
Google e AI leggono davvero il tuo sito? Guida completa al rendering
Non puoi posizionare ciò che il motore di ricerca non riesce a vedere. Ci hai mai pensato? Pubblichi una pagina, ottimizzi i meta tag e curi i testi e dai per scontato che Google veda il contenuto esattamente come lo vedi tu. Spesso ti sbagli.
Tra la scoperta dell’URL e il suo posizionamento c’è un passaggio tecnico obbligato, il rendering, ovvero il processo che trasforma il codice sorgente negli elementi visivi della pagina. E se il tuo sito dipende da JavaScript o risorse pesanti, Googlebot può avere difficoltà a eseguire questo passaggio e indicizza ciò che vede. Non il tuo contenuto, il nulla.
È invece nel rendering che istruzioni e componenti diventano una pagina utilizzabile dal motore, ed è da qui che derivano la gerarchia dei contenuti, la loro accessibilità e il peso che ciascun elemento assume nel processo di comprensione. Ed è su questo passaggio che puoi e devi intervenire, se vuoi che Google e le AI vedano davvero ciò che stai pubblicando.
Che cos’è il rendering e cosa significa renderizzare
Il rendering (dall’inglese “to render”, restituire o resa) è il passaggio tecnico che trasforma il codice di una pagina web in una versione interpretabile, in cui risorse, contenuti e struttura assumono un ordine preciso, sulla quale il motore costruisce la propria lettura.
Il termine ha in realtà più significati, perché indica sia una resa grafica lato browser sia un processo più profondo, che riguarda il modo in cui una pagina diventa effettivamente leggibile per un sistema automatico. Nel linguaggio comune i due significati si sovrappongono; nel lavoro sul web no. Qui il rendering non ha a che fare con l’estetica, ma con la trasformazione del codice in contenuto accessibile, strutturato e valutabile.

In informatica, in particolare, rendering indica l’operazione attraverso cui un computer elabora una serie di informazioni codificate per produrre un output sensoriale comprensibile all’utente. È l’atto di traduzione che converte istruzioni matematiche o logiche astratte in pixel, suoni o interazioni concrete. Senza questo passaggio, il web sarebbe solo un archivio illeggibile di stringhe di testo e script incomprensibili.
Quando una pagina dipende da risorse esterne, script o costruzioni dinamiche, ciò che emerge dopo il rendering può differire in modo sostanziale da ciò che è stato progettato. Parti rilevanti possono arrivare tardi, altre risultare secondarie, altre ancora non essere disponibili nel momento in cui il motore deve decidere come interpretare la pagina.
Da qui nasce il problema: la SEO non si gioca sul codice in astratto, ma sulla versione finale che il motore riesce a ricostruire. Nel nostro caso, quindi, si parla di rendering nel contesto web e SEO, per capire come Google vede davvero una pagina e perché questa fase incide in modo diretto sulla comprensione e sulla visibilità dei contenuti.
Cosa significa il rendering web
La distinzione fondamentale che devi fare è tra il codice statico, che risiede passivamente sul server, e la pagina renderizzata, che vive attivamente nel browser. Il file HTML che carichi via FTP è solo un copione teatrale; il rendering è la messa in scena. Se il regista (il browser o il bot) non ha le risorse, il tempo o le capacità per interpretare le istruzioni del copione — specialmente se sono complesse o scritte in un linguaggio dinamico come JavaScript — lo spettacolo non avviene. La pagina resta un potenziale inespresso e, per il motore di ricerca che deve giudicarla, equivale a un palcoscenico vuoto.
Scendendo nel dettaglio tecnico, renderizzare significa eseguire una trasformazione di stato. Il browser riceve dal server una serie di byte grezzi che rappresentano codice (HTML, CSS, JavaScript, immagini, font). Questi byte non hanno alcuna forma intrinseca: non sono “blu”, non sono “in alto a destra”, non sono “interattivi”. È il motore di rendering del browser (come Blink per Chrome o WebKit per Safari) che deve assumersi l’onere di analizzare (parsing) queste istruzioni, costruire una mappa logica delle relazioni tra gli elementi e infine “dipingere” (painting) i pixel sullo schermo del dispositivo.
Ogni volta che un utente visita il tuo sito, il suo dispositivo sta compiendo milioni di calcoli per decidere dove posizionare ogni singola lettera e di che colore colorare ogni pixel. Questo sforzo di calcolo non è gratuito: richiede CPU, memoria RAM ed energia. Quando il sito è costruito con tecnologie moderne che modificano il contenuto in tempo reale tramite JavaScript, il rendering smette di essere un’operazione una tantum e diventa un processo continuo. Il browser non si limita a “leggere” la pagina, ma deve “eseguire” un programma vero e proprio per generare il contenuto. Se questo programma è troppo pesante o mal ottimizzato, il processo di traduzione si inceppa o rallenta, compromettendo l’esperienza finale.
Gli ambiti di applicazione: dal gaming al web rendering
È importante anche non confondere il Web Rendering, di cui ci occupiamo in ambito SEO, con altre forme di elaborazione grafica come il rendering 3D utilizzato nei videogiochi o nella post-produzione cinematografica. Sebbene il principio di base sia lo stesso — traduzione di informazioni in una forma che sia immediatamente accessibile, comprensibile e fruibile per chi ne usufruisce — le finalità e le tecnologie sono radicalmente diverse.
Nell’ambito del design grafico, in particolare, il rendering viene utilizzato per creare rappresentazioni visive altamente realistiche di oggetti tridimensionali. Pensa alla realizzazione degli oggetti nei film d’animazione o nei videogiochi: vengono creati modelli digitali tridimensionali che poi devono essere “renderizzati” per apparire sullo schermo in forma dettagliata, con texture, luci e ombre, in modo quasi indistinguibile dalla realtà. Questo processo richiede algoritmi complessi che trasformano dati grezzi in immagini ad alta risoluzione, e la qualità del rendering può fare la differenza tra un’animazione fluida e immersiva e una grafica che appare artificiale e poco convincente. Il rendering architettonico rappresenta un altro contesto in cui spesso senti usare questo termine: gli architetti creano modelli 3D di edifici e paesaggi, visualizzandoli con alta precisione attraverso software di rendering che aggiungono dettagli come materiali, illuminazione ambientale e persino condizioni climatiche per fornire un’anteprima realistica di come appariranno i progetti una volta costruiti.
Infine, c’è un’applicazione più recente del rendering nel campo dei Big Data e delle visualizzazioni di dati, dove i numeri non forniscono informazioni immediatamente comprensibili se non vengono tradotti in grafici e schemi visivi. Anche in questo caso si compie una “renderizzazione” di dati numerici in forma visiva, permettendo agli utenti (che siano esperti o non esperti) di interpretare e comprendere rapidamente i dati complessi.
Nel gaming, la priorità è la fluidità visiva e il realismo, gestiti principalmente dalla scheda video (GPU). Nel web, la priorità sono la struttura semantica e l’accessibilità dell’informazione, gestite principalmente dal processore (CPU) attraverso la costruzione del DOM (Document Object Model, la struttura logica della pagina).
Quando parliamo di SEO tecnica, ci riferiamo esclusivamente alla capacità degli User Agent (i software che navigano il web, siano essi browser umani o crawler dei motori di ricerca) di completare il ciclo di costruzione della pagina web. Il nostro campo di battaglia non è la risoluzione grafica, ma l’architettura dell’informazione. Dobbiamo garantire che il testo, i link e i metadati — che sono la “carne” del posizionamento — vengano generati correttamente a partire dal codice sorgente. Se un motore di ricerca, che non possiede una scheda grafica potente ma opera in un ambiente simulato e minimalista, non riesce a replicare il processo di Web Rendering, il tuo sito perde la sua funzione primaria di veicolo di informazioni.
Il rischio invisibilità per un sito
Qui arriviamo al cuore del problema che definisce la SEO moderna. Esiste una discrepanza pericolosa, spesso invisibile a occhio nudo, tra ciò che vede un utente umano e ciò che vede un bot. Un utente che naviga con l’ultima versione di Chrome su un computer potente ha a disposizione risorse quasi illimitate per attendere ed eseguire script pesanti. Se una pagina impiega tre secondi per caricare il testo principale tramite JavaScript, l’utente aspetta. Il bot di Google, invece, opera con vincoli di tempo e risorse strettissimi.
Questa asimmetria crea il paradosso dell’invisibilità tecnica. Tu vedi il sito perfettamente funzionante, colorato e ricco di prodotti, perché il tuo browser ha completato il rendering. Googlebot, invece, potrebbe essersi fermato prima che JavaScript iniettasse i contenuti nel DOM, vedendo di fatto una pagina bianca o priva degli elementi essenziali per il ranking.
Per questo parliamo di invisibilità: tecnicamente, il contenuto esiste nel database e viene servito all’utente, ma per il motore di ricerca non è mai stato “materializzato”. Comprendere questo scollamento tra il codice sorgente (ciò che invia il server) e il DOM renderizzato (ciò che vede l’utente) è il primo passo per diagnosticare e risolvere i problemi di posizionamento che nessuna ottimizzazione di keyword potrà mai correggere.
Essenzialmente, quindi, anche se non ti occupi di tecnica e codice devi conoscere almeno superficialmente questo processo perché il rendering è importante e fornisce la verità.
Attraverso il codice, un motore di ricerca può capire di cosa tratta una pagina e approssimativamente quello che contiene. Con il rendering, possono comprendere l’user experience e avere molte più informazioni su quali contenuti dovrebbero avere la priorità.
Durante la fase di resa grafica il motore di ricerca può dare risposta a tante domande rilevanti per comprendere correttamente una pagina e come dovrebbe essere classificata, come ad esempio:
- Il contenuto è nascosto dietro un clic?
- Un annuncio riempie la pagina?
- Il contenuto visualizzato nella parte inferiore del codice viene effettivamente visualizzato nella parte superiore o nella navigazione?
- Il caricamento di una pagina è lento?
La storia e l’evoluzione del rendering
Per comprendere perché oggi ti trovi a dover gestire concetti astrusi come “idratazione parziale” o “resumability” solo per far leggere una pagina a Google, devi fare un passo indietro. La complessità attuale è il risultato di una lunga guerra di potere tra il server e il browser e dell’oscillazione tra due estremi – la potenza di calcolo centralizzata e l’agilità dell’interfaccia utente. E la SEO è sempre stata costretta a rincorrere, cercando di adattarsi a standard che venivano riscritti ogni cinque anni.
