
Caratteri non ASCII e caratteri speciali: cosa sono e come usarli
Nella gestione di un sito la precisione è tutto. Anche i caratteri che digitiamo, che siano parte di un URL o di un meta tag, sono più di semplici simboli: sono mattoni fondamentali della comunicazione online e della SEO. Per questo è importante conoscere cosa sono i caratteri non ASCII e i caratteri speciali ma, soprattutto, quali i rischi comporta un loro utilizzo non corretto per i nostri contenuti. Da un lato, infatti, offrono la possibilità di arricchire i contenuti e di rivolgersi a un pubblico internazionale, grazie alla capacità di rappresentare fedelmente lingue e simboli diversi. Dall’altro, se non gestiti con attenzione, possono però creare ostacoli per l’indicizzazione e l’usabilità. La sfida sta quindi nel bilanciare l’esigenza di espressività con la necessità di mantenere il sito web funzionale e facilmente navigabile.
Caratteri non ASCII: cosa sono i non ASCII characters
I caratteri non ASCII sono tutti quei simboli che rappresentano un’estensione del codice ASCII originale, che include 128 caratteri standard come le lettere dell’alfabeto inglese, i numeri e i simboli di controllo di base.




I caratteri non ASCII non appartengono quindi allo standard codificato e comprendono una vasta gamma di simboli utilizzati nelle lingue di tutto il mondo, inclusi accenti, lettere con diacritici, alfabeti non latini e altri simboli linguistici o culturali, e sono codificati in standard come Unicode per garantire la loro corretta rappresentazione e trasmissione digitale.
In informatica, quindi, la definizione di carattere non ASCII è “carattere che non appartiene all’American Standard Code for Information Interchange (ASCII)”, vale a dire l’insieme di codici di caratteri che vengono normalmente utilizzati per rappresentare lettere, numeri e simboli.
Quali sono i non ASCII carachters
Mentre ASCII comprende 128 simboli, come detto, i non ASCII characters si estendono ben oltre, abbracciando caratteri speciali come le lettere con accenti, glifi, ideogrammi, simboli matematici e alfabeti di lingue da ogni angolo del pianeta.
Ecco alcuni esempi:
- Lettere con Accenti e Diacritici. Come la “è” in francese, la “ñ” in spagnolo, la “ö” in tedesco, e la “ç” in portoghese e francese.
- Alfabeti Non Latini. Come i caratteri cirillici “ж” o “б”, i caratteri greci “α” o “β”, e i caratteri arabi “ح” o “ص”.
- Simboli Matematici Estesi. Come l’infinito “∞”, il simbolo di integrale “∫”, e il simbolo di sommatoria “∑”.
- Simboli Tecnici e Scientifici. Come il simbolo dell’Ohm “Ω”, il simbolo di gradi “°”, e il simbolo di micro “µ”.
- Caratteri Ideografici. Come i caratteri cinesi “汉” o “字”, i caratteri giapponesi “か” o “な”, e i caratteri coreani “한” o “글”.
- Simboli Emoji. Come le faccine “?” o “?”, e altri simboli come “?” o “?”.
Questi caratteri sono codificati in standard come Unicode, che può includere oltre 140.000 simboli diversi, per garantire che ogni lingua e sistema di scrittura sia rappresentato e possa essere utilizzato nella comunicazione digitale globale. Unicode è diventato lo standard de facto per la codifica dei caratteri non ASCII, consentendo una vasta interoperabilità tra diverse piattaforme e sistemi operativi. Grazie a questo sistema, è possibile visualizzare e scambiare testi in una moltitudine di lingue e simboli, mantenendo l’integrità dei dati e la comprensione tra utenti di tutto il mondo e tutte le lingue.
A cosa servono i caratteri non ASCII
A differenza della codifica standard ASCII, che include solo caratteri alfanumerici e simboli come il punto e la virgola, i non ASCII characters sono quindi un elenco molto più ampio di caratteri speciali che include segni accentati, glifi, ideogrammi, lettere cirilliche, simboli matematici, simboli di valute e altro ancora.
I non ASCII characters sono usati in molti moderni linguaggi di programmazione, come HTML, XML e JavaScript e solitamente servono ai programmatori per scrivere codice sorgente o agli sviluppatori come parte di una codifica, ma possono essere utilizzati anche in modi diversi. Ad esempio, si possono usare per scrivere documenti che includono parole in altre lingue, per inserire contenuti che sono stati tradotti da un’altra lingua, per creare nomi di file unici, e spesso sono sfruttati nella grafica web per rendere i siti più accattivanti, per semplificare l’inserimento dei dati nella pagina web o per aggiungere un tocco personale a un sito Web.
