
Code coverage, lo strumento per ridurre gli errori nel codice digitale
Indipendentemente dal suo livello di esperienza, ogni programmatore può commettere errori, causati da vari fattori come disattenzioni, specifiche poco chiare o una conoscenza non ottimale dell’ambiente di programmazione o del linguaggio utilizzato. Ecco perché è fondamentale impostare un sistema per rilevare e correggere questi errori il più rapidamente possibile, evitando perdite di tempo e possibili disservizi. Ciò assume ancora più rilevanza per progetti di alto livello, dove anche un piccolo bug può avere un impatto significativo e creare disagi e disservizi, influenzando l’esperienza di un gran numero di clienti. In questo contesto, la code coverage o copertura di codice si rivela un alleato prezioso, perché testa e misura la qualità del codice software, consentendoci di compiere un primo passo verso il successo del nostro sito.
Che cos’è la code coverage
In informatica, la code coverage o copertura di codice è un metodo per misurare la quantità di codice di un programma che è stato effettivamente eseguito durante un test, così da determinare se il codice è stato testato in modo completo ed efficace. Se una parte del codice non è mai stata eseguita, infatti, ci sono maggiori probabilità che contenga errori che non saranno mai scoperti.
È quindi uno strumento prezioso per chiunque sviluppi software, dai grandi team di sviluppatori alle piccole startup, fino ai freelance, e serve anche ai siti web per assicurare che il codice alla base del sito sia solido e affidabile, in grado di funzionare senza intoppi in ogni situazione. In particolare, se possediamo o gestiamo un sito web, come un e-commerce o un’applicazione web che gestisce dati sensibili, un bug potrebbe non solo causare problemi agli utenti, ma anche provocare ripercussioni legali o di immagine.
Dal punto di vista più tecnico, la copertura del codice è una tecnica di test white-box che serve a verificare la misura in cui il codice è stato eseguito; per eseguire la code coverage serve una strumentazione statica in cui le istruzioni che monitorano l’esecuzione del codice vengono inserite nei punti critici del codice e, come spiega una utile guida degli sviluppatori di web.dev, la registrazione di queste metriche solitamente ha questo aspetto:
Ogni aggiunta di codice di strumentazione, inoltre, comporta un aumento del tempo di esecuzione e della lunghezza del codice, ma è più che giustificato alla luce delle informazioni che il tester ottiene grazie a questo codice in più.
La code coverage viene generalmente espressa in valore percentuale – ad esempio, una code coverage del 90% significa che il 90% del codice è stato eseguito durante il test – e questo parametro ci aiuta essenzialmente a capire se i test che abbiamo scritto sono sufficienti e se stanno verificando tutte le parti del nostro codice. In altre parole, e per semplificare, la code coverage ci permette di capire se ci sono parti del nostro codice che potrebbero comportarsi in modo inaspettato perché non sono state adeguatamente testate.
Come funziona il code coverage
Come sa bene chi si occupa di sviluppo software et similia, ogni cliente desidera un prodotto software di qualità, dove questo termine include livello elevato di prestazioni, funzionalità, comportamento, correttezza, affidabilità, efficacia, sicurezza e manutenibilità del prodotto stesso.
La metrica Code Coverage aiuta appunto a determinare le prestazioni e gli aspetti di qualità di qualsiasi software e funziona monitorando l’esecuzione del codice durante i test per determinare quali parti sono state effettivamente eseguite e quali no. Questo processo viene solitamente automatizzato utilizzando strumenti di copertura del codice, che sono in grado di rilevare quali linee, funzioni, rami o blocchi di codice sono stati eseguiti durante i test.
Più precisamente, gli script di code coverage generano un report che descrive in dettaglio la quantità di codice dell’applicazione che è stata eseguita, esprimendo come detto un valore percentuale che definisce la metrica. Se, ad esempio, il 70% del nostro codice è stato eseguito durante i test, diremo che abbiamo una copertura del codice del 70%, e questa percentuale è un indicatore della completezza dei nostri test.
Una percentuale elevata suggerisce che i nostri test sono completi e coprono la maggior parte delle possibili esecuzioni del nostro codice, mentre una percentuale bassa può indicare che ci sono parti del nostro codice che non sono state testate. Tuttavia, è importante notare che la copertura di codice prende in esame solo l’esecuzione del codice, non la sua correttezza. In altre parole, una copertura del codice del 100% non significa che il nostro codice è privo di errori, ma solo che ogni parte del codice è stata eseguita almeno una volta durante i test. Per questo motivo, la copertura di codice dovrebbe essere utilizzata insieme ad altre tecniche di testing per garantire la qualità del software.
