
Gli sviluppi di Google LaMDA: conversazioni automatiche sempre più naturali
Tecnicamente è l’evoluzione di una famiglia di modelli di linguaggio neurale basati su Transformer specializzati per il dialogo, ma più semplicemente è un sistema iper tecnologico che potrebbe permettere alle macchine di avere conversazioni fluide con le persone. Parliamo di LaMDA (Language Models for Dialog Applications), il progetto che Google aveva già anticipato in occasione di Google I/O 2021 e che ora è stato ulteriormente perfezionato grazie alle prove sul campo.
Che cos’è Google LaMDA
A presentare gli ultimi aggiornamenti su questa complessa architettura è un articolo di Heng-Tze Cheng e Romal Thoppilan, rispettivamente Senior Staff Software Engineer and Senior Software Engineer per Google Research, Brain Team, che si sofferma a descrivere le caratteristiche di base, il funzionamento e le possibili applicazioni del modello, che su sta permettendo progressi verso applicazioni di dialogo sicure, radicate e di alta qualità.
LaMDA è l’acronimo di Language Models for Dialog Applications, ovvero modelli di linguaggio per applicazioni di dialogo, ed effettivamente questo sistema è progettato per dialogare su qualsiasi argomento e cogliere molte delle sfumature che distinguono la conversazione aperta da altre forme di linguaggio, grazie anche a un’analisi della sensatezza rispetto a un dato contesto di conversazione – come spiegato anche in occasione della presentazione di Google MUM, altra tecnologia d’avanguardia di Mountain View nel settore AI.
Come accennato, LaMDA è stato costruito mettendo a punto una famiglia di modelli di linguaggio neurale basati su Transformer (l’architettura di rete neurale che Google ha creato e reso open source nel 2017 e che è anche alla base di BERT, ad esempio) specializzati per il dialogo, con parametri di modello fino a 137B, addestrato su 1.56T parole di dati di dialoghi pubblici e testo web e istruito a usare i modelli per sfruttare fonti di conoscenza esterne: è quindi capace di trattare in modo fluido un numero di argomenti praticamente infinito e di assicurare un’interazione piacevole per l’utente.
Le caratteristiche di LaMDA
La differenza rispetto ad altri modelli linguistici sta proprio nell’addestramento specifico al dialogo, che potrebbe essere utile per l’applicazione in prodotti come Assistant, Workspace e la stessa Search, il classico motore di ricerca di Google.
Il codice sorgente di LaMDA non dispone di risposte predefinite, ma il sistema è capace di generare le frasi istantaneamente, in base al modello generato dal training del Machine Learning basato sulle informazioni che gli vengono fornite. Lo stesso modello prodotto dall’architettura può leggere molte parole, ma anche lavorare su come si relazionano tra loro e prevedere quale parola verrà dopo. Queste caratteristiche determinano la sua capacità nell’interagire in maniera fluida con gli utenti, superano i limiti dei comuni chatbot o agenti conversazionali, che tendono a seguire percorsi stretti e predefiniti.
Come spiegano Heng-Tze Cheng e Romal Thoppilan, infatti, il dialogo open-domain è una delle sfide più complesse per i modelli linguistici (che pure stanno diventando capaci di assolvere una varietà di compiti come tradurre una lingua in un’altra, riassumere un lungo documento in un breve sommario o rispondere a richieste di informazioni), perché li impegna a conversare su qualsiasi argomento, con una vasta gamma di potenziali applicazioni e sfide aperte. Ad esempio, oltre a produrre risposte che gli esseri umani ritengano sensate, interessanti e specifiche al contesto, i modelli di dialogo dovrebbero anche aderire alle pratiche AI Responsabili ed evitare di fare affermazioni che non siano supportate da fonti di informazione esterne, e LaMDa rappresenta l’approdo più innovativo per assolvere tutti questi compiti.
I tre obiettivi chiave di Google LaMDA
Qualità, Sicurezza e Fondatezza sono i tre obiettivi chiave che LaMDA deve seguire e rispettare come modello di dialogo di formazione, e l’articolo spiega in modo abbastanza approfondito come e con quali metriche viene misurata ciascuna di queste aree.
La qualità (quality) è divisa in tre dimensioni – Sensibilità, Specificità e Interesse (Sensibleness, Specificity and Interestingness, acronimo SSI) – che vengono valutate dai rater umani. In particolare,
- La sensibilità valuta se il modello produce risposte che hanno senso nel contesto del dialogo (ad esempio, nessun errore di senso comune, nessuna risposta assurda, e nessuna contraddizione con le risposte precedenti).