Fino ai primi anni 2000, il web era un luogo tecnicamente onesto. Esisteva una sola verità, l’HTML statico. In questa fase, il rendering era un’esclusiva assoluta del server. Quando un utente cliccava su un link, il server macinava i dati, costruiva l’intera pagina e la spediva finita al browser. Il client era un esecutore passivo.
Per noi che facciamo SEO, era il paradiso: ciò che vedeva l’utente era esattamente ciò che vedeva il crawler. Il codice sorgente era trasparente, leggibile, immediato. Il prezzo da pagare era però un’esperienza utente frammentata: ogni interazione richiedeva il ricaricamento completo della pagina, con quella fastidiosa schermata bianca di intermezzo che rompeva il flusso di navigazione.
Tutto è cambiato quando gli sviluppatori hanno deciso di eliminare quell’attesa. Con l’avvento di AJAX prima, e l’esplosione di framework come Angular e React dopo, abbiamo spostato il cervello dell’operazione dal server al dispositivo dell’utente.
È nata l’era delle Single Page Application (SPA). Il server ha smesso di inviare pagine web ed è diventato un semplice distributore di dati grezzi (JSON). Il compito di costruire l’interfaccia, piazzare le immagini e scrivere i testi è stato scaricato interamente sul browser dell’utente tramite JavaScript.
Per la User Experience è stata una rivoluzione – siti fluidi come app native; per la SEO è stata una catastrofe. Improvvisamente, Googlebot si è trovato davanti a gusci vuoti. Il contenuto non c’era più; c’era solo un codice che prometteva di generarlo. È in questo momento storico che è nata la “black box” di JavaScript e la necessità disperata di capire se e quando Google eseguisse gli script.
Ci siamo infatti presto resi conto che il modello SPA puro era insostenibile: i telefoni degli utenti si surriscaldavano per eseguire il rendering e i motori di ricerca perdevano troppi contenuti per strada.
L’industria ha risposto creando i mostri ibridi che usiamo oggi (come Next.js o Nuxt). Siamo tornati a generare l’HTML sul server per accontentare Google (SSR), ma appena la pagina arriva sul browser, le “iniettiamo” tonnellate di JavaScript per renderla interattiva come una SPA.
Questo processo si chiama Idratazione (Hydration) ed è la causa dei tuoi attuali problemi con i Core Web Vitals. Stiamo costringendo il browser a fare il lavoro due volte: prima visualizza l’HTML statico, poi deve ri-eseguire tutto il codice per “agganciare” gli eventi interattivi. È una toppa tecnologica che salva l’indicizzazione, ma spesso uccide la metrica INP (Interaction to Next Paint).
Oggi stiamo finalmente cercando di uscire dalla trappola dell’idratazione. Le nuove frontiere architettoniche puntano alla Resumability (con tecnologie come Qwik): l’idea è che il server faccia tutto il lavoro e invii al browser un’applicazione “messa in pausa“, pronta a riprendere l’esecuzione istantaneamente senza dover scaricare e rileggere tutto il JavaScript.
Parallelamente, il concetto stesso di “server” è evaporato. Con l’Edge Rendering, il rendering non avviene più in un data center lontano, ma viene eseguito frammentato su centinaia di nodi CDN fisicamente vicini all’utente. Il pendolo storico si sta fermando al centro: massima potenza di calcolo (server-side), ma distribuita geograficamente come se fosse locale. Per la SEO, questo è il futuro: velocità istantanea e leggibilità perfetta, senza compromessi.
Le parole chiave del rendering: definizioni e metriche
Prima di scendere in spiegazioni più tecniche, seguendo i consigli degli esperti di web.dev è utile allinearci sulla terminologia precisa che attiene a questo processo, perché confondere una sigla con l’altra oggi significa sbagliare strategia di architettura. Ecco quindi le “parole chiave” essenziali per navigare nel rendering moderno:
- Rendering lato server (SSR, Server Side Rendering). Il server genera l’intera pagina HTML completa prima di inviarla al browser. È la tecnica “storica” che garantisce la massima indicizzazione da parte dei motori di ricerca, poiché il contenuto è subito leggibile, ma richiede un’infrastruttura server potente per gestire il carico di ogni visita.
- Rendering lato client (CSR, Client Side Rendering). Il server invia un “guscio” vuoto e delega al browser dell’utente il compito di scaricare ed eseguire JavaScript per costruire la pagina. Offre un’esperienza fluida simile alle app, ma rischia di mostrare pagine bianche ai bot se il rendering fallisce o va in timeout.
- SSG (Static Site Generation). Le pagine HTML vengono costruite “a freddo” durante la fase di build del sito e salvate come file statici. È l’architettura più veloce in assoluto per il caricamento, ma è rigida: richiede una nuova build completa per aggiornare anche solo un contenuto.
- ISR (Incremental Static Regeneration). La soluzione ibrida che unisce i vantaggi di SSR e SSG. Le pagine vengono servite come statiche (velocissime), ma il server le rigenera e aggiorna in background a intervalli regolari o quando i dati cambiano, garantendo freschezza senza sacrificare le performance.
- ESR (Edge Side Rendering). L’evoluzione moderna del rendering distribuito. La costruzione della pagina non avviene sul server centrale, ma sui nodi della CDN fisicamente più vicini all’utente. Questo azzera la latenza di rete e permette di servire contenuti dinamici con la velocità dello statico.
- Reidratazione (Hydration). È il processo critico in cui JavaScript si “aggancia” a una pagina HTML statica (generata via SSR o SSG) per renderla interattiva. È spesso il momento in cui si creano colli di bottiglia nelle performance percepite dall’utente.
- Prerendering. L’esecuzione di un’applicazione client-side durante la fase di compilazione per catturarne lo stato iniziale come HTML statico. Viene usato come “toppa” per rendere digeribili ai motori di ricerca le Single Page Application che altrimenti sarebbero invisibili.
Dal punto di vista delle prestazioni, le metriche che oggi giudicano la qualità del tuo rendering sono:
- Time to First Byte (TTFB). Il tempo che passa dal clic all’arrivo del primo bit di dati. Se usi SSR e il server è lento, questo valore esplode e penalizza il ranking.
- First Contentful Paint (FCP). Il momento esatto in cui il primo contenuto (testo o immagine) diventa visibile. Se il rendering è bloccato da script o CSS pesanti, l’FCP peggiora drasticamente.
- Interaction to Next Paint (INP). La metrica regina del 2026, che ha sostituito il vecchio FID. Misura la reattività: se l’utente clicca e il sito non risponde perché il browser è impegnato a eseguire (o idratare) JavaScript, l’INP sale e segnala a Google una pessima esperienza utente.
Come avviene il rendering di una pagina web
Il rendering di una pagina web è il risultato di una sequenza di passaggi che inizia nel momento in cui il motore richiede l’URL e termina quando la pagina assume una forma completa e interpretabile. Non è un’operazione istantanea né uniforme: dipende da come la pagina è costruita, da quali risorse utilizza e da quanto la sua struttura è distribuita nel tempo.
Il processo parte dal recupero dell’HTML iniziale. Questa prima risposta contiene la struttura di base della pagina, ma raramente coincide con il contenuto finale. All’interno del codice sono presenti riferimenti a fogli di stile, script e risorse esterne che devono essere caricati ed elaborati prima che la pagina possa essere considerata completa.
Durante questa fase, il motore scarica le risorse necessarie e inizia a eseguire gli script. È qui che molte pagine moderne cambiano forma. Parti del contenuto vengono aggiunte, modificate o riorganizzate in base al risultato dell’esecuzione JavaScript. Elementi che non erano presenti nell’HTML iniziale possono comparire solo a questo punto, mentre altri restano sospesi finché non vengono soddisfatte determinate condizioni.
Il rendering si conclude quando la pagina raggiunge una configurazione stabile, in cui struttura e contenuti risultano disponibili per l’analisi. È questa la “pagina vista da Google”: non una fotografia del codice sorgente, ma una rappresentazione costruita a valle di tutti i passaggi necessari. Se alcuni elementi non vengono caricati o restano inaccessibili, semplicemente non fanno parte di ciò che il motore può interpretare.
Non devi però pensare a un evento unico e istantaneo. Google non garantisce che tutte le risorse di una pagina vengano elaborate nello stesso momento, né che la versione renderizzata sia sempre quella “finale” pensata da chi ha progettato il sito.
In molti casi il motore lavora su una rappresentazione progressiva della pagina. Una prima versione può essere analizzata prima che script complessi vengano eseguiti o che contenuti costruiti dinamicamente diventino disponibili. Se parti rilevanti emergono solo in una fase successiva, non è detto che contribuiscano subito alla comprensione del contenuto.
Questo significa che la pagina valutata può essere una versione intermedia, coerente dal punto di vista tecnico ma incompleta dal punto di vista informativo. È qui che si crea uno scarto difficile da individuare: il contenuto esiste, ma non è presente nel momento in cui il motore deve interpretare la pagina e classificarla.
La fisica del browser: il critical rendering path
Non serve essere ingegneri per vedere la meccanica del rendering in azione, ma basta osservare con attenzione cosa accade sul tuo schermo ogni giorno. Hai mai notato quel micro-istante di bianco assoluto che c’è tra il clic su un risultato e la comparsa della pagina? O quel momento fastidioso in cui vedi il testo ma non puoi cliccare nulla perché il sito è “congelato”?
Quei ritardi non sono casuali. Sono la manifestazione visibile di una legge fisica del web, il critical rendering path.
Il browser non è un visualizzatore magico che mostra la pagina tutta insieme; è un operaio che esegue ordini in una sequenza rigida e obbligata. Non può passare alla fase successiva se non ha completato quella precedente. Questa catena di montaggio è ciò che determina se il tuo sito sarà veloce, lento o addirittura invisibile.
La pipeline critica e la costruzione dell’albero di rendering
Il primo lavoro del browser è puramente strutturale. Appena riceve i dati dal server, deve trasformare quel codice grezzo in qualcosa che abbia una forma logica.
