi più importanti per migliorare l’efficienza di Googlebot e garantirsi un’indicizzazione corretta. Per farlo, è necessario adottare accorgimenti che rendano la struttura del nostro sito chiara e facilmente navigabile. Dalla corretta organizzazione dei link interni all’utilizzo dei file robots.txt e delle sitemap, ogni dettaglio tecnico conta quando si tratta di siti con una quantità elevata di contenuti.
La prima cosa che occorre fare è assicurarsi che Googlebot possa muoversi senza difficoltà all’interno del sito. La navigazione deve essere fluida, con URL ben collegati tra loro – ad esempio, le pagine orfane e non collegate da nessun altro URL del sito tendono a non essere scansionate. Un’altra cosa da tenere sotto controllo è la questione degli errori del server: un sito con errori frequenti o pagine che restituiscono il famigerato 404 not found rischia di danneggiare la percezione che Googlebot ha della nostra qualità complessiva.
Una gestione accurata dei file robots.txt è essenziale per facilitare la scansione da parte del bot, perché questo file consente di specificare a Googlebot quali sezioni vogliamo escludere dal crawling. Bloccare l’accesso a sezioni non rilevanti come pagine di ricerca interna, strumenti di backend o lo stesso login è utile per evitare sprechi di risorse. Così facendo, ci assicuriamo che Googlebot si concentri sui contenuti chiave da indicizzare. Allo stesso tempo, grazie alle sitemap XML possiamo fornire chiare indicazioni su quali pagine sono nuove, rilevanti e aggiornate, aiutando il bot a determinare cosa scansionare con più frequenza.
Un altro aspetto tecnico cruciale è la velocità di caricamento delle pagine. Siti lenti rischiano di limitare il numero di pagine scansionate da Googlebot, perché il crawler interrompe la scansione su siti che caricano troppo lentamente. Ottimizzare le immagini, ridurre il peso dei file CSS e Javascript rappresenta un ottimo punto di partenza per migliorare le prestazioni generali. L’obiettivo è creare un sito veloce, reattivo e accessibile su qualunque dispositivo.
Infine, con l’aumento delle ricerche da dispositivi mobili, è cruciale prestare attenzione al mobile-first indexing. Googlebot presta una particolare attenzione alla versione mobile dei siti, indicizzando spesso quella come versione principale. Garantire che il nostro sito sia ottimizzato per il mobile, con un design responsive e tempi di caricamento rapidi, è ormai indispensabile per facilitare la scansione da parte di Googlebot.
Googlebot e SEO: analisi pratica e strategica
Lo abbiamo detto prima: chi si occupa di SEO non può trascurare il modo in cui Googlebot interagisce con il proprio sito.
Il crawler rappresenta il “ponte” tra i contenuti pubblicati e la loro indicizzazione all’interno del motore di ricerca, ed è proprio questa relazione a condizionare il posizionamento organico. Il comportamento di Googlebot, infatti, incide sulle performance SEO perché influisce sulla frequenza della scansione, sull’indicizzazione delle pagine e, in ultima battuta, sulla loro visibilità nelle pagine di risultati.
Ottimizzare la nostra strategia SEO significa, in definitiva, anche saper leggere i segnali di scansione lasciati da Googlebot e agire tempestivamente per migliorare l’indicizzazione e la gestione delle pagine da parte del crawler.
Un aspetto che spesso passa inosservato riguarda l’user agent di Googlebot, la stringa specifica che rappresenta l’identità che il bot adotta ogni volta che effettua una scansione su un sito web. La user agent di Googlebot varia a seconda del tipo di device che simula ed esistono diversi user agent per la versione desktop e mobile del crawler. Monitorare la user agent attraverso i file di log del server ci permette di comprendere meglio i comportamenti di Googlebot e quali fuochi di scansione vengano applicati alle diverse sezioni del sito. Grazie a questi log, possiamo verificare che il bot stia effettivamente scansionando le pagine chiave e non stia visitando risorse di priorità secondaria (o bloccate).
Googlebot mobile vs desktop: differenze e considerazioni tecniche
Con l’adozione del mobile-first indexing, completata nel 2024, l’attenzione di Googlebot si è spostata dal desktop ai dispositivi mobili. Questa non è solo una questione tecnica, ma riflette come Google adatta continuamente il proprio approccio alle nuove abitudini degli utenti, che sempre più spesso effettuano ricerche e navigano su device mobili. Ecco perché distinguere tra le versioni mobile e desktop di Googlebot è diventato cruciale per ottimizzare il nostro sito web.