Dal punto di vista pratico, i caratteri non ASCII possono essere inseriti manualmente oppure generati automaticamente dai programmi informatici: per aggiungere questo tipo di simbolo a un documento è necessario utilizzare un’applicazione che supporta la codifica Unicode, che è l’insieme standard di codifiche che contengono tutti i caratteri non ASCII. Una possibile alternativa è quella di utilizzare dei codici HTML appositamente creati per la rappresentazione dell’insieme completo della codifica Unicode.
I caratteri non ASCII offrono numerosi vantaggi: innanzitutto, aumentano notevolmente la flessibilità nella creazione di siti web accattivanti e nello sviluppo di software complesso; inoltre, consentono agli sviluppatori di creare rappresentazioni visualmente più attraenti dell’immagine del prodotto finito; infine, offrono la possibilità agli utenti finali di usufruire delle potenzialità offerte da questa tecnologia senza dover padroneggiarne le complesse regole tecniche.
Che cosa sono i caratteri speciali
I caratteri speciali sono simboli che hanno funzioni particolari o rappresentano concetti specifici e non sono necessariamente legati a un alfabeto. Includono segni di punteggiatura, simboli matematici, di valuta, icone grafiche e altri segni utilizzati per la formattazione del testo, operazioni matematiche, indicazioni legali o tipografiche, e possono essere parte del set ASCII o estendersi oltre di esso.
Sono codificati per essere riconosciuti e interpretati correttamente dai sistemi informatici e dai linguaggi di programmazione, e spesso richiedono l’uso di codici di entità specifici in HTML e altri linguaggi di markup per evitare conflitti con la sintassi del codice.
Questi caratteri speciali sono essenziali per una comunicazione chiara e precisa in contesti digitali e cartacei, e la loro corretta implementazione è fondamentale per l’usabilità e l’accessibilità dei contenuti su diverse piattaforme e dispositivi.
Quali sono i caratteri speciali
I caratteri speciali sono simboli che esulano dalle lettere alfabetiche e dai numeri standard. Questi simboli hanno funzioni specifiche e non sono legati a una specifica lingua o alfabeto: piuttosto, sono universali nella loro applicazione e riconoscimento.
Tra gli esempi di caratteri speciali troviamo:
- Simboli di punteggiatura come virgole (,), punti (.), punti e virgola (;), due punti (:), e virgolette (“ ”).
- Simboli matematici come il più (+), il meno (-), il per (×), il diviso (÷), e l’uguale (=).
- Simboli di valuta come il dollaro ($), l’euro (€), la sterlina (£), e lo yen (¥).
- Simboli tipografici come il trattino (–), il simbolo di copyright (©), e il simbolo di marchio registrato (®).
- Caratteri tecnici come le frecce (←, →, ↑, ↓) e i simboli di controllo (ad esempio, il segno di spunta ✓).
A cosa servono i caratteri speciali
Questi simboli sono utilizzati per vari scopi, come la formattazione del testo, operazioni matematiche, rappresentazioni di concetti o azioni, e per dare enfasi visiva.
Più precisamente, i caratteri speciali servono solitamente per aggiungere chiarezza e precisione al testo, per esprimere concetti che altrimenti richiederebbero molte più parole, o per rispettare convenzioni tipografiche e di stile. In HTML e altri linguaggi di programmazione, molti di questi caratteri speciali devono essere inseriti usando codici specifici, poiché il loro utilizzo diretto potrebbe interferire con il codice stesso. Per esempio, in HTML il simbolo di minore di (<) viene rappresentato dal codice < per evitare confusione con i tag del linguaggio.
In matematica e nelle scienze, facilitano la rappresentazione di operazioni e relazioni tra numeri e variabili. Nella scrittura, migliorano la leggibilità e la comprensione del testo, indicando pause, enfasi e citazioni. Nel design e nella composizione tipografica, aggiungono elementi visivi che possono guidare l’occhio o segnalare informazioni importanti. Inoltre, in programmazione e sviluppo web, alcuni caratteri speciali hanno funzioni specifiche nel codice, come l’inizio o la fine di un comando.
Come funziona la codifica di questi caratteri
Per quanto riguarda la codifica, i caratteri speciali e caratteri non ASCII seguono gli stessi standard. La codifica più comune e ampiamente supportata è UTF-8, che è in grado di rappresentare ogni carattere in Unicode, lo standard che include praticamente tutti i caratteri utilizzati nelle lingue scritte, come detto.