Perché eseguire il code coverage sul sito: i vantaggi
Già da quanto scritto si intuisce che la code coverage è uno strumento che non dovrebbe mai mancare nel toolkit di chi lavora nel digitale e tutti gli sviluppatori, dai più esperti ai neofiti del mondo del coding, non dovrebbero sottovalutare l’importanza di questa metrica. Se stiamo commissionando la realizzazione di un sito web o di un’applicazione, chiedere informazioni sulla copertura di codice può aiutarci a capire se lo sviluppatore sta facendo un buon lavoro; se, invece, siamo impegnati in prima persona nella programmazione, capire e applicare il concetto di copertura di codice può farci fare un salto di qualità notevole.
La linea di fondo è che un codice non testato è potenzialmente difettoso, mentre un codice ben scritto e ben testato può farci compiere il primo passo verso il successo di ogni progetto digitale.
In effetti, è un dato di fatto che molti progetti falliscono a causa della mancanza di qualità dei sistemi software, e quindi avere un occhio di riguardo al controllo di qualità del codice, durante le varie fasi di sviluppo, non è più una scelta opzionale ma un fattore critico.
Il primo e più evidente vantaggio della copertura di codice è la possibilità di identificare le parti del nostro codice che non sono state testate: questo ci permette di scrivere test più efficaci e di ridurre la probabilità che si verifichino errori inaspettati. Inoltre, una buona copertura di codice può aumentare la fiducia nei nostri prodotti da parte dei clienti e degli utenti, che vedranno in essa un segno di professionalità e attenzione alla qualità.
Inoltre, la code coverage può aiutare a identificare parti del codice che potrebbero essere superflue o ridondanti, consentendoci di ottimizzare il nostro software e di renderlo più efficiente. Infine, è un ottimo strumento per monitorare l’evoluzione del software nel tempo, in modo da capire anche se stiamo migliorando o peggiorando in termini di qualità.
L’importanza del testing per software e siti
La code coverage si inserisce nel più ampio lavoro di testing informatico, ovvero il processo di valutazione di un sistema software (o di un suo componente) basato sul suo comportamento in esecuzione sotto condizioni controllate.
Lo scopo specifico dell’attività di testing è individuare eventuali problemi e difetti nel programma prima della consegna all’utente, anziché concentrarsi sul dimostrarne l’assenza. Questo è un riferimento diretto alle lezioni di Wybe Dijkstra, uno dei pionieri della programmazione strutturata e della teoria dei dati, che appunto sanciva come “i test non possono dimostrare l’assenza di errori, ma possono solo dimostrare la loro presenza”.
Questa affermazione sottolinea un aspetto fondamentale del testing: anche se testiamo il nostro software in modo intensivo e non troviamo errori, questo non significa che il software sia privo di bug, ma potrebbe semplicemente evidenziare che i nostri test non sono stati in grado di individuarli.
Questo concetto è particolarmente rilevante quando parliamo di copertura di codice: come detto, anche se raggiungiamo una copertura del 100% non abbiamo la garanzia dell’assenza di errori nel software. Tuttavia, una copertura di codice elevata, combinata con altre tecniche di testing, può aiutarci a individuare e correggere un numero maggiore di errori, migliorando la qualità del nostro software.
Pur non essendo quindi una soluzione definitiva al problema dei bug software, la fase di testing è comunque cruciale per rilevare la presenza di malfunzionamenti e per facilitare il successivo processo di debugging, che si occuperà della rimozione di questi errori dal codice. Il testing inoltre non deve alterare in alcun modo l’ambiente in cui opera il programma, in quanto potrebbe inficiare la proprietà di ripetibilità del test case.
White Box Test, Black Box Test e Code Coverage
È opportuno a questo punto aprire una rapida parentesi sui due principali due approcci diversi al testing che si possono utilizzare in ambito di sviluppo software, ovvero “white box test” e “black box test”.
Nel white box test, il tester ha accesso al codice sorgente e può quindi verificare il comportamento interno del software. Nel black box test, invece, il tester non ha accesso al codice sorgente e può solo verificare il comportamento esterno del software, ossia se risponde correttamente agli input e produce i risultati attesi.
La copertura di codice rientra nell’ambito del white box test, in quanto richiede l’accesso al codice sorgente per verificare quali parti sono state eseguite durante i test, anche se ciò non implica necessariamente l’assenza di bug, come detto prima. Può quindi essere importare combinare la copertura di codice con altre tecniche di testing, come il black box test, per ottenere un quadro completo della qualità del nostro software.
C’è poi un’ulteriore distinzione da fare, ovvero tra test coverage e code coverage, che sono spesso confuse pur essendo profondamente differenti.