Googlebot mobile è attivamente impegnato nel garantire che le versioni mobili dei siti siano di pari livello rispetto a quelle desktop. Questo significa che il Googlebot smartphone controllerà non solo la correttezza del codice HTML, ma anche la velocità di caricamento, la responsività del layout e l’accessibilità del sito su smartphone e tablet. La versione desktop di Googlebot, una volta dominante, ora assume un ruolo secondario quando si tratta di valutare le prestazioni SEO. Tuttavia, potrebbe ancora essere fondamentale per i siti che puntano principalmente a essere fruiti in formati desktop, come quelli con contenuti complessi destinati a utenti di business o soluzioni aziendali più elaborate.
Il mobile-first indexing ha cambiato le regole del gioco, imponendo che i contenuti ottimizzati per i dispositivi mobili siano la versione principale da scansionare e indicizzare. Se una pagina non è ottimizzata per il mobile, Googlebot mobile potrebbe sottovalutare la sua rilevanza, con un impatto diretto sulla visibilità nelle SERP. Una delle differenze chiave tra questi due bot è proprio il focus sugli elementi ottimizzati per dispositivi mobili, come la facilità con cui un utente può navigare e interagire con la pagina.
Con i report della Google Search Console e soprattutto le metriche di riferimento dei Core Web Vitals possiamo identificare e correggere eventuali criticità relative a entrambe le versioni del sito, verificando ad esempio se Googlebot riesce a scansionare correttamente le risorse di una pagina e rilevare eventuali ostacoli tecnici, come file JavaScript o CSS bloccati.
Come tracciare il passaggio di Googlebot sul sito: strumenti e tecniche
Monitorare il passaggio di Googlebot su un sito è un aspetto fondamentale per ottimizzare la nostra strategia SEO e assicurarci che le pagine più rilevanti vengano correttamente scansionate e indicizzate.
Il primo riferimento è la già citata Google Search Console, in cui troviamo alcuni strumenti molto utili per tracciare e gestire l’attività di crawling.
Uno dei più importanti è il Crawl Stats Report, il Rapporto Statistiche di Scansione che fornisce una panoramica dettagliata su quante richieste di scansione sono state effettuate da Googlebot nelle ultime settimane (o mesi), e include dati preziosi come il tempo di risposta del server e gli eventuali errori riscontrati durante il crawling. Anche se si tratta di dati aggregati e non specifici, è uno strumento essenziale per capire il comportamento di Googlebot e verificare se ci sono inefficienze nel tempo di caricamento delle pagine o problemi di visualizzazione che potrebbero impattare negativamente sulla scansione.

Inoltre, la funzione di Controllo URL permette di vedere se una singola pagina è stata scansionata e indicizzata correttamente, in modo da verificare subito eventuali problemi di accesso derivanti da restrizioni nei file robots.txt o da errori del server.
Per ottenere un’analisi più dettagliata del passaggio di Googlebot, tuttavia, il metodo più completo è l’analisi dei file di log del server, che raccolgono dati relativi a ogni visita sul sito, inclusi dettagli come gli IP di Googlebot, il tipo di richieste effettuate e la risposta del server. In questo modo, possiamo avere una vista granulare su quale IP specifico collegato a Googlebot ha effettuato la scansione e l’esito delle richieste inviate; filtrare questi log alla ricerca degli user-agent Googlebot permette di verificare l’attività del bot in tempo reale e assicurarsi che le pagine strategiche vengano scansionate come previsto.
Come bloccare Googlebot? Quando e perché farlo
Pur essendo essenziale per la visibilità del nostro sito, ci sono situazioni in cui bloccare la scansione di Google su determinate sezioni rappresenta una scelta oculata e necessaria. Saper bloccare Googlebot efficacemente, utilizzando gli strumenti appropriati, può aiutare a evitare la scansione e indicizzazione di pagine indesiderate o potenzialmente superflue per la nostra strategia SEO.
Il metodo più comune per bloccare Googlebot è l’utilizzo del file robots.txt. Questo file di configurazione serve a dare direttive ai crawler, e può essere posizionato nella root del sito: tramite apposite regole, consente di limitare l’accesso del bot a determinate pagine o cartelle. Ad esempio, potrebbe essere utile bloccare la scansione di pagine contenenti informazioni sensibili, come dashboard di amministrazione o pagine di login che non desideriamo vengano indicizzate nei risultati di ricerca. Un’attenzione analoga si può dedicare alle pagine duplicate o a quelle che semplicemente non offrono valore per la miglior indicizzazione del sito.