In particolare, lo standard Unicode ha consentito l’espansione dei caratteri perché ha fornito una base per la rappresentazione di testi in migliaia di caratteri diversi, garantendo che ogni simbolo, da quelli usati nell’antico sanscrito alle moderne emoji, abbia il suo posto nel codice digitale.
UTF-8 è particolarmente utile perché è retrocompatibile con ASCII, il che significa che i primi 128 caratteri di Unicode corrispondono esattamente ai caratteri ASCII, facilitando la transizione e la compatibilità con sistemi e documenti più vecchi. In HTML e altri linguaggi di markup, molti caratteri speciali devono essere inseriti usando codici di entità, come & per il simbolo “&”, per evitare conflitti con la sintassi del linguaggio.
Caratteri speciali e caratteri non ASCII: quali sono i problemi di codifica
Se un sistema non riconosce i caratteri speciali o non ASCII, possono verificarsi diversi problemi, che vanno dalla visualizzazione errata del testo fino a errori più gravi che influenzano la funzionalità del sistema.
Il problema più comune è la visualizzazione errata dei caratteri, nota come “mojibake”. Questo si verifica quando il sistema mostra una serie di simboli incomprensibili o sostituisce i caratteri non riconosciuti con dei segnaposto, come quadrati vuoti o punti interrogativi. Questo rende il testo illeggibile e può causare confusione o fraintendimenti.
Spesso il mojibake si concretizza in una sequenza casuale di simboli senza senso. Ad esempio, se un testo in UTF-8 viene erroneamente interpretato come Windows-1252, visivamente appare qualcosa del genere:
- Testo originale: “Café”
- Codifica errata: “Café”
Inoltre, i sistemi possono utilizzare caratteri di sostituzione come punti interrogativi, quadrati o simboli di diamante con un punto interrogativo al loro interno per indicare un carattere non riconosciuto. Ad esempio,
- Testo originale: “Número”
- Codifica errata: “N�mero” o “N�mero”
Nel contesto web, la codifica errata può causare problemi di visualizzazione o di sicurezza come gli attacchi XSS (Cross-Site Scripting). Ad esempio:
- Testo originale: “5 < 10 and 10 > 5”
- Codifica errata: “5 < 10 and 10 > 5” (questo potrebbe essere interpretato come un tag HTML non valido e non visualizzato correttamente, o peggio, potrebbe esporre il sito a vulnerabilità come gli attacchi XSS).
Quando si aprono file di testo con una codifica diversa da quella con cui sono stati salvati, si possono incontrare anomalie. Ad esempio, un file di testo salvato in UTF-8 che contiene emoji, se aperto con una codifica che non supporta gli emoji, potrebbe mostrare:
- Testo originale: “?”
- Codifica errata: “🙂”
Se un database non è configurato per supportare UTF-8 (o un’altra codifica Unicode) e si tenta di inserire caratteri non ASCII, questi possono essere salvati in modo errato. Ad esempio, per il testo russo:
- Testo originale: “Добрый день”
- Codifica errata nel database: “Добрый день”
I sistemi che possono avere problemi con la codifica includono vecchi sistemi operativi e software che non supportano Unicode, database non configurati per UTF-8, applicazioni web che non specificano correttamente la codifica dei caratteri, e programmi di elaborazione testi obsoleti. Per evitare questi problemi, è cruciale che tutti i sistemi coinvolti nel trattamento dei dati siano configurati per utilizzare una codifica di caratteri coerente e moderna, come UTF-8, che supporta un ampio spettro di caratteri e garantisce la compatibilità tra diverse piattaforme.