Inizia leggendo l’HTML per costruire il DOM (Document Object Model). Puoi immaginarlo come l’ossatura della pagina: il browser capisce che c’è un titolo, un paragrafo e un’immagine, e definisce come sono imparentati tra loro, eseguendo una tokenizzazione per trasformare i tag in nodi di un albero gerarchico. Il DOM è una struttura indipendente dallo stile: contiene tutti gli elementi della pagina, anche quelli che visivamente non dovrebbero apparire, ma resta uno scheletro nudo e invisibile.
Parallelamente, deve leggere le istruzioni grafiche per creare il CSSOM (CSS Object Model), che riporta l’aspetto grafico degli elementi, come i colori, i margini e i font. Questo è il “vestito”: dice al browser che quell’ossatura deve essere alta tot pixel, colorata di blu e posizionata a destra.
Qui nasce il primo grande collo di bottiglia: il browser non disegnerà mai un pixel finché non avrà unito scheletro (DOM) e vestito (CSSOM) in un’unica mappa chiamata Render Tree, che è la struttura definitiva che guida il browser nelle fasi successive di layout e disegno. La regola tecnica da memorizzare è che il Render Tree include esclusivamente ciò che è visibile, e che il CSS è una risorsa “bloccante; se un nodo nel DOM possiede una regola CSS che lo nasconde, quel nodo viene escluso dall’albero di rendering. Oppure, se il tuo server è lento a inviare i fogli di stile, stai costringendo l’utente (e il bot) a fissare il vuoto, anche se il testo HTML è già stato scaricato interamente.
Questo ha implicazioni dirette sull’indicizzazione: sebbene Googlebot legga il codice sorgente, i contenuti esclusi dal Render Tree hanno un peso semantico nullo o drasticamente inferiore, poiché il motore è programmato per ignorare ciò che l’utente non vede.
Main thread e JavaScript, il collo di bottiglia
Una volta pronta la mappa, bisogna costruire la pagina vera e propria. Il browser deve calcolare la geometria esatta (layout) e infine colorare i pixel (paint). Mentre HTML e CSS vengono processati in modo relativamente fluido, JavaScript rappresenta l’interruzione brutale di questo flusso. Viene definito “parser blocking” perché la sua scoperta costringe il browser a fermare tassativamente la costruzione del DOM. Quando il parser incontra un tag script, deve sospendere ogni altra operazione, scaricare il file, compilarlo ed eseguirlo prima di poter riprendere a leggere il resto della pagina.
Il problema si aggrava a causa dell’architettura a binario unico dei browser. La quasi totalità del lavoro avviene sul Main Thread, un unico canale di elaborazione dove devono passare il parsing dell’HTML, il calcolo degli stili, l’esecuzione degli script e la gestione degli input dell’utente. Se servi a Googlebot un bundle JavaScript monolitico, stai saturando questo unico canale.
Googlebot utilizza il motore V8 per compilare ed eseguire il codice. Questa operazione ha un costo di CPU elevatissimo rispetto alla semplice decodifica di un’immagine o di un testo. Se il Main Thread rimane bloccato per secondi a causa di uno script di tracciamento o di un framework non ottimizzato, il crawler potrebbe decidere di interrompere il processo per risparmiare risorse, lasciando la pagina indicizzata solo parzialmente. I browser moderni tentano di mitigare il problema con il Preload Scanner, un processo leggero che scansiona il documento in avanscoperta per scaricare risorse critiche in background, ma questo non risolve il blocco causato dall’esecuzione effettiva del codice.
È qui che la SEO tecnica moderna si gioca la partita. Quando il browser incontra un file JavaScript, deve fermare tutto il resto: blocca la costruzione della pagina, scarica lo script, lo compila e lo esegue. Finché JavaScript occupa la corsia, il browser è paralizzato: non disegna, non risponde ai clic e non scorre. Se i tuoi script sono pesanti, la pagina rimane bianca o bloccata. Per Googlebot questo è un segnale di allarme rosso: se l’esecuzione richiede troppe risorse, il bot interrompe il lavoro e se ne va prima che il contenuto vero e proprio sia apparso.
Come funziona il Web Rendering Service di Google
Dimentica l’idea romantica di Googlebot che “naviga” il tuo sito come farebbe un utente umano, apprezzandone il design o le animazioni. La realtà industriale è molto più fredda e orientata all’efficienza. Google deve scansionare centinaia di miliardi di pagine ogni giorno e, per farlo su questa scala, non può utilizzare browser desktop completi per ogni singolo URL, ma si affida a un’infrastruttura massiva chiamata Web Rendering Service (WRS).
Il WRS si basa su una versione headless di Chromium. “Headless” significa letteralmente “senza testa”: è un browser Chrome a tutti gli effetti, capace di eseguire JavaScript e layout moderni, ma privo dell’interfaccia grafica. Non “vede” i colori per il piacere estetico, ma calcola la posizione dei pixel solo per capire se un elemento è visibile o nascosto, se un link è cliccabile o coperto da un pop-up.
Il cuore del sistema è Blink, il motore di rendering che gestisce il layout e il disegno dei pixel. È lo stesso motore che trovi su Chrome, Edge e Opera. Se il tuo sito ha problemi di visualizzazione su Safari (che usa WebKit), a Google non importa; ma se il rendering fallisce su Chrome/Blink, il tuo sito è invisibile per il ranking. Ancora più importante è V8, che compila ed esegue il JavaScript. È il motore più performante sul mercato, ma ha limiti fisici precisi. Se il tuo codice è scritto male e manda in loop la CPU, V8 interromperà l’esecuzione per proteggere le risorse del crawler.
Questo sistema è progettato con un unico obiettivo: estrarre informazioni spendendo la minor quantità possibile di energia.
Risorse limitate e render budget
La differenza tra il tuo computer e il WRS è la potenza disponibile. Mentre il tuo PC può dedicare gigabyte di RAM e processori multi-core per caricare un sito pesante, l’istanza di Googlebot che visita la tua pagina ha risorse assegnate col contagocce. Immagina che il bot stia navigando con le capacità di uno smartphone economico di fascia media di qualche anno fa.
Questo introduce il concetto di render budget. Google assegna a ogni pagina una quantità finita di tempo e potenza di calcolo: se il tuo codice JavaScript è inefficiente, crea loop infiniti o richiede troppi secondi per essere elaborato, il WRS taglia la corrente. Interrompe l’esecuzione dello script per risparmiare risorse e passa all’URL successivo. Il risultato per te è disastroso: il bot indicizza solo ciò che è riuscito a renderizzare fino a quel momento. Se il tuo contenuto principale, i prodotti correlati o i prezzi venivano caricati proprio da quello script interrotto, per Google semplicemente non esistono.
La coda di rendering – render queue
Storicamente, si credeva che Google indicizzasse l’HTML subito e il JavaScript dopo settimane (le famose “due ondate”). Oggi Google ha ridotto drasticamente questa latenza, ma la distinzione tecnica rimane e diventa critica nei momenti di alto traffico o per siti molto grandi.
Quando Googlebot scopre un URL, esegue una scansione immediata del codice HTML grezzo (quello che invia il server). Se trova i contenuti qui, tutto bene. Ma se rileva che la pagina è vuota e dipende da JavaScript per mostrare il testo, deve mettere l’URL in una Render Queue, una vera e propria sala d’attesa, dove resta finché il WRS non ha risorse libere per processarla. Questo significa che tra il momento in cui Google sa che la tua pagina esiste e il momento in cui vede cosa c’è scritto, può passare del tempo.
Il rischio odierno non è tanto il ritardo, quanto il timeout. Se durante l’esecuzione lo script impiega troppo tempo o genera errori, il WRS taglia il processo e indicizza solo quello che ha visto fino a quel momento. Per un sito JS-heavy, questo significa spesso finire nell’indice con una pagina bianca o priva dei link di navigazione. Per un sito di news che deve essere indicizzato in minuti, o un ecommerce che cambia prezzi velocemente, finire nella coda di rendering è un rischio commerciale enorme: il tuo contenuto è online per gli utenti, ma invisibile o obsoleto per il motore di ricerca.