Un altro caso comune in cui possiamo voler bloccare Googlebot è per evitare il crawling su pagine a basso contenuto SEO, come le pagine di ringraziamento dopo una conversione, le pagine di risultati interni o i filtri del nostro shop online. Oltre a non essere rilevanti per il posizionamento, queste pagine possono anche incidere negativamente sul crawl budget , consumando risorse che Googlebot potrebbe destinare a pagine più competitive e strategiche.
Un altro strumento efficace per controllare la scansione di pagine specifiche è l’utilizzo dell’attributo noindex: quando incluso all’interno del codice HTML di una pagina, non impedisce la scansione da parte di Googlebot, ma evita l’indicizzazione dell’URL nel motore di ricerca. In alcuni casi, infatti, il blocco totale mediante robots.txt potrebbe non essere la scelta migliore, perché impedirne la scansione significa anche evitare che Googlebot verifichi eventuali aggiornamenti o novità sulla pagina. Con il tag noindex, al contrario, il bot continua a fare il crawling del contenuto ma evita di inserirlo nei risultati della SERP, una soluzione ideale per pagine che devono rimanere accessibili ma non visibili al pubblico.
Occorre fare attenzione quando si decide di bloccare Googlebot o utilizzare il noindex: se applicati senza una strategia chiara, potrebbero avere conseguenze indesiderate sull’indicizzazione complessiva del sito. Ogni pagina esclusa potrebbe influire sulla visibilità globale del sito, e una configurazione errata potrebbe limitare o addirittura azzerare il traffico organico. Monitorando attentamente i file di log e le performance su Google Search Console prima di implementare blocchi definitivi possiamo garantire che il blocco serva realmente a ottimizzare il percorso di crawling e non a limitarlo.
Dove si può trovare il software spider (chiamato anche crawler)?
Una delle domande più comuni tra chi si avvicina al mondo della SEO e dell’ottimizzazione web riguarda la disponibilità di un tool che possa simulare il comportamento di Googlebot o di altri spider. Infatti, conoscere dove si trova un software spider per analizzare i siti web in modo autonomo, proprio come fa Googlebot, è utile per anticipare eventuali problemi di scansione, indicizzazione o performance del sito.
Oggi esistono diversi software spider accessibili e scalabili, in grado di eseguire funzioni molto simili a quelle di Googlebot. Uno strumento largamente utilizzato dai SEO specialist è Screaming Frog SEO Spider. Questo software, scaricabile ed eseguibile su diversi sistemi operativi, è in grado di scansionare moltissime pagine di un sito web per generare rapporti molto dettagliati su eventuali errori tecnici, link rotti, ridondanze di URL e metadati assenti. Screaming Frog offre una simulazione del crawl simile a quella di Googlebot, permettendoci di individuare facilmente eventuali lacune nel nostro sito e correggerle prima ancora che il bot di Google lo visiti.
In alternativa, possiamo citare anche Sitebulb e DeepCrawl, senza dimenticare ovviamente il nostro SEO Spider, che scansiona un sito seguendo i link presenti tra le pagine proprio come fa Googlebot. Lo spider di SEOZoom è uno strumento completo e potente per effettuare un audit approfondito delle pagine, evidenziando errori, collegamenti non funzionanti, file bloccati o aspetti che impediscono una corretta indicizzazione delle risorse.
Ampliando l’utilizzo di questi strumenti SEO, può diventare molto più semplice rilevare e risolvere problemi tecnici che altrimenti potrebbero passare inosservati fino a una scansione compromessa di Googlebot, assicurando che il nostro sito sia sempre nelle condizioni ottimali per il crawling e l’indicizzazione da parte di Google.
Come gestire Googlebot: la guida ufficiale con indicazioni e best practices
Vista la delicatezza di questi aspetti e per evitare errori che potrebbero compromettere una corretta indicizzazione o scansione delle pagine, è quanto mai opportuno fare riferimento alle indicazioni della guida ufficiale di Google per perfezionare la comunicazione tra il nostro sito e Googlebot. Qui riprendiamo quindi i consigli chiave direttamente dai documenti tecnici di Google, mirati a migliorare la gestione del crawler e garantire che le pratiche adottate siano conformi agli standard suggeriti.