Che cos’è il codice ASCII, come funziona e a cosa serve
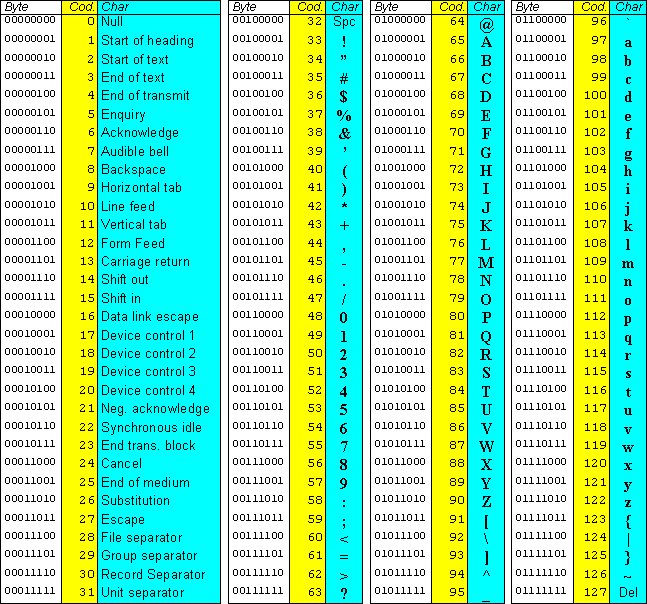
A questo punto è però inevitabile una digressione sul Codice ASCII, dalle iniziali di American Standard Code for Information Interchange, che è “il” codice di rappresentazione dei caratteri alfanumerici e degli altri simboli utilizzato in informatica, che consente a due macchine di comunicare tra loro e trasmettere dati. Sviluppato nel 1963 e definitivo dal 1968, questo sistema a 7-bit è ancora ampiamente utilizzato nei moderni sistemi di comunicazione e si basa su un insieme di 128 combinazioni binarie (128 numeri decimali che vanno da 0 a 127) che rappresentano tutti i caratteri standard, come lettere, numeri, simboli e spazi bianchi.
Il codice ASCII nasce per semplificare la scrittura e la programmazione informatica e può essere utilizzato per memorizzare, organizzare e trasmettere dati alfanumerici; una volta inviato, il testo viene decodificato e visualizzato sullo schermo in modo leggibile; inoltre, il codice ASCII può essere utilizzato per l’autenticazione dell’utente in una rete informatica.
Per la precisione, il codice ASCII consente a un computer di riconoscere e visualizzare alfanumerici, simboli, numeri e segni di punteggiatura. Consiste in una tabella che assegna una serie di valori numerici a ciascun carattere: ad esempio, il numero 65 corrisponde alla lettera maiuscola A. Inoltre, il codice ASCII può essere separato in gruppi più piccoli, chiamati set di caratteri, che contengono solo i caratteri necessari a scrivere in una particolare lingua o per creare un’interfaccia utente specifica.
Come detto, i caratteri ASCII fanno rappresentano i simboli più comuni usati nella scrittura e nella programmazione e sono ancora oggi utilizzati come standard de facto per la maggior parte dei documenti di testo. Ciascun carattere ASCII è rappresentato da un numero binario, che può essere rappresentato in tutte le lingue: ritornando all’esempio precedente, il carattere “A” è rappresentato dal codice binario 01000001, e ciò significa che la lettera A occupa solo 8 bit di memoria nella memoria del computer.
Esistono diversi tipi di caratteri ASCII, tra cui lettere maiuscole, lettere minuscole, numeri e simboli speciali: ognuno di loro può essere rappresentato da un codice binario diverso, e alcune lettere hanno più varianti in base alla lingua e all’ortografia usata. Ad esempio, in italiano la lettera “e accentata” può avere due varianti differenti a seconda del tipo di accento, se grave o acuto, e diventa quindi “è” o “é”.
I caratteri ASCII sono spesso usati nel web design e nello sviluppo di siti web per creare modelli di testo più facili da leggere o digitare su dispositivi mobili; inoltre, possono anche essere usati nell’editing video e audio per evidenziare alcune parole o frasi in grassetto o corsivo, e alcuni programmi possono utilizzare i caratteri ASCII per creare immagini o disegni in formato bitmap.
Chi ha inventato il Codice ASCII?
Il Codice ASCII è stato inventato da Bob Bemer nel 1963, e quindi quest’anno festeggia i 60 anni di vita e carriera. Bemer era un ingegnere informatico che lavorava per IBM e che riconobbe la necessità di un sistema universale per rappresentare i caratteri alfanumerici in codice binario: mise quindi a punto un sistema a 7 bit, nell’intervallo da 0 a 127, che identificano tutti i caratteri alfanumerici, simboli di punteggiatura, segni di controllo e altri simboli grafici, con l’idea di rendere semplice la rappresentazione dei dati su vari dispositivi e sistemi operativi.
Considerato un pioniere nel campo dell’informatica, Bemer non si limitò a progettare il Codice ASCII, ma contribuì anche alla definizione del formato standard degli indirizzi email e lavorò in seguito anche allo sviluppo del linguaggio di programmazione FORTRAN. Nel 1980, fu eletto nella Hall of Fellows dell’Institute of Electrical and Electronics Engineers (IEEE) e nel corso della sua carriera ricevette numerosi riconoscimenti per il suo contributo all’informatica.