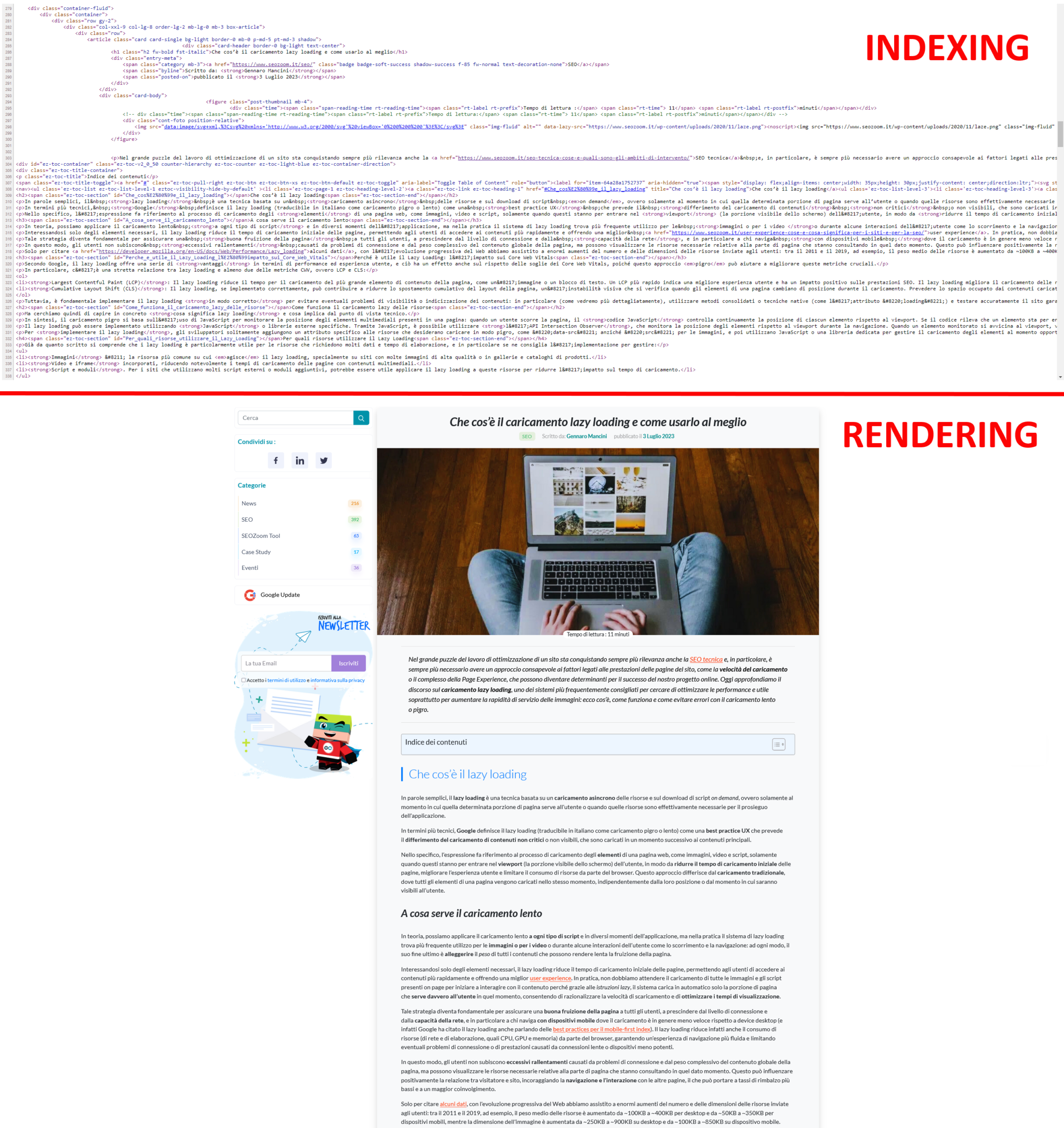
Questo accade per un motivo “semplice”, che ti risulta chiaro ed evidente guardando le due immagini qui sotto: in alto vedi le righe di codice HTML di una pagina del nostro blog, mentre in basso c’è la rappresentazione grafica della stessa pagina così come visualizzata nel browser. In sostanza, si tratta dello stesso contenuto, dapprima mostrato per come appare durante l’indicizzazione (HTML) e poi per come viene reso nel rendering (Chrome). E quindi, puoi considerare il rendering il processo in cui Googlebot recupera le pagine del tuo sito, esegue il codice e valuta i contenuti per comprenderne il layout o la struttura. Tutte le informazioni raccolte da Google durante il processo di rendering vengono quindi utilizzate per classificare la qualità e il valore dei contenuti del sito rispetto ad altri siti e a ciò che le persone cercano con Ricerca Google.
Il rendering secondo Google: l’analogia con le ricette
Per comprendere meglio come Google gestisce il rendering, pensa a ciò che avviene quando prepari una ricetta, riprendendo un’analogia ideata dal Googler Martin Splitt.
La prima onda di indicizzazione di Google è come leggere la lista degli ingredienti di una ricetta: dà a Google una visione generale di ciò che la pagina contiene. Tuttavia, come quando si legge una lista di ingredienti, non ottiene l’immagine completa del piatto finito.
Ecco dove entra in gioco la seconda onda di indicizzazione di Google, che è come seguire i passaggi della ricetta per effettivamente preparare il piatto. Durante questa seconda onda, Google esegue JavaScript per “preparare” la pagina e visualizzare i contenuti basati su JavaScript. Tuttavia, proprio come la preparazione di una ricetta può richiedere tempo, anche la seconda onda di indicizzazione di Google può richiedere tempo, a volte giorni o settimane.
Nell’ottica della SEO, il rendering è fondamentale perché determina come e quando i contenuti del sito vengono “serviti” a Google e, di conseguenza, come e quando appaiono nei risultati di ricerca. Se parti del “piatto” (ovvero il sito web) sono basate su JavaScript e quindi richiedono la seconda onda di indicizzazione di Google per essere “preparate”, potrebbero non essere immediatamente visibili nei risultati di ricerca.
Per assicurarti che il “piatto” sia pronto per essere servito non appena Google legge la “lista di ingredienti”, puoi utilizzare tecniche come il rendering lato server (SSR) o il prerendering, che preparano in anticipo la pagina, generando una versione statica che può essere facilmente “degustata” da Google durante la sua prima onda di indicizzazione.
Inoltre, proprio come un cuoco farebbe dei test di assaggio durante la preparazione di un piatto, dovresti testare regolarmente il sito con strumenti come Google Search Console per assicurarti che Google sia in grado di “assaggiare” e indicizzare correttamente i contenuti.
Il rendering nell’era dell’AI e della GEO
L’ottimizzazione del rendering ha assunto una nuova urgenza con l’avvento della GEO (Generative Engine Optimization) e la diffusione di motori di risposta basati sull’Intelligenza Artificiale (come SearchGPT, Perplexity o le stesse AI Overview di Google). Se fino a ieri il tuo obiettivo era convincere un crawler classico a indicizzarti, oggi devi convincere un LLM (Large Language Model) a leggerti e citarti. E questi nuovi “utenti sintetici” sono ancora più esigenti in termini di pulizia del codice e velocità di esecuzione, perché operano con una finestra di tolleranza ancora più ridotta rispetto a Googlebot.
I sistemi RAG (Retrieval-Augmented Generation) devono scansionare, comprendere e rielaborare l’informazione in tempo reale per rispondere all’utente che sta aspettando in chat. Mentre Google può permettersi tecnicamente di mettere una pagina in coda e tornare dopo qualche minuto, un motore AI che deve rispondere adesso non ammette latenze. Se il tuo contenuto dipende da JavaScript pesanti e non è immediatamente disponibile nel DOM iniziale, l’AI lo scarta come “rumore” e passa alla fonte successiva, escludendoti dalla conversazione prima ancora che inizi.
Machine readability e token economy
C’è un aspetto economico che spesso sfugge: leggere codice costa. I modelli linguistici “pagano” l’elaborazione delle informazioni in token. Una pagina pesante, sporca di JavaScript inutile o che richiede rendering complesso, consuma più token per essere decifrata. I motori di ricerca AI sono progettati per massimizzare l’efficienza: preferiscono fonti che offrono un’alta densità informativa con un basso costo di estrazione.
Un sito ottimizzato con rendering lato server (SSR) o statico (SSG) offre all’AI un “pasto pronto”: testo pulito, strutturato, immediatamente digeribile. Al contrario, un sito in CSR costringe il modello a simulare un browser, eseguire script e attendere il caricamento, aumentando esponenzialmente il costo computazionale dell’acquisizione del dato. Nella logica della GEO facilitare il rendering significa abbattere le barriere d’ingresso per gli algoritmi, aumentando le probabilità che il tuo contenuto venga scelto come fonte autorevole per costruire la risposta sintetica.
Il rischio allucinazione sui contenuti dinamici
Il pericolo più subdolo del cattivo rendering nell’era AI è l’allucinazione o l’interpretazione errata. Se un LLM tenta di leggere la tua pagina ma il rendering JavaScript fallisce parzialmente, potrebbe trovarsi di fronte a frammenti di testo incoerenti, variabili non popolate o placeholder vuoti (ad esempio, leggendo {{prezzo_prodotto}} invece di 100€).
A differenza del vecchio Googlebot che avrebbe semplicemente ignorato la pagina, un modello generativo potrebbe tentare di “riempire i buchi” basandosi sulla probabilità statistica, inventando di fatto informazioni che non esistono sul tuo sito, oppure potrebbe associare il tuo brand a dati errati. Garantire un rendering robusto e deterministico assicura che l’AI legga esattamente ciò che hai scritto, proteggendo l’integrità del tuo messaggio e la reputazione del brand nelle risposte automatiche.
Le architetture di rendering: strategie e costi
Una volta compresa la meccanica del browser e i limiti di Google, devi prendere una decisione strategica: quale architettura utilizzare per il tuo progetto? Al di là dell’aspetto puramente tecnico, questa diventa una decisione di business che determina chi pagherà il “conto” computazionale del rendering. Ogni architettura sposta il carico di lavoro — e quindi il costo in termini di tempo ed energia — su un attore diverso: il tuo server, il dispositivo dell’utente o il bot del motore di ricerca.
Essenzialmente, hai davanti tre opzioni: scaricare questo costo sul tuo server (pagando in infrastruttura), scaricarlo sull’utente (rischiando che il suo dispositivo sia lento) o tentare di scaricarlo su Google (sperando che il bot abbia tempo e voglia di farlo).
Scegliere l’architettura sbagliata significa sabotare la tua SEO alla base, perché la dinamica che abbiamo appena descritto assume contorni critici quando il “visitatore” non è un umano con un iPhone di ultima generazione, ma il crawler di un motore di ricerca che deve scansionare miliardi di pagine al giorno con risorse limitate. Se affidi tutto il lavoro al client (Googlebot) sperando che abbia le risorse per farlo, stai scommettendo la tua visibilità su una variabile che non controlli – chiedi al motore di ricerca di investire le proprie risorse CPU per costruire la tua pagina prima ancora di sapere se merita di essere indicizzata. È una scommessa asimmetrica dove il banco vince sempre: se il costo di rendering supera la soglia di tolleranza o il budget assegnato al tuo sito, Google taglia i fondi. Il processo viene terminato, la pagina resta bianca e il contenuto invisibile.
Al contrario, se sposti tutto sul server, guadagni in sicurezza di indicizzazione ma devi essere pronto a sostenere costi infrastrutturali più alti e a gestire potenziali rallentamenti nella risposta iniziale. Non esiste la soluzione perfetta in assoluto, esiste solo quella più adatta ai tuoi obiettivi di posizionamento e al tipo di contenuto che offri.
La stabilità del server-side rendering
Il Server-Side Rendering è l’approccio classico e, dal punto di vista SEO, il più conservativo e sicuro – se la tua priorità è la certezza assoluta dell’indicizzazione, questa è l’unica strada percorribile. In questa configurazione, quando arriva una richiesta il server esegue tutto il lavoro pesante: interroga il database, elabora la logica, popola il template e confeziona una pagina HTML completa e pronta all’uso.
Il browser (o Googlebot) riceve un documento che contiene già tutto il testo, i link e i metadati significativi fin dal primo byte, nel payload iniziale, senza dover attivare il motore JavaScript V8 per scoprire di cosa parla la pagina o quali sono i link interni.