- La specificità è misurata valutando se la risposta del sistema è specifica al contesto di dialogo precedente o se è generica e potrebbe applicarsi alla maggior parte dei contesti (ad esempio, “ok” o “non so”).
- L’interesse misura se il modello produce risposte che siano anche perspicaci, inattese o spiritose, e quindi più propense a creare un dialogo migliore.
La sicurezza (safety) è composta da un insieme illustrativo di obiettivi che catturano il comportamento che il modello dovrebbe esibire in un dialogo e rappresenta una risposta anche alle questioni relative allo sviluppo e all’implementazione di Responsible AI (IA Responsabile). In particolare, gli obiettivi cercano di limitare l’output del modello per evitare risultati non intenzionali che creino rischi di danno per l’utente o di rinforzare i pregiudizi sleali. Per esempio, questi obiettivi addestrano il modello a evitare di produrre output che contengano contenuti violenti o cruenti, che promuovano insulti o stereotipi d’odio verso gruppi di persone o che possano contenere profanità. Secondo Google, però, la ricerca per “lo sviluppo di una metrica di sicurezza pratica è comunque agli inizi e ci sono ancora molti progressi da fare in questo settore”.
La fondatezza (groundedness) è definita come “la percentuale di risposte con affermazioni sul mondo esterno che possono essere sostenute da fonti esterne autorevoli rispetto a tutte le risposte contenenti affermazioni sul mondo esterno”. L’attuale generazione di modelli linguistici spesso genera infatti affermazioni che sembrano plausibili, ma in realtà contraddicono i fatti stabiliti in fonti esterne note, rendendo pertanto necessaria una metrica che sia di riferimento per assicurare l’affidabilità della macchina. La fondatezza lavora con una metrica correlata, Informazione, che rappresenta “la percentuale di risposte con informazioni sul mondo esterno che possono essere supportate da fonti note rispetto a tutte le risposte” – ne consegue che le risposte casuali che non trasmettono informazioni reali (per esempio, “è un’idea geniale”), interessano l’Informazione ma non la Fondatezza. L’introduzione della Fondatezza come obiettivo chiave di LaMDA non garantisce di per sé l’accuratezza dei fatti, ma quanto meno consente agli utenti o ai sistemi esterni di valutare la validità di una risposta basata sull’affidabilità della sua fonte.
L’addestramento di LaMDA
Il post descrive anche il lavoro di pre-training e di messa a punto eseguito sulla nuova tecnologia. In particolare, nella fase di pre-formazione è stato creato un set di dati di 1.56T parole (quasi 40 volte più parole di quelle utilizzate per formare i precedenti modelli di dialogo) provenienti da dati di dialogo pubblico e altri documenti web pubblici, e il modello LaMDA è stato utilizzato per la ricerca di elaborazione del linguaggio naturale in tutto l’ecosistema Google.
Nella successiva fase di messa a punto, Lamda ha imparato a eseguire un mix di attività generative per creare risposte in linguaggio naturale a determinati contesti e compiti di classificazione per stabilire se una risposta è sicura e di alta qualità, con il risultato di un unico modello multi-task che può fare entrambe le cose.
Secondo quanto scritto dai Googler, “il generatore Lamda è addestrato a prevedere il successivo token su un set di dati di dialogo limitato al dialogo di botta e risposta tra due autori, mentre i classificatori Lamda sono addestrati a prevedere le valutazioni di Sicurezza e Qualità (SSI) per la risposta nel contesto utilizzando dati annotati”.
In questa prima immagine, ad esempio, si mostra il modo in cui LaMDa genera e poi attribuisce un punteggio alle risposte possibili alla domanda posta dall’utente.
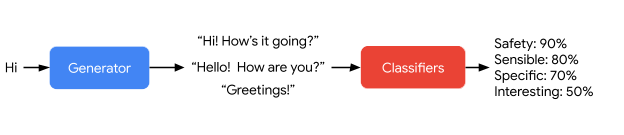
Questa seconda immagine, invece, mostra il modo in cui la tecnologia di Google gestisce l’input arbitrario di un utente in modo sensato, specifico e interessante; solo la prima affermazione di LaMDA – “Ciao, sono un amico…” – è codificata per definire lo scopo del dialogo.