La sua invenzione ha avuto vastissime implicazioni nell’ambito della comunicazione digitale: il Codice ASCII ha alimentato lo sviluppo delle tecnologie informatiche ed è un elemento essenziale nella maggior parte degli strumenti informatici moderni. Senza questa invenzione, sarebbe stato impossibile rappresentare i caratteri non-ASCII come i caratteri cirillici o giapponesi su computer, ed è grazie al lavoro di Bob Bemer se oggi le persone possono scambiarsi con facilità informazioni in modalità digitale in tutto il mondo.
Non ASCII characters, le funzioni pratiche
Tuttavia, il codice ASCII non è in grado di gestire qualsiasi tipo di carattere speciale, come lo sono ad esempio simboli matematici, lettere accentate e altri caratteri presenti nelle lingue straniere, e per questo motivo sono stati creati codici come Unicode e UTF-8, capaci proprio di gestire questo tipo di caratteristiche ed espandere così le capacità del codice ASCII, ma più “pesanti” per quanto riguarda lo spazio su disco occupato.
Ecco perché tornano utili i caratteri non-ASCII, che sono come detto quelli che non possono essere rappresentati con il tradizionale codice ASCII a 7 bit: si tratta, in pratica, di tutte le combinazioni che vanno da 128 a 255 nella tabella ASCII, costituendo il set di caratteri estesi.
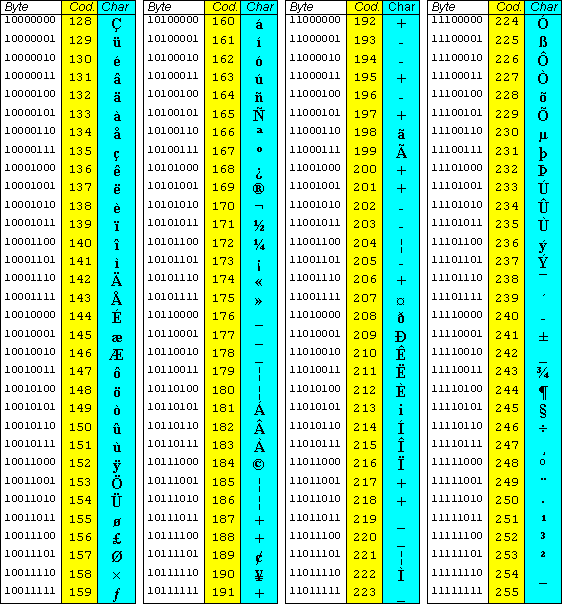
Per rappresentare questi caratteri speciali, le reti informatiche hanno introdotto un nuovo insieme di caratteri chiamati Unicode che offre più di 65000 combinazioni binarie per rappresentare le lingue del mondo intero, che sono uno strumento estremamente utile per programmatori, designer e persone che scrivono testi in più lingue.
Oltre a quelle descritte, un’altra applicazione comune dei non-ASCII characters è creare testo con font diversificati o decorazioni nella grafica di stampa o web; in tale ottica, i designer possono usare i caratteri non-ASCII per creare titoli particolarmente attraenti o effetti grafici particolari come sfondi a tema natalizio o pattern floreali unicamente con l’aiuto della tastiera.

I non-ASCII characters possono anche essere utilizzati per creare nomi di file più descrittivi: ad esempio, può essere più facile riconoscere un file chiamato “Risultati_de_ll_esame.pdf” rispetto a un file chiamato “Risultati_dellesame123456789.pdf”. Questo rende più semplice trovare rapidamente il file desiderato senza dover ricordare lunghissime stringhe alfanumeriche.
Ancora, i caratteri non ASCII possono essere anche utilizzati per l’inserimento di emoji in messaggistica istantanea, che possono aiutare le persone a comunicare meglio le proprie emozioni e intenzioni senza dover digitare parole lunghe o frasi complesse.
Come digitare i caratteri speciali
Ci sono vari modi per digitare i caratteri speciali e inserirli in un documento di qualsiasi tipo, che si basano sull’utilizzo di una tastiera fisica o una tastiera virtuale.
Se disponiamo di una tastiera fisica, potrebbe essere necessario premere alcuni tasti contemporaneamente, e ad esempio in ambito Windows possiamo premere ALT + il codice numerico corrispondente al carattere desiderato (ALT+212 permette di inserire la È e maiuscola con accento grave anche nei documenti Office, per citare un caso comune).