Il vantaggio strategico è l’eliminazione del rischio di rendering lato client. Googlebot non deve attendere o eseguire script complessi per capire di cosa parla la pagina; l’informazione è lì, immediata e accessibile. Questo massimizza la scansionabilità e garantisce che il contenuto venga indicizzato rapidamente.
L’altro lato della medaglia è che il server deve generare una nuova pagina per ogni singola richiesta, per cui il sistema diventa vulnerabile ai picchi di traffico e alle inefficienze del database – e se hai molto traffico o query complesse al database, il server potrebbe impiegare qualche istante prima di iniziare a inviare i dati, rallentando la percezione iniziale di velocità. Un backend lento si traduce immediatamente in un alto Time to First Byte (TTFB), creando un paradosso in cui il contenuto è teoricamente leggibile ma il bot riduce la frequenza di scansione perché il server risponde troppo lentamente, interpretando il ritardo come un segnale di sofferenza infrastrutturale.
Il debito tecnico del client-side rendering
Il Client-Side Rendering (CSR) rappresenta l’estremo opposto, dove il server si limita a inviare un contenitore vuoto (spesso una pagina bianca con un solo script) e delega la costruzione dell’interfaccia al browser.
È lo standard di molte applicazioni web moderne basate su framework come React, Angular o Vue. Sebbene garantisca una navigazione fluida per l’utente umano, per un crawler rappresenta un ostacolo formidabile. Stai chiedendo a Googlebot di fare il lavoro sporco, di completare l’esecuzione del codice senza errori e entro il timeout: se il WRS non ha risorse sufficienti, se lo script va in timeout o se c’è un errore JavaScript, la pagina rimane bianca. Non esiste una versione HTML di backup.

Sebbene Google sia diventato molto bravo a eseguire JavaScript, affidarsi al CSR puro per pagine che devono posizionarsi (come articoli di blog o schede prodotto) è un azzardo inutile. I dati di campo mostrano che il CSR introduce una volatilità inaccettabile per le pagine critiche di business. Se uno script fallisce l’esecuzione, magari per un’eccezione non gestita o per l’esaurimento della memoria allocata al bot, la pagina muore. Inoltre, il CSR dilata i tempi di scoperta dei nuovi contenuti: Google deve scansionare l’URL, metterlo in coda per il rendering, eseguirlo e solo allora può trovare i nuovi link da seguire. Questo ritardo strutturale rende il CSR inadatto a siti di news o ecommerce che necessitano di un’indicizzazione rapida.
È invece la scelta perfetta per aree riservate, dashboard utente o strumenti SaaS dove l’indicizzazione non serve e si privilegia l’interattività fluida simile a un’app nativa.
Le soluzioni ibride e le evoluzioni di SSG, ISR ed Edge
Per superare la dicotomia tra “server lento” e “client rischioso”, l’ingegneria web (specialmente con l’architettura JAMstack) ha sviluppato modelli ibridi che cercano di disaccoppiare il tempo di rendering dal tempo di richiesta.
La Static Site Generation (SSG) sposta il rendering in un momento ancora precedente, la fase di compilazione (build); il server genera tutte le pagine HTML possibili prima ancora che l’utente arrivi sul sito, creando file statici che azzerano il carico CPU in tempo reale. Quando arriva la richiesta, il file è già pronto per essere servito istantaneamente. È la perfezione in termini di velocità e sicurezza SEO, ma è rigida: se cambi un prezzo o correggi un testo, devi ricostruire l’intero sito, e ciò è dannoso soprattutto se gestisci grandi volumi di dati.
L’evoluzione dinamica è la Incremental Static Regeneration (ISR), pensata innanzitutto oper progetti complessi. Questa tecnologia permette di servire pagine statiche (veloci e sicure per il bot) ma di rigenerarle in background a intervalli regolari o quando i dati cambiano. In pratica, ottieni la sicurezza dell’SSR (Google vede HTML puro) con la velocità dello statico, senza dover ricostruire il sito per ogni virgola modificata.
La frontiera più avanzata, l’Edge Rendering, sposta ulteriormente l’esecuzione dai server centralizzati ai nodi periferici di un CDN. Questo permette di personalizzare il contenuto dinamicamente senza la latenza del server di origine e senza i rischi del rendering client-side, poiché al bot viene comunque consegnato un HTML già renderizzato e pronto per l’indicizzazione.
Errori comuni con il rendering e pattern di programmazione ostili ai motori di ricerca
Esiste una divergenza strutturale tra le best practice dello sviluppo frontend moderno e i requisiti rigidi di scansionabilità richiesti da un crawler. Mentre l’ecosistema JavaScript, guidato da framework come React o Angular, spinge verso l’astrazione e la gestione degli stati lato client per massimizzare la reattività dell’interfaccia, Googlebot necessita di punti di ancoraggio statici e dichiarativi per poter navigare la struttura. Questo conflitto genera un paradosso frequente: siti web tecnicamente ineccepibili, privi di bug funzionali e velocissimi per l’utente umano, risultano completamente invisibili o “piatti” agli occhi del motore di ricerca.
Il problema risiede nell’utilizzo di logiche imperative per gestire funzioni che dovrebbero essere dichiarative. Quando uno sviluppatore sostituisce la struttura semantica dell’HTML (che spiega cosa è un elemento) con istruzioni JavaScript (che spiegano cosa fare quando ci si interagisce), sta costruendo un labirinto di cui Google non possiede la chiave d’accesso. Il crawler è programmato per estrarre informazioni dalla struttura del documento; se questa struttura viene rivelata solo dopo l’esecuzione di eventi complessi, il flusso di autorità tra le pagine si interrompe. Non si tratta di semplici errori di codice, ma di pattern architetturali che sabotano la scoperta dei contenuti, sprecando il crawl budget su risorse che non portano a pagine indicizzabili.
Interruzione del grafo di link interni
L’errore più diffuso e devastante nelle Single Page Application è la simulazione della navigazione attraverso eventi JavaScript. Per comodità o per gestire transizioni animate, gli sviluppatori tendono a utilizzare elementi generici come div, span o button associati a listener onclick per modificare la rotta e caricare nuovi contenuti senza ricaricare la pagina.
Sebbene l’utente percepisca questo comportamento come un normale come un cambio di URL, per Googlebot quell’elemento è un vicolo cieco. Il crawler costruisce il grafo del sito seguendo esclusivamente i tag ancora standard con un attributo href valido. Qualsiasi altra forma di navigazione viene ignorata durante la costruzione della mappa dei link.
Per visualizzare l’errore, osserva la differenza sintattica tra un comando imperativo e un riferimento semantico.
- Il pattern invisibile (Bad Practice)
<div class=”button-nav” onclick=”window.location.href=’/prodotti/scarpe'”>
Scopri la collezione
</div>
In questo caso, il crawler vede solo un contenitore generico (div) con del testo. L’istruzione di navigazione è nascosta dentro un evento JavaScript che il bot non attiva per scoprire URL.
- Il pattern scansionabile (Good Practice)
<a href=”/prodotti/scarpe” class=”button-nav”>
Scopri la collezione
</a>
Quando uno sviluppatore utilizza un pattern come <div onclick=”window.location.href=’/prodotti'”>…</div>, sta istruendo il browser su come reagire a un clic, ma non sta dichiarando l’esistenza di una relazione tra due pagine. Per Googlebot, quel div è un contenitore inerte privo di destinazione, poiché il motore non esegue azioni speculative come cliccare su ogni elemento della pagina per vedere se succede qualcosa. Al contrario, l’utilizzo del tag semantico <a href=”/prodotti”>…</a> crea un arco esplicito nel grafo del sito. Anche se l’interazione viene poi intercettata via JavaScript per gestire una transizione fluida (comportamento tipico delle Single Page Application), la presenza dell’attributo href garantisce che il percorso esista nel DOM statico. Questo permette al crawler di estrarre l’URL e aggiungerlo alla coda di scansione indipendentemente dall’esecuzione o dal fallimento degli script di navigazione, assicurando la continuità del PageRank.
Gestione errata del viewport e delle risorse differite
Il secondo errore riguarda l’implementazione del Lazy Loading, che nasconde insidie critiche se non viene calibrata sul comportamento meccanico del bot. Molte librerie di terze parti attivano il caricamento delle risorse (immagini, ma spesso anche intere sezioni di testo, widget di recensioni o prodotti correlati) intercettando l’evento di scroll fisico dell’utente.
Googlebot non interagisce con la pagina scorrendola come un essere umano. Il Web Rendering Service simula la visualizzazione ridimensionando verticalmente il viewport virtuale (spesso impostato molto alto) per verificare il layout responsive, ma non genera eventi di scorrimento continuo. Se il trigger per il caricamento del contenuto è vincolato strettamente al movimento del mouse o allo scroll attivo, il contenuto differito non verrà mai renderizzato durante la scansione.
È imperativo utilizzare l’API nativa del browser IntersectionObserver o l’attributo HTML standard loading=”lazy”, che sono pienamente supportati e interpretati correttamente dal crawler come segnale per caricare la risorsa senza richiedere interazioni fisiche simulate.
L’implementazione corretta richiede l’uso dell’attributo nativo HTML5 che delega al browser la decisione di caricamento, bypassando librerie di terze parti basate su eventi di scroll.
Un esempio di implementazione nativa (SEO friendly) è
<img src=”prodotto-HD.jpg” loading=”lazy” alt=”Descrizione SEO” width=”800″ height=”600″>
Questo codice è universale. Googlebot lo interpreta correttamente e sa che l’immagine esiste, anche se non la scarica immediatamente. Al contrario, script che iniettano il tag <img> solo al raggiungimento di una coordinata di scroll (window.scrollY > 500) nascondono l’asset al crawler, che vedrà un DOM privo di immagini.
Routing lato client e gestione degli hash URL
La gestione degli URL nelle applicazioni client-side presenta un rischio storico, ancora oggi presente, legato all’uso del cancelletto (hash) per definire le rotte interne. Googlebot ignora sistematicamente tutto ciò che segue il simbolo # in un URL, considerandolo un frammento interno alla pagina stessa (anchor link) e non un indirizzo verso una risorsa distinta.
