
Google elimina i link alla cache? Niente paura, ecco cosa fare

Addio alla cache di Google. Le prime indiscrezioni risalgono alle scorse settimane, ma ora è arrivata la notizia ufficiale: Google Search non mostra più i link alle pagine web che ha memorizzato e presto rimuoverà completamente la funzionalità della cache. Un cambiamento che segna la fine di una funzionalità che per anni è stata parte integrante dell’esperienza di ricerca degli utenti e che è stata spesso utile anche per il debugging di problemi SEO. Ma niente paura: ci sono ancora metodi alternativi per visualizzare le copie memorizzate delle pagine web, e c’entra anche SEOZoom!
Che cos’è la cache di Google
La cache di Google è una funzionalità che permette agli utenti di visualizzare una versione archiviata di una pagina web, così come era apparsa durante la visita precedente del crawler di Google. Questi backup, o snapshot, sono disponibili tramite un link specifico posizionato accanto all’URL del risultato di ricerca nei classici snippet di anteprima delle SERP, tradizionalmente disponibile sotto un piccolo triangolo o in un menu a tendina. Cliccando su questo link, si apre nel browser la versione della pagina salvata l’ultima volta che il crawler di Google l’ha visitata.
Mentre i crawler di Google esplorano e indicizzano il web, crea e aggiorna regolarmente questi archivi, fornendo così una risorsa preziosa per accedere a contenuti che potrebbero non essere più disponibili sul sito originario.
In pratica, è stata (dobbiamo abituarci a parlarne al passato!) una sorta di macchina del tempo digitale, che consentiva agli utenti di accedere a versioni precedenti di una pagina web.




La funzionalità della cache di Google è stata introdotta già nei primi anni dopo il debutto del 1998 ed è stata una delle tante innovazioni che hanno fatto la differenza tra Search e gli altri motori di ricerca, mettendo in risalto l’attenzione di Google verso l’esperienza degli utenti e la qualità dei suoi servizi di ricerca.
Di sicuro, la cache di Google è diventata rapidamente uno strumento apprezzato sia dagli utenti che dai professionisti del web, grazie alla sua capacità di fornire accesso a informazioni che altrimenti sarebbero potute essere temporaneamente o permanentemente inaccessibili.
A cosa serve la copia memorizzata
Questa funzionalità era particolarmente utile in diverse circostanze: ad esempio, la cache offriva la possibilità di recuperare le informazioni desiderate se una pagina era temporaneamente irraggiungibile a causa di problemi tecnici o lato server. Inoltre, per i professionisti SEO, la cache rappresentava uno strumento prezioso per analizzare le modifiche apportate a una pagina e comprendere meglio come e quando Google aveva eseguito l’ultima scansione del sito.
In effetti, la copia cache di Google nasce in un’epoca tecnologica differente, quando molti siti web potevano avere dei periodi di down piuttosto lunghi ed erano più frequenti anche i casi di sovraccarico dei server: visualizzare una copia della pagina salvata in precedenza da Google durante la scansione e l’indicizzazione del web era spesso l’unico modo per accedere ai contenuti di un sito temporaneamente inattivo.
Come funziona l’archiviazione nella cache di Google
La cache di Google era quindi il risultato di un processo tecnico complesso che coinvolgeva Googlebot e gli altri crawler di Google, i programmi automatizzati che esplorano il web per scoprire e analizzare le pagine da aggiungere all’indice di Google, che come sappiamo è il database a cui gli algoritmi attingono per fornire i risultati delle ricerche.
Quando un crawler di Google visitava una pagina web, non solo ne analizzava il contenuto e la struttura per comprendere di cosa trattava la pagina (il processo noto come crawling), ma ne creava anche una copia, che veniva poi memorizzata nei server di Google, diventando una sorta di “istantanea” della pagina nel momento in cui era stata visitata dal crawler.
Questa istantanea è ciò che veniva chiamato “cache” di Google.