In vari programmi o sulla barra degli strumenti del browser, poi, è possibile accedere all’elenco dei caratteri speciali mediante la selezione di un pulsante che contenga simboli come i tre puntini di sospensione (…), e restando in casa Office possiamo cercare l’opzione Caratteri speciali per trovare i caratteri desiderati.
Un altro metodo semplice è sfruttare l’opzione di copia-incolla: basta cioè copiare il carattere che ci serve da un sito Web o da un altro documento e incollarlo nel nostro testo.
Infine, le applicazioni mobili come iOS e Android offrono anche la possibilità di digitare i caratteri speciali con la tastiera virtuale del dispositivo.
Come gestire i caratteri non ASCII: i rischi e i problemi
In generale, conoscere come gestire correttamente i caratteri non-ASCII può essere molto utile per tutti gli sviluppatori: oltre a fare in modo che i contenuti siano accessibili a una più ampia gamma di persone, l’utilizzo corretto dei caratteri non-ASCII può anche contribuire a garantire che il codice sia stabile e funzioni correttamente. Utilizzando gli strumenti adeguati e facendo attenzione al modo in cui si scrive il codice, è possibile assicurarsi che tutti i caratteri non-ASCII vengano gestiti correttamente, senza problemi o conseguenze negative per il sito.
Molte lingue e sistemi di scrittura alfabetica utilizzano caratteri non-ASCII (American Standard Code for Information Interchange) per rappresentare simboli o lettere speciali e la necessità di supportare questi caratteri si fa sentire sempre più in una varietà di settori in cui i contenuti devono essere accessibili a tutti. Dal punto di vista pratico, ci sono vari casi in cui possiamo ricorrere ai caratteri non ASCII, a cominciare dall’uso di lettere accentate o altri segni speciali fino ad arrivare a alla scrittura in lingue che non usano l’alfabeto latino, come cinese, giapponese, cirillico o arabo.
Tuttavia, lavorare con questi caratteri può essere complicato per gli sviluppatori, poiché non sono sempre ben gestiti dal codice sorgente. In particolare, quando si lavora con testo digitale, i caratteri non ASCII possono causare problemi perché alcuni strumenti software possono non essere in grado di leggere correttamente i caratteri speciali, e serve quindi sapere come rimuoverli in modo da evitare problemi. Dunque, se lavoriamo a documenti con codice che contiene simboli non-ASCII dobbiamo fare attenzione a come vengono trattati i caratteri: se il codice non viene scritto correttamente, infatti, si possono incontrare vari problemi, come errori di decodifica o visualizzazione di caratteri diversi da quelli attesi.
Esistono diversi strumenti disponibili che possono aiutare gli sviluppatori a controllare i propri programmi per assicurarsi che tutti i caratteri non-ASCII vengano gestiti correttamente, e ci sono in particolare molti editor di testo che hanno opzioni specifiche per consentire agli utenti di impostare le impostazioni di codifica dell’editor in modo da poter visualizzare correttamente i caratteri. Inoltre, alcuni linguaggi di programmazione hanno funzionalità integrate che consentono agli sviluppatori di controllare le diverse forme di codifica, mentre altri software consentono di gestire i caratteri non ASCII, solitamente analizzando i caratteri e convertendoli automaticamente nella loro rappresentazione ASCII equivalente. L’utilizzo di queste applicazioni semplifica notevolmente la conversione dei caratteri e consente agli utenti di gestire meglio i documenti contenenti tali caratteri.
In alcuni casi, è possibile convertire manualmente i caratteri non ASCII in codici ASCII, ma è un processo complicato: per avere successo con questa tecnica, è necessario avere una buona conoscenza della codifica o delle lingue da cui provengono i caratteri. Anche programmi di scrittura come Microsoft Word offrono supporto per la gestione dei caratteri non ASCII attraverso la funzione denominata “codice sostitutivo”, che consente agli utenti di inserire facilmente alcuni caratteri non ASCII nel documento: il codice sostitutivo funziona selezionando il simbolo o la lettera desiderata dal menu e quindi digitando il codice corrispondente nel documento.
Una volta completata la scrittura del codice, è comune importante eseguire un controllo accurato delle stringhe contenenti i caratteri non-ASCII, sfruttando i diversi strumenti online che possono analizzare il codice e scoprire eventualmente errori di codifica o altri problemi di gestione della stringa. Questo può essere particolarmente utile quando si lavora con programmi multilingue in cui sono presenti simboli e lettere speciali di diverse culture e lingue.