Se l’architettura del sito affida la navigazione a pattern hash-based (es. sito.com/#/prodotti), il motore di ricerca indicizzerà esclusivamente la radice del sito, sovrascrivendo e ignorando tutte le varianti interne come duplicati della home page.
La soluzione tecnica obbligata è l’adozione della History API, che permette di manipolare l’URL nella barra degli indirizzi creando percorsi virtuali indistinguibili da quelli statici. Questo garantisce che ogni stato dell’applicazione abbia un identificativo unico (URI) che il server può riconoscere e che il crawler può inserire nell’indice separatamente.
Gli ostacoli che uccidono i Core Web Vitals del tuo sito
Dopo aver visto le questioni riguardanti la capacità di Google di trovare i contenuti, affrontiamo un problema diverso: la capacità del browser di mostrarli senza far scappare l’utente. Un rendering inefficiente non ti rende solo invisibile, ti rende lento e instabile. Google penalizza severamente le pagine che richiedono troppa CPU per essere disegnate, colpendo direttamente le metriche Core Web Vitals. Ecco i quattro colli di bottiglia tecnici che devi eliminare dal tuo codice per non sabotare LCP, INP e CLS.
- Il blocco del Main Thread (killer dell’INP)
L’errore più diffuso non è avere “troppo JavaScript”, ma avere “JavaScript che pretende la precedenza”. Il JavaScript bloccante si verifica quando uno script ferma la costruzione dell’HTML per essere scaricato ed eseguito. In quel lasso di tempo, la pagina è congelata – e oggi questo è letale. Se un utente clicca e il browser è impegnato a renderizzare uno script pesante, il ritardo nella risposta viene registrato come un’esperienza negativa grave.
La soluzione operativa:
- Spezza e differisci – usa rigorosamente gli attributi defer o async per tutti gli script non critici. Il browser deve costruire il DOM visivo prima di preoccuparsi del widget della chat o dei tracker di analytics.
- Tree Shaking – elimina il codice morto. Non far scaricare all’utente intere librerie se usi solo una funzione.
- Il layout instabile e le immagini “nude” (killer del CLS)
Il rendering non riguarda solo l’apparizione dei pixel, ma la loro posizione. Se non definisci esplicitamente le dimensioni (width e height) di immagini e banner nel codice HTML, il browser non sa quanto spazio riservare. Risultato? Appena l’immagine viene renderizzata, spinge in basso il testo che l’utente stava già leggendo. Questo genera un CLS (Cumulative Layout Shift) elevato, segnale di scarsa qualità tecnica per Google.
La soluzione operativa:
- Riserva lo spazio – dichiara sempre le dimensioni nel markup o usa aspect-ratio nel CSS. Crea “scatole” vuote che verranno riempite, evitando che il layout balli.
- Formati next-gen – abbandona JPEG e PNG per i formati WebP e AVIF, che offrono una compressione superiore e velocizzano il rendering visivo senza perdere qualità.
- La cascata critica dei CSS (killer del LCP)
Il browser non dipinge nulla finché non sa come dipingerlo. Se il tuo file CSS è enorme (magari perché ti porti dietro tutto il framework Bootstrap non utilizzato), il rendering si blocca in attesa di leggere regole di stile che magari servono solo nel footer. Questo ritarda il LCP.
La soluzione operativa:
- Critical CSS inlining – estrai le regole di stile necessarie solo per la parte visibile dello schermo (above the fold) e inseriscile direttamente nell’HTML (<style>…</style>).
- Caricamento asincrono – tutto il resto del CSS deve essere caricato in background, senza bloccare la visualizzazione immediata del titolo e del testo principale.
- L’Hydration Mismatch nei contenuti dinamici
Per i siti che usano framework come Next.js o Nuxt (SSR/ISR), esiste un rischio subdolo: la discrepanza di idratazione. Succede quando il server invia un HTML statico (versione A), ma il JavaScript che si attiva sul client prova a generare un contenuto diverso (versione B), magari basato su date o preferenze utente locali. Quando questo accade, il browser è costretto a distruggere il DOM appena renderizzato e ricostruirlo da zero. Per l’utente è un “flash” visivo fastidioso; per Google è un segnale di instabilità tecnica e uno spreco di risorse che può portare a ignorare il contenuto dinamico.
La soluzione operativa: assicurati che l’output HTML del server sia identico a quello atteso dal client per il primo paint. Gestisci le variazioni dinamiche (come “Ciao, Gennaro”) solo dopo che l’idratazione è completata, o usa placeholder neutri per evitare il reflow.
Diagnosi e strumenti per smascherare l’invisibilità
La prima regola per chi si occupa di SEO tecnica è una sana diffidenza verso i propri occhi. Tu navighi il sito con un computer potente, connesso a una rete veloce e con un browser che conserva in cache ogni risorsa; vedi le immagini, interagisci con i menu e pensi che tutto funzioni. Ma la tua esperienza non è quella di Googlebot.
Per diagnosticare i problemi di rendering devi smettere di guardare il sito come un utente e iniziare a interrogarlo come un bot. Devi imparare a vedere la discrepanza tecnica tra ciò che il server promette di inviare e ciò che il browser riesce effettivamente a costruire. Solo isolando questa differenza puoi capire se stai perdendo traffico per colpa della qualità dei contenuti o per un’incapacità strutturale del motore di ricerca di vederli.
La tua bussola sono i Core Web Vitals, che possiamo considerare, a tutti gli effetti, metriche di rendering – e LCP e INP sono, in particolare, diagnosi dirette dello stato di sofferenza del Critical Rendering Path. Google non ti penalizza per la “lentezza” astratta, ma perché il browser fatica a convertire il codice in pixel o a liberare la CPU per l’utente.
L’introduzione di queste metriche ha spostato definitivamente l’asse della misurazione delle performance dalla velocità di rete alla salute del rendering. Non stiamo più valutando quanto velocemente il server risponde al ping, ma quanto efficientemente il browser riesce a convertire il codice in un’interfaccia utilizzabile.
Una diagnosi corretta richiede un radicale cambio di mentalità: bisogna smettere di guardare il sito come appare nel browser del proprio computer e iniziare a osservare la differenza tecnica tra ciò che viene inviato dal server e ciò che viene effettivamente costruito dopo l’esecuzione degli script. È in questo delta, spesso invisibile a occhio nudo ma rilevabile dagli strumenti di analisi, che si nascondono i problemi di posizionamento più gravi, come contenuti che spariscono, meta tag che cambiano o link che non vengono generati perché lo script si interrompe prima del completamento.
Analisi differenziale: View Source vs Inspect
Parti da un test manuale, brutale e immediato, che ti dice la verità senza bisogno di software costosi.
Fai clic destro sulla pagina e seleziona Visualizza sorgente (Ctrl+U): quello che vedi è il codice grezzo spedito dal server. Poi apri lo strumento sviluppatori con Ispeziona (F12): quello è il DOM finale, il risultato dopo che JavaScript ha lavorato.
Confrontali sistematicamente. Cerca il tuo H1, la descrizione del prodotto, i link ai correlati o i dati strutturati. Se questi elementi vitali sono presenti nel pannello “Ispeziona” ma mancano (o sono vuoti) nel “Sorgente”, hai individuato il colpevole. Significa che quel contenuto esiste solo se il client ha le risorse per generarlo. Se Googlebot si ferma prima, per lui quella pagina è vuota.
Diagnosi delle performance con LCP e INP
Il rendering non è però solo una questione binaria (visibile/invisibile), ma anche di performance misurabile che impatta direttamente sui Core Web Vitals. Come detto, due metriche in particolare sono figlie dirette delle tue scelte architetturali.
La prima è l’LCP (Largest Contentful Paint), che misura la velocità del rendering visivo; se usi un rendering lato client, il browser deve scaricare ed eseguire lo script prima di mostrare l’elemento principale, peggiorando drasticamente questo valore. E quindi, se non ottimizzi il CSR stai ritardando matematicamente l’LCP, perché costringi il browser a scaricare ed eseguire codice prima di poter dipingere l’immagine principale. Anche un SSR lento (alto TTFB) sposta in avanti il momento in cui il browser riceve il primo byte utile.
La seconda metrica, e più critica, è l’INP (Interaction to Next Paint), che misura il costo del rendering sulla CPU. Il browser ha un unico “binario” per lavorare, il Main Thread. Se questo binario è occupato a “idratare” una pagina complessa in JavaScript, non può ascoltare i clic dell’utente. Un INP alto è il sintomo inequivocabile di un rendering inefficiente che sta paralizzando il dispositivo.
Gli strumenti per fare analisi e debug
Per isolare i problemi di rendering devi usare strumenti che vedono come il bot e che permettono il confronto diretto tra il codice sorgente (Initial HTML) e il codice renderizzato (Rendered DOM).
Il Controllo URL di Search Console è l’unica fonte di verità per capire cosa ha renderizzato Google; analizzando lo screenshot della pagina scansionata e, soprattutto, l’HTML restituito dal test, puoi identificare se il bot si è fermato prima di caricare il contenuto critico.
Quando inserisci un indirizzo e clicchi su “Test Live”, Google lancia un’istanza reale del suo WRS. Non limitarti a guardare la spunta verde “Disponibile”; clicca su “Visualizza pagina testata” e poi su Screenshot. Quella foto è la prova processuale. Se vedi blocchi grigi, aree bianche o layout esplosi, è inutile ottimizzare i meta tag: Googlebot ti sta dicendo che non riesce a renderizzare la pagina. Parallelamente, usa il Rich Results Test come “canarino nella miniera”: i dati strutturati sono spesso gli ultimi a essere caricati via JS. Se il tool non li rileva, significa che il rendering si è interrotto troppo presto (timeout) e che probabilmente manca anche parte del contenuto testuale.
Chrome DevTools ti permette anche di isolare il peso di JavaScript e di vedere quali script bloccano il Main Thread.
- Analisi del blocco di rete. Apri i DevTools (F12), vai nella scheda Network e ricarica la pagina. Filtra per “JS”. Ignora il tempo di download e la somma dei kilobyte trasferiti, che non sono il dato più importante; guarda la colonna “Time” e concentrati sulla latenza di esecuzione visualizzata nella timeline. Se vedi file .js che impiegano centinaia di millisecondi per il download e l’esecuzione (barre verdi e gialle lunghe), hai trovato i colpevoli dell’INP elevato, i responsabili diretti del blocco del Main Thread.