La test coverage o copertura del test è una metrica qualitativa che misura quanto bene la suite di test copre le funzionalità del software, aiutando così a determinare il livello di rischio coinvolto. Si riferisce quindi all’efficacia dei test nel coprire tutti i possibili casi che il software potrebbe incontrare durante il suo funzionamento, includendo ad esempio non solo l’esecuzione di tutte le linee di codice, ma anche la verifica di tutte le possibili combinazioni di input, di tutti i possibili percorsi di esecuzione e di tutte le possibili condizioni.
Come detto, invece, la copertura del codice è una metrica quantitativa che misura la proporzione di codice eseguito durante il test e riguarda quindi la quantità di codice coperta dai test. In tal senso, la copertura del codice è una misura più specifica, che fa parte della copertura dei test più generale; ciò significa che potremmo avere una copertura del codice del 100% (tutte le linee di codice sono state eseguite durante i test), ma avere comunque una copertura dei test bassa se, ad esempio, non abbiamo testato tutte le possibili combinazioni di input o tutti i possibili percorsi di esecuzione.
Se pensiamo a un’applicazione web come una casa, la test coverage misura quanto bene i test coprono le stanze della casa, mentre la copertura del codice misura la parte della casa attraversata dai test.
Come fare code coverage: i quattro metodi principali di misurazione
Ci sono diverse opzioni per creare report di copertura, a seconda del linguaggio di codice e degli strumenti di testing che utilizziamo; tuttavia, il processo di base è simile in molti casi e prevede l’uso di uno strumento di copertura del codice che monitora l’esecuzione del codice durante i test e genera un report che mostra quali parti del codice sono state eseguite e quali no.
Ecco alcuni esempi di strumenti di copertura del codice per diversi linguaggi di programmazione:
- JaCoCo è uno dei principali strumenti di copertura del codice per Java; si integra con la maggior parte degli ambienti di sviluppo e dei framework di testing e genera report dettagliati in vari formati, tra cui HTML e XML.
- Coverage.py è uno strumento di copertura del codice per Python che può essere utilizzato con qualsiasi framework di testing; genera report dettagliati che mostrano quali parti del codice sono state eseguite e quali no.
- Istanbul è uno strumento di copertura del codice per JavaScript che può essere utilizzato con vari framework di testing, tra cui Mocha e Jasmine; genera report in vari formati, tra cui HTML e JSON.
- C#. DotCover è uno strumento di copertura del codice per .NET che si integra con l’ambiente di sviluppo Visual Studio e genera report dettagliati.
Per utilizzare questi strumenti, è solitamente necessario configurarli per lavorare con il nostro ambiente di sviluppo e il nostro framework di testing, eseguire i test con l’opzione di copertura del codice abilitata e quindi generare il report; le istruzioni specifiche possono variare a seconda dello strumento e del linguaggio di programmazione utilizzato. Inoltre, alcuni di questi strumenti mostrano i risultati direttamente nel terminale, mentre altri possono generare un rapporto HTML completo che ci consente di esplorare quale parte del codice manca di copertura.
Tornando all’articolo guida di Ramona Schwering e Jecelyn Yeen su web.dev, si riconoscono attualmente quattro modi comuni per raccogliere e calcolare la copertura del codice, ovvero copertura della funzione, della linea, del ramo e delle istruzioni.
Ecco una breve descrizione delle loro caratteristiche e dei metodi di implementazione.
- Function coverage o copertura della funzione
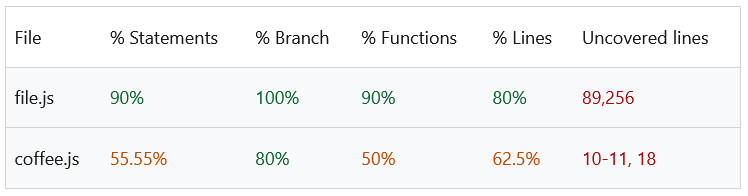
La copertura della funzione è una metrica semplice, che cattura la percentuale di funzioni nel codice richiamate dai test. Nell’esempio di codice sono presenti due funzioni: calcCoffeeIngredient e isValidCoffee. I test chiamano solo la funzione calcCoffeeIngredient, quindi la copertura della funzione è del 50%.

- Line coverage o copertura della riga
La copertura della riga misura la percentuale di righe di codice sorgente eseguibili che sono effettivamente eseguite dalla suite di test. Se una riga di codice rimane non eseguita, significa che alcune parti del codice non sono state testate.