In conclusione, quindi, gestire i caratteri non ASCII dipende principalmente dal tipo di documento e dai programmi utilizzati per crearlo o modificarlo: se lavoriamo a documenti che contengono tali caratteri, è importante ricordare che la conversione manuale può essere un processo complicato e richiedere molto tempo, e quindi la soluzione migliore potrebbe quindi essere quella di utilizzare le applicazioni disponibili per semplificare la gestione della codifica dell’intero documento o delle singole parole o frasi contenute in esso.
Non ASCII characters: come identificare i caratteri problematici
E quindi, per evitare problemi sul sito è in primo luogo importante sapere come riconoscere i caratteri non ASCII, e per farlo possiamo osservare il codice sorgente del nostro documento: se vediamo dei codici numerici o dei simboli strani, allora probabilmente stiamo guardando un carattere non ASCII.
Una volta identificati i caratteri non ASCII, possiamo rimuoverli facilmente con un editor di testo. La maggior parte degli editor di testo più popolari dispone di un opzione che cerca e sostituisce automaticamente i caratteri non ASCII con qualcosa di più leggibile. Un’altra opzione è quella di copiarli e incollarli manualmente in un editor che supporta il formato UTF-8, una buona idea soprattutto se stiamo modificando grandi quantità di materiale con molti caratteri non ASCII.
Anche se la rimozione dei caratteri non ASCII può sembrare complicata, la buona notizia è che c’è un modo semplice per evitarne la comparsa nel nostro testo digitale: basta assicurarsi che l’editor utilizzato supportati l’encoding Unicode standard UTF-8. Questa opzione dovrebbe essere disponibile nella maggior parte degli editor più moderni ed è un ottimo modo per assicurarsi che non ci siano caratteri non ASCII nel nostro testo digitale.
Anche se i caratteri non ASCII possono essere una fonte di problemi quando si lavora con testo digitale, conoscere il modo per riconoscerli e rimuoverli può aiutarci a evitare problemi: se stiamo usando software moderno, assicurarci che supporti l’encoding Unicode standard UTF-8 ci consentirà di scrivere senza problemi, evitando così la comparsa di caratteri non ASCII.
Come rimuovere un non ASCII character
Quando però, nonostante questo controllo, ci troviamo di fronte a un carattere non ASCII problematico possiamo anche decidere di rimuoverlo dal testo: in primis dovremo esaminare il file di testo e individuare il carattere che genera le difficoltà, così poi procedere alla rimozione, che può essere effettuata con diversi metodi a seconda del software utilizzato.
In formato Excel, è possibile rimuovere i caratteri non ASCII utilizzando la funzione “Rimuovi caratteri” all’interno della scheda “Strumenti”: iniziamo a selezionare prima tutti i dati nel foglio di lavoro e poi fare clic sulla scheda Strumenti nella parte superiore della finestra di dialogo, quindi, scegliamo la funzione Rimuovi caratteri e selezioniamo il tipo di carattere che si desidera rimuovere.
Inoltre, le applicazioni di elaborazione testi come Microsoft Word offrono anche la possibilità di rimuovere i caratteri non ASCII in modo semplice e veloce. Per usare questa opzione, basta selezionare il testo contenente i caratteri non ASCII e andare al menu Modifica > Trova e sostituisci. Quindi, inseriremo il simbolo del carattere da rimuovere nella casella “Trova” e lasciare la casella “Sostituisci con” vuota. Infine, premere il pulsante “Sostituisci tutto” per eliminare tutti i simboli non ASCII dal documento.
Un’altra soluzione per rimuovere i caratteri non ASCII da un file consiste nell’utilizzare un editor di testo come Notepad++ o Sublime Text: queste applicazioni offrono un’opzione specifica nel menu Strumenti chiamata Rimozione non ASCII che consente di eliminare facilmente qualsiasi simbolo non ASCII presente nel file.
Caratteri non ASCII sulla SEO: le sfide e le best practices
Quando si parla di SEO, i caratteri non ASCII possono rappresentare una sfida.
I motori di ricerca hanno fatto passi da gigante nell’interpretare e indicizzare questi simboli, ma la strada verso una comprensione perfetta è ancora lunga.
L’uso di caratteri non ASCII in elementi come titoli e meta descrizioni può influenzare il modo in cui i contenuti vengono interpretati dai motori di ricerca e, di conseguenza, la loro visibilità. Inoltre, la presenza di questi caratteri in URL può complicare l’indicizzazione e la fruibilità dei siti web, soprattutto se non gestiti correttamente attraverso la codifica.