La cache era disponibile principalmente per le pagine che erano state indicizzate da Google, il che significa che non tutte le pagine web finivano nella cache: solo quelle pagine che i crawler avevano visitato e ritenuto degne di essere incluse nell’indice di Google potevano avere una versione memorizzata nella cache. Inoltre, alcune pagine potevano essere escluse dalla cache per vari motivi, come ad esempio
- Direttive Robots.txt. Il file robots.txt fornisce istruzioni ai crawler su quali pagine dovrebbero o non dovrebbero essere indicizzate o memorizzate nella cache.
- Metatag Noarchive. Un meta tag robots specifico nelle pagine web che dice ai crawler di non memorizzare quella pagina nella cache.
- Problemi tecnici. A volte, problemi tecnici o errori potrebbero impedire ai crawler di accedere o memorizzare correttamente una pagina nella cache.
- Contenuto dinamico. Le pagine con contenuto altamente dinamico o che cambiano frequentemente potrebbero non essere sempre catturate correttamente nella cache.
- Questioni legali. In alcuni casi, Google potrebbe rimuovere la versione cache di una pagina a seguito di questioni legali o richieste di rimozione.
La funzione strategica della cache di Google
Quando era attiva e funzionava, la cache di Google era uno strumento estremamente utile perché permetteva di vedere il contenuto di una pagina anche se il sito originale non era più disponibile o se la pagina stessa era stata modificata o rimossa dal web. Questo aveva un valore inestimabile sia per gli utenti che cercavano informazioni, sia per i professionisti SEO che desideravano analizzare le pagine dal punto di vista dell’indicizzazione e del posizionamento nei risultati.
Non era quindi solo un semplice archivio di pagine web, ma una vera e propria risorsa strategica sia per gli utenti comuni che per i professionisti del web. Per gli utenti, la cache era uno strumento di accesso immediato a contenuti che, per vari motivi, potevano non essere temporaneamente disponibili online, come nei periodi di down per manutenzione o a causa di un sovraccarico di traffico.
Per i proprietari di siti web, poi, la cache funge da salvagente in situazioni di downtime, permettendo ai visitatori di accedere comunque ai contenuti e aiutando a mantenere una certa continuità nell’esperienza dell’utente, riducendo almeno parzialmente l’impatto negativo di eventuali interruzioni del servizio.
Inoltre, la cache di Google è stata uno strumento diagnostico utile anche dal punto di vista SEO e analisi digitale, permettendo di vedere l’ultima versione di una pagina che Google ha indicizzato e di comprendere quali elementi sono stati presi in considerazione dal motore di ricerca, ma anche di assicurarsi che le modifiche apportate fossero state riconosciute e indicizzate correttamente.
Google rimuove i link alle versioni cache delle pagine
Tutto questo diventa quindi “storia” del web perché da qualche giorno Google ha deciso di rimuovere il link alla copia cache dalle SERP e di terminare anche questa operazione di archiviazione.
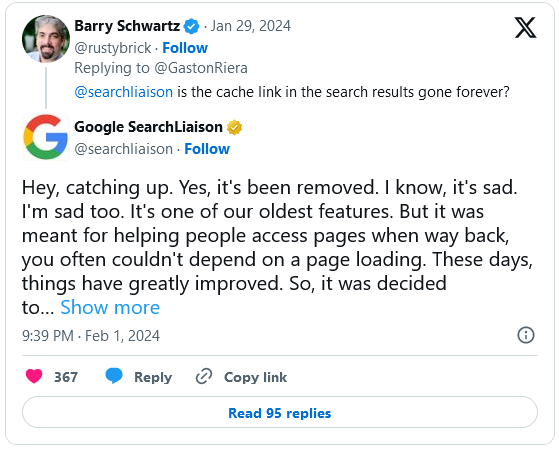
La conferma definitiva è arrivata da un tweet di Danny Sullivan, Search Liaison di Google, che ha appunto annunciato che il motore di ricerca ha definitivamente rimosso il collegamento alla cache dagli snippet dei risultati di ricerca di Google già alla fine di gennaio e proseguirà a dismettere anche tutte le altre operazioni correlate, a cominciare dall’eliminazione delle copie conservate. Al momento, ad esempio, non sono visibili collegamenti alla cache nei risultati di ricerca di Google e sono state rimosse anche tutte le pagine di supporto di Google relative ai collegamenti memorizzati nella cache.