L’esempio di codice ha otto righe di codice eseguibile (evidenziate in rosso e verde) ma i test non eseguono la condizione americano (due righe) e la funzione isValidCoffee (una riga). Ciò si traduce in una copertura della riga del 62,5%.
La line coverage non tiene conto delle istruzioni di dichiarazioni (declaration statements) come function isValidCoffee(name) e let espresso, water;, perché non sono eseguibili.

- Branch coverage o copertura del ramo
La copertura dei rami misura la percentuale di rami eseguiti o punti decisionali nel codice, come istruzioni if o cicli, e determina se i test esaminano sia il ramo vero che quello falso delle istruzioni condizionali.
Nell’esempio di codice sono presenti cinque rami:
- Chiamare calcCoffeeIngredient con solo coffeeName (check).
- Chiamare calcCoffeeIngredient con coffeeNameecup (check).
- Il caffè è espresso (check).
- Il caffè è americano (non corretto).
- Altro caffè (check).
I test coprono tutti i rami tranne la condizione Coffee is Americano, quindi la branch coverage è dell’80%.

- Statement coverage o copertura delle istruzioni
La copertura delle istruzioni misura la percentuale di istruzioni nel codice eseguite dai test. A prima vista potrebbe sembrare simile alla copertura della linea, ma tiene conto di singole righe di codice che contengono più istruzioni.
Nell’esempio di codice sono presenti otto righe di codice eseguibile, ma nove istruzioni, perché la riga espresso = 30 * cup; water = 70 * cup; contiene due istruzioni. I test coprono solo cinque delle nove affermazioni, pertanto la statement coverage è del 55,55%.

Se scriviamo sempre solo un’istruzione per riga, la copertura della riga sarà effettivamente identica alla copertura delle istruzioni.
Come scegliere il metodo più adatto
La maggior parte degli strumenti di copertura del codice includono questi quattro tipi comuni di copertura del codice, e quindi possiamo dire che la scelta della metrica di code coverage a cui dare la priorità dipende dai requisiti specifici del progetto, dalle pratiche di sviluppo e dagli obiettivi di test.
In generale, la copertura delle istruzioni è un buon punto di partenza perché è una metrica semplice e di facile comprensione; a differenza di questa, la copertura dei rami e la copertura della funzione misurano se i test chiamano una condizione (ramo) o una funzione e rappresentano pertanto una progressione naturale dopo la copertura della dichiarazione.
Dal punto di vista pratico, se il test mostra una copertura elevata delle istruzioni possiamo passare ad analizzare la copertura dei rami e la copertura delle funzioni.
Attenzione ai dati: una metrica errata è peggiore di nessuna metrica
Abbiamo detto che c’è un rischio insito nella code coverage, ovvero ottenere il 100% nel test e pensare che il software sia privo di errori. In realtà, oltre a non essere vero in senso generale (questo valore ci informa solo che ogni parte del codice è stata eseguita almeno una volta durante i test) può essere anche frutto di una “allucinazione”, come nell’esempio mostrato ancora da web.dev in cui il test raggiunge il 100% di copertura di funzioni, linee, rami e istruzioni, ma non ha senso perché in realtà non testa il codice realmente.

Come sintetizzano gli esperti, una metrica errata può darci un falso senso di sicurezza, il che è peggio che non avere alcuna metrica. Ad esempio, se disponiamo di una suite di test che raggiunge una copertura del codice del 100% ma i test sono tutti privi di significato, potremmo avere un falso senso di sicurezza che il codice sia ben testato; se accidentalmente eliminiamo o rompiamo una parte del codice dell’applicazione, i test verranno comunque superati, anche se l’applicazione non funziona più correttamente.
Per evitare questo scenario abbiamo due strade:
- Revisione del test. Possiamo scrivere e rivedere i test per essere certi che siano significativi, testando il codice in una varietà di scenari diversi.
- Utilizzare la copertura del codice come linea guida, non come unica misura dell’efficacia del test o della qualità del codice.
In definitiva, la code coverage può essere una metrica utile per misurare l’efficacia dei test e può aiutarci a migliorare la qualità delle applicazioni assicurando che la logica cruciale nel codice sia ben testata.
Tuttavia, dobbiamo tener presente che resta solo una metrica, che deve essere integrata o supportata anche altri fattori, come la qualità dei test e i requisiti dell’applicazione, e soprattutto ricordare che il nostro obiettivo non è raggiungere una copertura del codice al 100%. È più utile invece utilizzare la code coverage insieme a un piano di test completo, che incorpori una varietà di metodi, inclusi test unitari, test di integrazione, test end-to-end e test manuali, per essere sicuri di fornire sempre un’esperienza positiva e senza errori.