Googlebot si suddivide in due tipologie: il più utilizzato è Googlebot Smartphone, che simula un utente mobile, seguito dal Googlebot Desktop, che simula la navigazione da computer desktop. Entrambi i crawler seguono le stesse direttive dal file robots.txt, quindi non è possibile distinguere tra mobile e desktop nella gestione di queste direttive, anche se possiamo comunque identificare il tipo di accesso esaminando lo user-agent nelle richieste HTTP.
Frequenza di accesso e gestione della larghezza di banda
Googlebot è progettato per accedere al sito in modo efficiente, principalmente da IP situati negli Stati Uniti. Ogni scansione punta a ridurre al minimo l’impatto sulle prestazioni del server, e per farlo vengono utilizzate contemporaneamente migliaia di macchine distribuite in tutto il mondo, così da migliorare le prestazioni e seguire il ritmo di crescita del Web. Inoltre, per ridurre l’utilizzo di larghezza di banda Google esegue molti crawler su computer vicini ai siti che potrebbero sottoporre a scansione.
Di base, la guida segnala che Googlebot non dovrebbe accedere a gran parte dei siti in media più di una volta ogni pochi secondi; per possibili ritardi, tale frequenza potrebbe però risultare leggermente superiore in brevi periodi.
Tuttavia, esistono situazioni in cui la frequenza di accesso del bot potrebbe diventare problematica e sovraccaricare il server. In questi casi, Google offre la possibilità di modificare la frequenza di scansione, riducendola attraverso le impostazioni avanzate del file robots.txt o utilizzando la Google Search Console.
Essenzialmente, il sistema è progettato per distribuire le visite di Googlebot e prevenire il sovraccarico del server, ma è possibile intervenire se si verificano rallentamenti. È inoltre utile sapere che Googlebot può effettuare la scansione anche attraverso HTTP/2, il che può ridurre il consumo di risorse di calcolo (ad esempio CPU, RAM) per il sito e Googlebot, senza però pensare a ripercussioni sull’indicizzazione o il ranking del sito. Nel caso in cui la scansione tramite HTTP/2 non sia desiderata per il proprio sito, è comunque possibile disattivarla tramite una semplice impostazione del server.
Gestire i limiti di scansione di Googlebot
Uno degli aspetti tecnici più rilevanti è il limite di dimensione che Googlebot applica a ogni file HTML o risorsa scansionata. Googlebot esamina solo i primi 15 MB di un file HTML o testo, il che significa che contenuti ubicati oltre questa soglia potrebbero non essere indicizzati. Questo limite non riguarda solo il codice HTML ma anche risorse aggiuntive come immagini, CSS o JavaScript, che vengono recuperate separatamente, anch’esse soggette allo stesso vincolo di limite.
Il consiglio qui è quello di assicurarsi che gli elementi più importanti – tra cui i testi e i link rilevanti per la SEO – vengano presentati entro i primi 15 MB del contenuto per garantire che siano interamente scansionati e indicizzati.
Questo limite, però, non si applica a risorse tipo immagini o video, perché in questo caso Googlebot recupera video e immagini a cui si fa riferimento nell’HTML con un URL separatamente con recuperi consecutivi, come nell’esempio
<img src="https://example.com/images/puppy.jpg" alt="cute puppy looking very disappointed"/> .
Google e 15 MB: cosa significa il limite
Proprio questo riferimento ai 15 MB, apparso ufficialmente per la prima volta a fine giugno 2022, ha scatenato la reazione della community SEO internazionale, costringendo Gary Illyes a scrivere un ulteriore approfondimento sul blog per chiarire la questione.
Innanzitutto, la soglia dei primi 15 megabyte (MB) che Googlebot “vede” durante il recupero di determinati tipi di file non è nuova, ma “è in circolazione da molti anni” ed è stata aggiunta alla documentazione “perché potrebbe essere utile per alcune persone durante il debug e perché cambia raramente”.
Questo limite si applica solo ai byte (contenuti) ricevuti per la richiesta iniziale effettuata da Googlebot, non alle risorse di riferimento all’interno della pagina. Ciò significa, ad esempio, che se apriamo https://example.com/puppies.html, il nostro browser scaricherà inizialmente i byte del file HTML e, in base a tali byte, potrebbe effettuare ulteriori richieste di JavaScript esterno, immagini o qualsiasi altra cosa a cui fa riferimento un URL nell’HTML; Googlebot fa la stessa cosa.