Le motivazioni della decisione di Google
La decisione di Google di rimuovere il link alla cache dalle sue pagine dei risultati di ricerca ha sorpreso molti e segna la fine di un’era, con Sullivan che ha anche fornito delle (veloci) spiegazioni per questo addio.
Il punto critico sta nel fatto che la funzione di copia cache è considerata ormai obsoleta: con l’infrastruttura di internet notevolmente migliorata, i siti web professionali risultano pressoché sempre disponibili e il caricamento delle pagine web oggi subisce meno intoppi rispetto al passato. Quindi, i casi di utilizzo della funzionalità si erano di molto ridotti.
Come si può facilmente immaginare, non tutti sono d’accordo con queste considerazioni e le hanno ritenute solo una parte della questione.
In effetti, altri analisti hanno esteso le considerazioni a fattori più contingenti e ben più concreti: come detto, il processo del caching era piuttosto oneroso sia in termini tecnici che economici e – in un periodo di crescente attenzione al risparmio sui costi, come attestato dalle notizie sui licenziamenti in atto al gruppo di Mountain View – questa funzione era diventata semplicemente troppo costosa da mantenere. E poi, eliminare i dati archiviati libererà risorse di elaborazione.
Le alternative alla cache di Google: come salvare e vedere le pagine memorizzate
Con l’addio alla cache di Google, utenti e SEO non potranno più fare affidamento su questa funzionalità per accedere a contenuti non più disponibili o per visualizzare versioni precedenti di una pagina web.
Per fortuna, ci sono dei sistemi alternativi che consentono di recuperare le pagine web offline, cancellate o in versione precedente.
Il primo metodo riporta a uno dei più noti comandi di ricerca avanzata, ovvero cache: seguito dall’URL della pagina che si desidera cercare. Inserendo questo comando direttamente nella barra di ricerca di Google, si può tentare di accedere alla versione più recente della pagina memorizzata da Google, se disponibile. Inoltre, è possibile anche usare un altro percorso, ovvero aggiungendo l’URL di un sito web a “https://webcache.googleusercontent.com/search?q=cache:”
Tuttavia, anche questi operatori di ricerca dovrebbero essere dismessi a breve dal motore di ricerca.
Serve quindi iniziare a rivolgersi ad altri strumenti per l’archiviazione delle pagine web, come ad esempio Internet Archive (biblioteca digitale non-profit, attiva fin dal 1996), e il suo Wayback Machine, che conservano appunto snapshot storici delle pagine web e offrono anche la possibilità di aggiungere manualmente indirizzi web da memorizzare. Per la precisione, la “Wayback Machine” permette agli utenti di navigare nella storia di quasi qualsiasi pagina web e di visualizzare come apparivano in date passate, in modo completamente gratuito, oltre che di ripristinare pagine mancanti, leggere libri digitalizzati, condividere collegamenti archiviati sui social media e altro ancora (con account registrato o anche senza).
È stato Sullivan stesso a citare questo sistema come “la migliore alternativa alla cache di Google”, e anzi ha addirittura aperto alla possibilità di vedere Google aggiungere collegamenti alla Wayback Machine per permettere agli utenti di accedere alle versioni archiviate di quelle pagine. Nello specifico, il Search Liaison si augura che sia possibile aggiungere un link a Internet Archive all’interno di About This Result, in modo da mostrare facilmente alle persone come una pagina è cambiata nel tempo e di contribuire, contemporaneamente, anche all’obiettivo di alfabetizzazione informativa di questa funzionalità di Google (che in italiano si chiama “Informazioni su questo risultato”).
Tornando alle alternative alla cache di Google, è bene sapere che ci sono vari plugin e servizi di terze parti che consentono di creare archivi personali delle pagine web, garantendo che i contenuti possano essere salvati e consultati anche in futuro.