In linea di massima, per gestire efficacemente i caratteri non ASCII su un sito è sufficiente adottare delle semplici best practices che assicurino la compatibilità e la corretta interpretazione da parte dei motori di ricerca. La codifica UTF-8 è ormai uno standard per la gestione dei caratteri non ASCII, permettendo una visualizzazione coerente su diverse piattaforme e dispositivi. È importante assicurarsi che il proprio sito web utilizzi questa codifica per evitare problemi di visualizzazione o di interpretazione da parte dei motori di ricerca.
Caratteri non ASCII e siti: come gestire URL e nomi dominio
Cosa succede però se ci sono caratteri non ASCII in un URL o nome di dominio? La maggior parte dei browser moderni supporta l’utilizzo di caratteri non ASCII in un URL o nel nome di un dominio, purché siano codificati correttamente con la percentuale. Questo significa che i caratteri non ASCII devono essere codificati in un formato denominato “URL encoding” prima di essere inseriti nell’URL o nel nome del dominio; dopo che l’URL o il nome del dominio è stato codificato, è possibile utilizzarlo come qualsiasi altro caso simile.
La percentuale di codifica è una tecnica che permette di includere caratteri non ASCII nelle URL in modo sicuro, ma la sua implementazione richiede attenzione e precisione.
Ci sono infatti alcune limitazioni da considerare quando si utilizzano caratteri non ASCII in un URL o nel nome di un dominio: ad esempio, alcuni browser potrebbero non riconoscere i caratteri non ASCII e potrebbero visualizzare un messaggio di errore anziché caricare la pagina Web corrispondente. Inoltre, poiché l’URL encoding è un processo complicato, può anche portare a problemi di compatibilità con alcuni browser più vecchi.
Inoltre, alcuni registrar di domini potrebbero non supportare i caratteri non ASCII nella registrazione dei nomi di dominio; se proprio vogliamo utilizzare caratteri non ASCII in un URL o nel nome di un dominio, dobbiamo quindi assicurarci innanzitutto che il registrar del dominio li supporti prima di procedere con la registrazione.
In caso contrario, infatti, possiamo creare confusione nei motori di ricerca e negli utenti che si trovano di fronte a stringhe di testo incomprensibili.
Caratteri Non ASCII nei meta tag e nei titoli
I meta tag e i titoli sono fondamentali per comunicare ai motori di ricerca e agli utenti di cosa tratta una pagina web. L’inclusione di caratteri non ASCII può rendere un titolo o una meta description più interessante e aumentare il CTR, ma è essenziale trovare un equilibrio. Un uso eccessivo o inappropriato può confondere i motori di ricerca e gli utenti, danneggiando la visibilità e l’efficacia del sito. La chiave sta nel mantenere la leggibilità e l’aderenza alle aspettative culturali del pubblico di riferimento.
Strumenti e Risorse per la Gestione dei Caratteri Non ASCII
In definitiva, chi si occupa di SEO deve comprendere quanto sia vitale avere a disposizione strumenti che aiutino a gestire i caratteri non ASCII. Esistono software e piattaforme online che permettono di identificare, convertire e testare l’impatto di questi caratteri sulla SEO.


Questi strumenti sono indispensabili per garantire che i contenuti siano ottimizzati e che i caratteri non ASCII siano utilizzati in modo efficace e strategico, studiando anche il contesto di attività del nostro sito attraverso un’analisi dei competitor per scoprire le loro strategie.
Ad esempio, l’analisi di un sito e-commerce che si rivolge a un pubblico internazionale potrebbe mostrare come l’uso accurato di caratteri non ASCII nelle descrizioni dei prodotti abbia migliorato l’engagement dei clienti in mercati target specifici. Allo stesso modo, un blog che utilizza caratteri non ASCII nei titoli potrebbe dimostrare un aumento del CTR grazie alla maggiore rilevanza culturale per i suoi lettori.
Questi esempi pratici non solo confermano che i caratteri non ASCII possono essere utilizzati a vantaggio della SEO, ma offrono anche un quadro reale delle pratiche migliori da adottare. Attraverso l’osservazione di come i caratteri non ASCII influenzano il posizionamento nei motori di ricerca e l’interazione degli utenti, possiamo imparare a sfruttare il loro potenziale per migliorare la visibilità e l’efficacia comunicativa dei nostri contenuti digitali.