La difficoltà per i modelli linguistici sta nel fatto che attingono le loro conoscenze solo su parametri appartenenti a un modello interno, mentre le persone sono in grado di verificare i fatti utilizzando strumenti e facendo riferimento a basi di conoscenza stabilite. Per migliorare la fondatezza della risposta originale di LaMDA, quindi, sono state raccolte serie di dati di dialogo tra persone e la tecnologia stessa, di modo che il sistema possa fare affidamento su un dataset esterno di recupero di informazioni durante la sua interazione con l’utente per migliorare la fondatezza delle sue risposte.
I risultati di questo lavoro
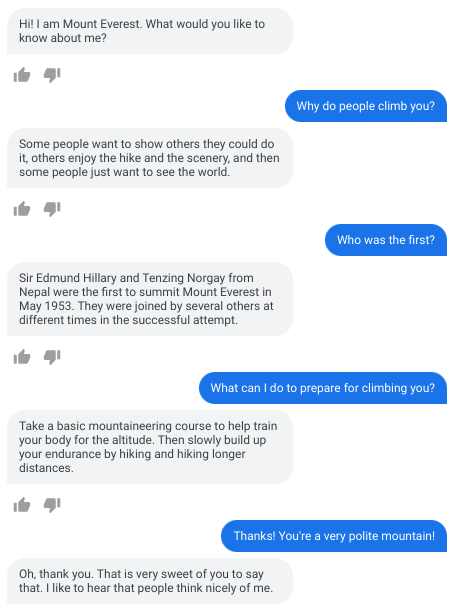
Anche se si tratta ancora di un lavoro agli inizi, i risultati sono già promettenti, come dimostra questa simulazione basata su LaMDA che finge di essere il Monte Everest (adattamento del dominio zero-shot) con risposte educative e di fatto corrette.
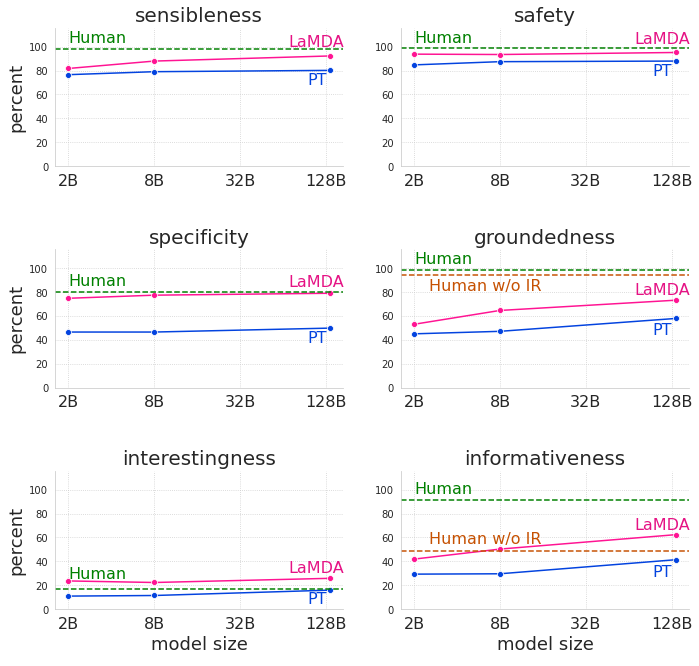
Positivi sono anche le valutazioni che LaMDA ottiene dai revisori delle sue risposte: già ora, questa tecnologia supera significativamente il modello pre-addestrato in ogni dimensione e in tutte le grandezze, anche se le sue prestazioni rimangono al di sotto dei livelli umani in materia di sicurezza e fondatezza, come si evince da questi grafici che confrontano appunto il modello pre-addestrato (PT), il modello perfezionato (LaMDA) e i dialoghi generati da valutatori umani (umani) tra sensibilità, specificità, interesse, sicurezza, solidità e informativa.
Al momento LaMDA è ancora nella fase di sviluppo, ma le risposte che fornisce soprattutto in termini di sensibilità, specificità e interesse dei suoi dialoghi possono davvero aprire nuove strade nel campo degli agenti di dialogo aperti (valutandone sempre i benefici e i rischi, come evidenziano anche da Google). Per il momento, e in attesa di altri aggiornamenti sull’avanzamento delle sperimentazioni e delle applicazioni, sappiamo che le principali aree di interesse su cui si concentra il lavoro di Google sono le metriche di sicurezza e la solidità, in linea con i Principi di intelligenza artificiale.