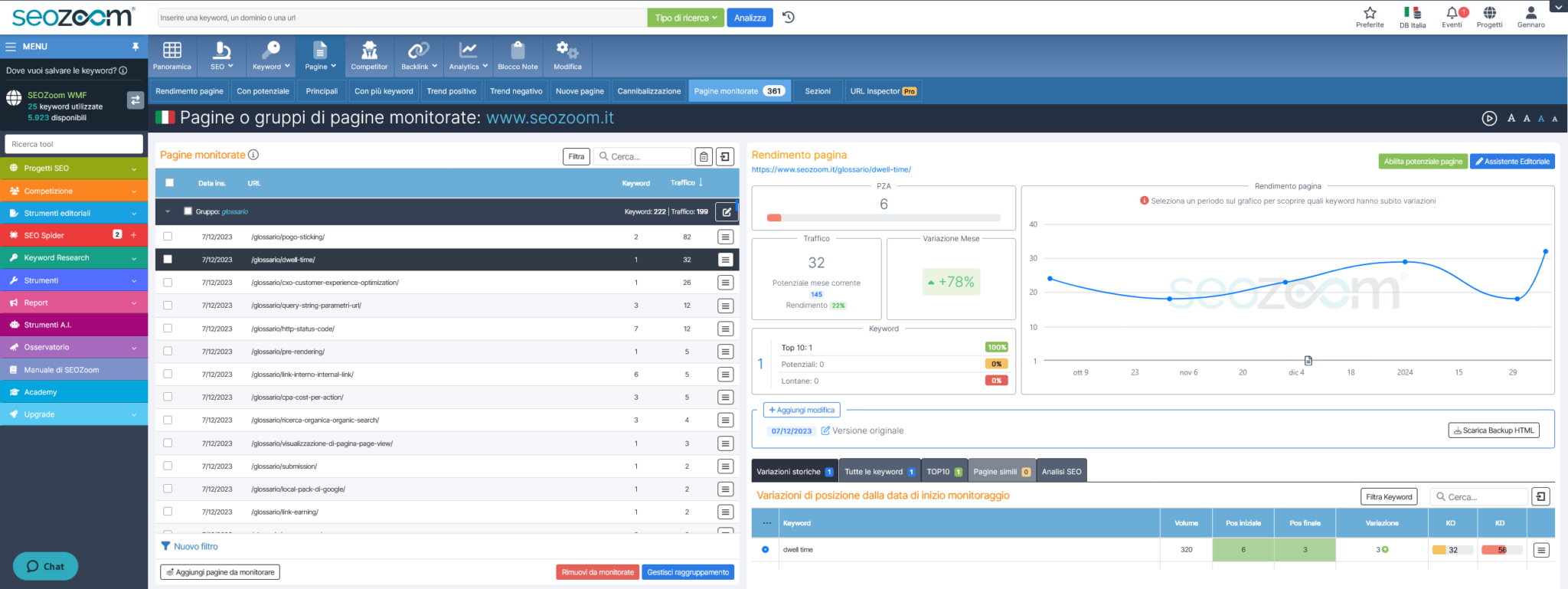
E poi c’è SEOZoom! Non dobbiamo dimenticare, infatti, che il nostro software mette a disposizione degli utenti la sezione “Pagine Monitorate” che permette di aggiungere manualmente specifiche pagine o percorsi del sito a progetto da tenere sotto controllo approfondito.
Oltre alla funzionalità base – analizzare in dettaglio il rendimento della pagina e verificare nel tempo i dati più importanti per le proprie strategie – all’interno di questo tool è possibile impostare il salvataggio della pagina allo “stato attuale in cui si presenta” al momento dell’inserimento e scaricare anche la versione HTML di questo salvataggio. In pratica, è possibile usare SEOZoom per fare una sorta di copia cache della pagina, aggiungendo anche delle note per segnalare le modifiche apportate e scoprire successivamente gli esiti e i risultati concreti di questi interventi. Un’opportunità interessante per superare il problema della decisione di Google, sicuramente più orientato all’aspetto SEO della memorizzazione delle pagine e chiaramente legato al numero di progetti e pagine che sono effettivamente a disposizione del proprio account.
Limitandoci poi alla verifica delle scansioni di Google, è chiaro che tutti gli utenti con una proprietà verificata possono usare lo strumento Controllo URL della Search Console per vedere cosa vedono i crawler di Google quando visionano le pagine dei loro siti. Anche in questo caso, ciò è solo una parte delle opzioni originariamente consentite dalla copia cache, ma ormai il dado è tratto e non resta che adattarci!