- Copertura del codice. Usa lo strumento Coverage (nel menu “More tools” dei tre puntini in basso) per quantificare lo spreco di risorse. Ricarica la pagina e osserva la barra rossa accanto a ogni file. Quella barra indica la percentuale di codice scaricato ma non utilizzato per il rendering iniziale. Se stai servendo un bundle da 1MB di cui il 70% è rosso (inutilizzato), stai sprecando il render budget di Google per codice morto e funzioni non necessarie per la visualizzazione immediata.
- Simulazione dell’assenza. Vai nelle impostazioni dei DevTools e disabilita JavaScript. Ricarica. Quello che vedi ora è l’esperienza “worst-case” che potrebbe avere un crawler in timeout. Se il menu sparisce, i prodotti scompaiono o il testo diventa illeggibile, il tuo sito non è resiliente e dipende interamente dalla buona volontà del WRS.
Per un’analisi su larga scala che vada oltre la singola pagina, è necessario utilizzare crawler avanzati. Impostando il SEO Spider di SEOZoom in modalità di rendering JavaScript puoi scansionare l’intera struttura del sito simulando il comportamento di un browser reale (basato su Chromium). L’obiettivo dell’audit è rilevare le discrepanze semantiche su tutto il dominio: titoli che cambiano dopo il rendering, tag canonical che vengono iniettati via script o intere sezioni di contenuto che esistono solo nel DOM finale. Queste differenze rappresentano punti di fragilità estrema, dove la visibilità del sito è appesa alla capacità del bot di completare l’esecuzione senza intoppi, un rischio che un progetto solido non dovrebbe mai correre.
Suggerimenti per migliorare il rendering
Una volta identificati i problemi utilizzando questi strumenti, puoi lavorare su soluzioni pratiche per migliorare le prestazioni. Alcuni suggerimenti rapidi includono:
- Ridurre la dimensione delle risorse statiche (immagini, video, file CSS e JavaScript) per velocizzare il rendering.
- Ottimizzare il caricamento delle risorse dinamiche: il lazy loading delle immagini, il differimento degli script e l’esecuzione asincrona delle risorse contribuiranno a migliorare il tempo di caricamento iniziale.
- Implementare il rendering lato server o lo static site generation per migliorare il tempo di caricamento percepito dagli utenti e favorire una migliore indicizzazione da parte di Google.
Comprendere il rendering per esperienze più fluide
La capacità del tuo sito di essere “letto” dalle macchine è il prerequisito biologico per la visibilità.
Puoi avere la strategia di content marketing più raffinata del mondo, ma se la tua architettura tecnica costringe Google a faticare per vedere il tuo lavoro, stai correndo con il freno a mano tirato. Non dare mai per scontato che la visualizzazione umana corrisponda alla comprensione algoritmica. Verifica costantemente le differenze tra sorgente e DOM, scegli un’architettura che minimizzi il rischio lato client e ricorda: la battaglia per il posizionamento si vince prima ancora che l’utente arrivi sulla pagina, si vince nel momento esatto in cui il server risponde.
In definitiva, non lasciare che sia il caso a decidere se Google vede i tuoi contenuti. Scegli l’architettura che minimizza il rischio (SSR o Ibrida), monitora le differenze tra codice sorgente e DOM renderizzato, e ricorda: se Google non riesce a renderizzarlo, per il mercato non esiste.

Risposta alle principali FAQ sul rendering
In conclusione, ecco una lista ragionata di domande frequenti progettata per rispondere ai dubbi reali che bloccano imprenditori e SEO specialist, andando oltre il semplice tecnicismo.
- Cos’è il rendering?
Il rendering è il processo attraverso il quale un browser trasforma il codice di una pagina web (come HTML, CSS, e JavaScript) in elementi visivi che l’utente può vedere e con cui può interagire, come immagini, testo e layout. È la fase che rende visibile il contenuto di un sito direttamente sullo schermo del visitatore.
- Che differenza c’è tra crawling, rendering e indicizzazione?
Sono tre fasi distinte che spesso vengono confuse perché avvengono in sequenza, ma producono effetti diversi. Il crawling serve a scoprire l’URL e scaricare il codice sorgente. Il rendering è il momento in cui quel codice viene elaborato ed eseguito, trasformandosi in una pagina strutturata, con contenuti e gerarchie definite. L’indicizzazione arriva dopo e riguarda ciò che Google ha effettivamente “visto” e compreso a valle del rendering. Se una parte di contenuto emerge solo dopo, o in modo instabile, entra nel processo in forma ridotta o distorta.
- Cosa sono i motori di rendering e quali sono i più famosi per i browser?
Il motore di rendering è il componente software del browser che traduce il codice grezzo in pixel visibili sullo schermo. Senza di lui, il web sarebbe solo una lunga lista di testo incomprensibile.
Oggi il mercato è dominato da tre grandi “famiglie”, e conoscerle è vitale perché se il tuo sito ha un bug su uno di questi motori, stai tagliando fuori una fetta precisa di utenti (e di bot).
- Blink: è il gigante assoluto. Nato come derivazione di WebKit, oggi è il motore di Google Chrome, Microsoft Edge, Opera, Brave e Vivaldi. Se ottimizzi per Blink, copri la stragrande maggioranza del traffico mondiale.
- WebKit: è il guardiano dell’ecosistema Apple. È il motore esclusivo di Safari (sia su macOS che su iOS). Nota tecnica: su iPhone e iPad, tutti i browser (anche Chrome per iOS) sono costretti a usare WebKit sotto il cofano, quindi se un sito si “rompe” su iPhone, è quasi sempre colpa di una mancata ottimizzazione per WebKit.
- Gecko: l’alternativa storica. È il motore open-source sviluppato da Mozilla per Firefox. Resiste come baluardo indipendente contro il monopolio di Blink/Chromium.
- EdgeHTML [Obsoleto]: lo citiamo solo per dovere di cronaca storica. Era il motore proprietario di Microsoft Edge, ma oggi è stato abbandonato, perché Microsoft è passata a Blink per garantire massima compatibilità.
Per la SEO moderna è cruciale sapere che Googlebot e i crawler delle AI (come ChatGPT) usano versioni “headless” di Blink: se il tuo sito ha problemi di rendering su Chrome, sarà matematicamente invisibile anche ai motori di ricerca e alle risposte generative. E quindi, ottimizzare per Blink non significa solo accontentare gli utenti, ma garantire che il tuo contenuto sia leggibile dai nuovi motori di risposta generativa.
- Come funzionano i motori di rendering?
Il lavoro di un rendering engine segue un processo ciclico in tre fasi che trasformano il codice invisibile in esperienza visiva:
- Decodifica degli input (Parsing): il motore preleva il codice sorgente (HTML e CSS) e lo scansiona riga per riga per identificare i “mattoni” della pagina – blocchi di testo, immagini, script e istruzioni di stile.
- Elaborazione dei dati (Construction): rielabora queste informazioni per costruire una mappa logica interna (il Render Tree) che stabilisce non solo cosa deve apparire, ma dove e come (calcolando dimensioni, posizioni, sovrapposizioni e colori).
- Rappresentazione grafica (Painting): infine, collaborando con la GPU (scheda grafica), trasforma questa mappa logica astratta in pixel reali sullo schermo del browser, materializzando la pagina finale che l’utente può consultare.
- Google vede la pagina come la vede l’utente?
No. Google costruisce una rappresentazione funzionale alla comprensione, non una replica fedele dell’esperienza visiva. Il browser dell’utente lavora in tempo reale, con risorse locali, cache, interazioni e fallback progressivi. Googlebot invece opera con priorità diverse, limiti di tempo e una pipeline pensata per classificare, non per navigare. La pagina “vista” dal motore è una sintesi strutturale, non un rendering estetico.
- Il rendering influisce solo sui siti che usano JavaScript?
Il JavaScript amplifica il problema, ma non lo crea da solo. Anche siti apparentemente semplici possono avere criticità di rendering se caricano contenuti in modo asincrono, modificano la struttura della pagina dopo il load iniziale o dipendono da risorse esterne lente. Il punto non è la tecnologia usata, ma quando e come i contenuti diventano disponibili nel flusso di elaborazione.
- Google dice che “sa leggere JavaScript”. Perché devo preoccuparmi?
Google può leggere JavaScript, ma non promette di farlo sempre e subito. Il rendering richiede risorse enormi. Se il tuo sito è piccolo e veloce, probabilmente ti salvi. Ma se hai migliaia di pagine o script complessi, affidarti alla “buona volontà” del WRS (Web Rendering Service) significa accettare che molte tue pagine restino nella coda di rendering per giorni, o vengano ignorate se il timeout scatta prima.
- Googlebot riesce a indicizzare i siti interamente in JavaScript?
Tecnicamente sì, ma non istantaneamente né incondizionatamente. Googlebot esegue il JavaScript utilizzando un’infrastruttura chiamata Web Rendering Service (WRS) basata su una versione headless di Chrome. Tuttavia, a differenza dell’HTML statico che viene letto subito, il JavaScript richiede risorse di calcolo elevate e viene spesso messo in una coda di rendering (Render Queue). Se l’esecuzione dello script richiede troppo tempo, genera errori o supera il render budget assegnato al sito, il processo va in timeout. Il risultato è che Google potrebbe indicizzare solo il guscio vuoto della pagina, ignorando il contenuto generato dinamicamente. Affidarsi ciecamente alla capacità di Google di eseguire tutto il codice è una strategia ad alto rischio.
- Google esegue sempre tutto il JavaScript di una pagina?
No. L’esecuzione degli script dipende da priorità, complessità e risorse disponibili. Alcuni script vengono rimandati, altri eseguiti parzialmente, altri ancora ignorati se non ritenuti essenziali. Questo significa che una pagina può risultare formalmente accessibile ma semanticamente incompleta. Il motore lavora su ciò che riesce a processare in modo affidabile, non su ciò che il sito “intende” mostrare.
- Qual è la differenza tra Server-Side Rendering (SSR) e Client-Side Rendering (CSR) per la SEO?