Per la maggior parte dei siti, il limite di 15 MB significa “molto probabilmente niente” perché ci sono pochissime pagine su Internet di dimensioni maggiori ed “è improbabile che tu, caro lettore, ne sia il proprietario, poiché la dimensione media di un file HTML è circa 500 volte inferiore: 30 kilobyte (kB)”. Tuttavia, dice Gary, “se sei il proprietario di una pagina HTML che supera i 15 MB, forse potresti almeno spostare alcuni script inline e polvere CSS su file esterni, per favore”.
Anche i data URIs contribuiscono alla dimensione del file HTML “poiché sono nel file HTML”.
Per cercare le dimensioni di una pagina e capire quindi se superiamo il limite esistono diversi modi, ma “il più semplice è probabilmente utilizzare il browser e i suoi strumenti per sviluppatori”.
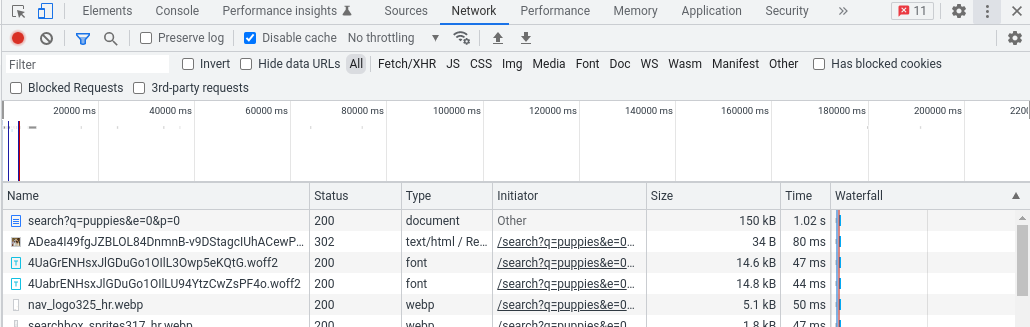
In particolare, consiglia Illyes, dobbiamo caricare la pagina come faremmo normalmente, quindi avviare gli Strumenti per sviluppatori e passare alla scheda Rete; ricaricando la pagina dovremmo vedere tutte le richieste che il browser ha dovuto fare per eseguire il rendering della pagina. La richiesta principale è quella che stiamo cercando, con la dimensione in byte della pagina nella colonna Dimensione.
In questo esempio dagli Strumenti per sviluppatori di Chrome la pagina pesa 150 kB, dato mostrato nella colonna delle dimensioni:
Una possibile alternativa per i più avventurosi è utilizzare cURL da una riga di comando, come mostrato di seguito:
curl
-A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
-so /dev/null https://example.com/puppies.html -w '%{size_download}'Bloccare l’accesso di Googlebot: opzioni e indicazioni per impedire a Googlebot di visitare il sito
Esistono diversi motivi per cui si potrebbe voler impedire a Googlebot di accedere a determinati contenuti, ma è fondamentale comprendere le differenze tra scansione e indicizzazione, come ribadito nella guida ufficiale di Google. Se vogliamo impedire a Googlebot di scansionare una pagina, possiamo utilizzare il file robots.txt per bloccarne l’accesso. Tuttavia, se l’intento è di evitare che una pagina compaia nei risultati di ricerca, si deve ricorrere al tag noindex, dato che bloccare solo la scansione non garantisce che la pagina rimanga fuori dalle SERP.
Altre opzioni per nascondere un sito a Google includono la protezione tramite password per rendere completamente inaccessibili sia agli utenti che ai bot determinate sezioni del sito.
Di fondo, infatti, è quasi impossibile tenere segreto un sito evitando di pubblicare link che vi rimandino. Ad esempio, spiega la guida, non appena un utente segue un link che da questo server “segreto” rimanda a un altro server web, l’URL “segreto” potrebbe essere visualizzato nel tag referrer ed essere memorizzato e pubblicato dall’altro server web nel suo log referrer.
Prima di bloccare Googlebot, però, è importante verificare l’identità del crawler. La guida, infatti, ci avverte che l’intestazione della richiesta HTTP user-agent di Googlebot può essere soggetta a spoofing (falsificazione) da parte di crawler malevoli che cercano di spacciarsi per Google. Pertanto, è consigliabile assicurarci che la richiesta problematica arrivi effettivamente da Googlebot: il miglior modo per farlo è utilizzare una ricerca DNS inversa nell’IP di origine della richiesta oppure far corrispondere l’IP di origine con gli intervalli di indirizzi IP di Googlebot che sono disponibili pubblicamente.