La differenza risiede in chi sostiene il carico computazionale e, di conseguenza, nel rischio di indicizzazione. Nel Server-Side Rendering (SSR), il server elabora il codice e invia al browser un HTML completo e pronto all’uso; questo garantisce che Googlebot veda immediatamente il contenuto senza dover eseguire script. Nel Client-Side Rendering (CSR), il server invia una pagina vuota e delega al dispositivo (o al bot) il compito di scaricare ed eseguire il JavaScript per costruire l’interfaccia. Il CSR è pericoloso per la SEO perché introduce punti di rottura: se il bot non ha le risorse per completare l’esecuzione, la pagina rimane invisibile. L’SSR è una polizza assicurativa sulla visibilità, mentre il CSR è una scommessa sulle prestazioni del crawler.
- Perché lo strumento “Controllo URL” di Search Console mostra una pagina diversa da quella che vedo nel browser?
Lo strumento “Controllo URL” mostra esattamente ciò che il WRS è riuscito a renderizzare entro i suoi limiti di tempo e risorse. Se vedi discrepanze, come testi mancanti o blocchi vuoti, significa che il processo di rendering si è interrotto prima del completamento. Questo accade spesso perché il tuo browser desktop ha una potenza di calcolo molto superiore a quella assegnata al bot, permettendogli di eseguire script pesanti che invece mandano in crisi il crawler. Quell’immagine parziale in Search Console è l’unica verità che conta per il posizionamento: se il contenuto non c’è lì, per l’algoritmo non esiste.
- L’utilizzo di framework come React o Angular penalizza il posizionamento?
Non è la tecnologia in sé a penalizzare, ma la sua implementazione. I framework moderni tendono a gestire la navigazione e i contenuti tramite logiche client-side che possono oscurare la struttura del sito ai crawler. Problemi comuni includono l’uso di link simulati tramite eventi onclick invece di tag <a> standard (che interrompono il flusso del PageRank) o l’idratazione lenta che peggiora la metrica INP. Se configurati in modalità SSR o utilizzando tecniche di Static Site Generation (SSG) come avviene con Next.js o Nuxt, questi framework possono produrre siti perfettamente ottimizzati. Il problema nasce quando vengono usati in modalità Single Page Application pura senza considerare i requisiti di scansionabilità.
- In che modo il rendering influenza i Core Web Vitals?
Il rendering è la causa tecnica diretta delle performance misurate dai Core Web Vitals. Il Largest Contentful Paint (LCP) misura il ritardo visivo: un rendering lato client sposta in avanti il momento in cui l’utente vede il contenuto principale, peggiorando il punteggio. L’Interaction to Next Paint (INP) misura invece il costo di esecuzione: se il Main Thread del browser è intasato dall’esecuzione di JavaScript pesante (tipico della fase di idratazione), la pagina non può rispondere agli input dell’utente. Ottimizzare il rendering significa liberare la CPU da compiti inutili, migliorando direttamente queste metriche e il ranking correlato.
- Una pagina può essere indicizzata ma male interpretata?
Sì, ed è uno dei casi più comuni. L’URL entra nell’indice, ma il contenuto viene classificato in modo debole perché la struttura emerge in modo confuso, il testo principale arriva tardi o la gerarchia informativa non è chiara. In questi casi la pagina esiste, ma fatica a competere perché non comunica in modo netto il proprio tema centrale.
- Come capire se un problema di posizionamento dipende dal rendering?
I segnali non sono mai isolati, ma ricorrenti. Pagine che faticano a posizionarsi nonostante contenuti solidi, risultati instabili su query coerenti, differenze marcate tra ciò che è visibile all’utente e ciò che emerge nei sistemi di analisi sono indizi da leggere insieme. Quando il contenuto c’è, ma non “passa”, il rendering è spesso parte della spiegazione.
- Il rendering influisce sul Crawl Budget?
Assolutamente sì. Un sito che richiede pesante elaborazione client-side consuma molto più tempo-macchina di Googlebot. Se il bot impiega 500ms per renderizzare una tua pagina invece di 50ms, potrà scansionare molte meno pagine del tuo sito nello stesso arco di tempo. Ottimizzare il rendering (passando a SSR o SSG) è il modo più efficace per aumentare il numero di pagine indicizzate quotidianamente.
- Il mio sito è lento a caricare: significa che ho problemi di rendering?
Non necessariamente, ma spesso sono collegati. Un sito lento per l’utente (LCP alto) suggerisce che il browser sta faticando a processare il codice. Se questa fatica dipende da troppi file JavaScript che bloccano il Main Thread, allora sì: hai un problema di rendering che sta uccidendo sia l’esperienza utente sia la scansionabilità da parte di Google.
- Ho cambiato grafica e il traffico è crollato. Può essere colpa del rendering?
È il sospettato numero uno. Se il redesign ha introdotto framework come React o Angular senza prevedere il Server-Side Rendering (SSR), potresti aver reso il contenuto invisibile ai bot3. Controlla subito se il testo delle nuove pagine è visibile nel codice sorgente (Ctrl+U): se non c’è, Google ha smesso di leggerti.
- Devo per forza abbandonare React o Vue per fare SEO?
No, non devi cambiare tecnologia, devi cambiare architettura8. React e Vue sono eccellenti, ma di default usano il Client-Side Rendering (CSR). Devi configurarli per usare il Server-Side Rendering (con framework come Next.js per React o Nuxt.js per Vue) o la generazione statica. Il problema non è il linguaggio, è chi esegue il codice
- Perché vedo schermate bianche nel “Test Live” di Search Console?
Quello è il segnale definitivo che il rendering sta fallendo10. Significa che le risorse necessarie per disegnare la pagina (spesso file JS o CSS critici) sono bloccate dal robots.txt, sono andate in timeout o richiedono troppa CPU. Finché vedi bianco lì, sei invisibile in SERP.
- I dati strutturati (Schema.org) vanno messi nell’HTML statico?
È la pratica consigliata. Se li inietti tramite JavaScript (ad esempio con Google Tag Manager), funzionano solo se il rendering va a buon fine. Poiché i Rich Snippet sono un vantaggio competitivo enorme, affidarli a un processo incerto è un rischio inutile. Mettili nel codice server-side per avere la garanzia che Google li veda subito.
- Cos’è l’Hydration Gap?
È quel fenomeno fastidioso per cui la pagina sembra caricata (vedi il testo), ma se clicchi su un pulsante non succede nulla per un paio di secondi. Accade quando il browser deve “idratare” l’HTML statico collegandoci gli script interattivi. Per Googlebot non è grave (lui non clicca), ma per i Core Web Vitals (specialmente INP) è devastante e può penalizzarti lato UX.
- Il rendering ha un impatto anche sui sistemi AI di risposta automatica?
Sì, perché quei sistemi lavorano su ciò che riescono a estrarre in modo pulito e coerente. Se il rendering produce una pagina frammentata, con contenuti principali poco stabili o difficili da isolare, la probabilità che quelle informazioni vengano selezionate o sintetizzate diminuisce. La chiarezza strutturale diventa un prerequisito, non un dettaglio tecnico.
- ChatGPT e Perplexity leggono i siti in JavaScript?
Molto peggio di Google. Molti bot AI utilizzano browser headless semplificati per risparmiare costi (token economy) e spesso non eseguono JavaScript complessi. Se vuoi essere citato come fonte nelle risposte generative, fornire un HTML pulito e statico è quasi obbligatorio. L’AI privilegia la leggibilità immediata (Machine Readability)
- I nuovi motori di ricerca basati su AI (come Perplexity o ChatGPT) gestiscono il rendering come Google?
No, sono molto più rigidi. I motori RAG (Retrieval-Augmented Generation) devono leggere e comprendere il contenuto in tempo reale per generare una risposta all’utente. Non dispongono del meccanismo di “coda di rendering” differita che usa Google. Hanno timeout di esecuzione bassissimi, nell’ordine dei millisecondi. Se la pagina non fornisce il contenuto testuale immediatamente (come avviene con SSR o HTML statico), questi bot abbandonano la scansione e scartano la fonte. Un’architettura che richiede secondi per caricare il contenuto via JavaScript taglia fuori automaticamente il sito dalle risposte generate dall’intelligenza artificiale.
- L’Edge Rendering è solo per siti enormi?
Non più. Con servizi come Cloudflare Workers o Vercel, l’Edge Rendering è accessibile a tutti. È particolarmente utile se hai un pubblico internazionale: renderizzare la pagina sul nodo CDN più vicino all’utente (a Milano per un utente italiano, a New York per uno americano) garantisce velocità assurde e un “Time to First Byte” bassissimo, che Google adora.
- Il rendering è un tema tecnico o strategico?
È entrambi, ma con un peso crescente sul lato strategico. Non riguarda solo il funzionamento della pagina, ma la capacità di controllare come il contenuto viene interpretato, classificato e riutilizzato. In un web dove la visibilità passa sempre più dalla selezione e dalla sintesi, governare il rendering significa governare l’accesso al significato.
- Che fine ha fatto il Dynamic Rendering? Conviene ancora usarlo?
Risposta breve: no. Consideralo una toppa, non una strategia.
Risposta completa: fino a qualche anno fa, Google suggeriva il Dynamic Rendering come soluzione tampone per i siti JavaScript pesanti. La logica era semplice: il server riconosceva chi stava visitando il sito (User-Agent Sniffing). Se era un utente umano, serviva il JavaScript complesso (CSR); se era Googlebot, serviva una versione HTML statica pre-renderizzata semplificata.
Oggi, questa pratica è ufficialmente considerata un workaround temporaneo e non una soluzione a lungo termine. I motivi sono tre:
- Complessità e costi. Mantenere due versioni separate del sito (una per gli umani, una per i bot) raddoppia i costi di test e manutenzione.
- Rischio cloaking. Se la versione HTML per il bot differisce troppo da quella per l’utente (magari perché ti dimentichi di aggiornarla), rischi una penalizzazione per cloaking, una delle più “vecchie” tattiche black hat SEO.
- Evoluzione tecnologica. Con l’avvento dell’SSR moderno, dell’ISR e dell’Edge Rendering, non c’è più motivo tecnico per usare questo trucco.
Se hai un sito legacy che usa già il dynamic rendering, non devi spegnerlo domani mattina, ma il tuo obiettivo per il 2026 deve essere migrare verso un’architettura server-side o hybrid nativa. non avviare mai un nuovo progetto oggi basandoti sul dynamic rendering.
