
Mobile-first index: pagine mobile prioritarie per l’indicizzazione

A partire dal 1° luglio 2019, l’indicizzazione con priorità ai contenuti per dispositivi mobili è attiva per impostazione predefinita per tutti i nuovi siti web (nuovi sul Web o prima non noti alla Ricerca Google) e dal 31 ottobre 2023 il percorso è ufficialmente terminato. Questi sono solo alcuni dei vari punti sulla timeline del Mobile-first index di Google, che è appunto il metodo con cui il motore di ricerca lancia Googlebot alla scoperta di nuove pagine online, annunciato per la prima volta nel 2016 e poi rilasciato ufficialmente a partire dal marzo 2018. Comprendere perché Google abbia deciso di dare priorità alla scansione del Web eseguita attraverso l’user agent smartphone non è difficile, visto che ormai la maggior parte degli utenti mondiali accede alla Rete proprio attraverso un dispositivo mobile, ma forse non tutti sanno ancora cosa significa per i siti questa “rivoluzione”: proviamo a fare chiarezza su tutti gli aspetti legati al mobile first indexing di Google, con uno sguardo particolare ai consigli di ottimizzazione ufficiali per le nostre pagine e i nostri contenuti e agli errori da evitare.
Che cos’è il mobile-first index di Google
Oggi, nel 2023, il mobile first indexing è il sistema di default con cui Google scopre e indicizza i nuovi siti, nonché quello abilitato per tutti i siti attualmente sottoposti a scansione.
Come annunciato da un post a firma di John Mueller e Nir Kalush, il 31 ottobre 2023 si è finalmente completato il lungo percorso per l’adozione totale di questo sistema – basti pensare che ancora un anno fa, secondo le stime ufficializzate dalla compagnia, solo oltre il 70% del web era così indicizzato e il definitivo switch-off è stato più volte rimandato, come dicevamo nell’analisi di fine 2021.
Questo significa, dunque, che le SERP che visualizziamo sono ormai basate sul modo in cui Google ha eseguito la scansione e l’indicizzazione dei contenuti guardando alla versione mobile di tale pagina anziché col vecchio sistema desktop, che invece esaminava la versione della pagina pensata e sviluppata per gli utenti da connessioni desktop, appunto.
La novità del mobile first index di Google è proprio questa: il motore di ricerca lancia in prevalenza Googlebot in modalità smartphone agent per valutare la versione dei contenuti per dispositivi mobili ai fini di indicizzazione e ranking, perché la maggior parte degli utenti accede alla Ricerca Google tramite un dispositivo mobile.
Come funziona l’indicizzazione mobile per i siti
C’è un aspetto prioritario da chiarire in maniera netta: non esiste un indice separato per dispositivi mobili e per siti desktop e la Ricerca Google continua a utilizzare un solo indice. Nello specifico, il sistema di Google continua a mostrare l’URL che risulta più appropriato per gli utenti, che si tratti di un URL per desktop o per dispositivi mobili, e non c’è modo per forzare l’inserimento di un sito Web in questo indice né possiamo richiederne l’esclusione.
Come detto, dal 31 ottobre 2023 tutti i siti Web sono stati abilitati per l’indicizzazione mobile-first, anche se Google ammette che permane un “numero molto ridotto di siti che non funzionano per niente sui dispositivi mobili”. Ciò dipende essenzialmente da alcuni problemi “che Google non può risolvere”, tra cui ” pagina che mostra errori a tutti gli utenti di dispositivi mobili, la versione mobile del sito bloccata con il file robots.txt – mentre la versione desktop consente la scansione – o tutte le pagine del sito mobile che reindirizzano alla home page”.
La documentazione del motore di ricerca chiarisce che temporaneamente sarà portata avanti la scansione di questi siti con il crawler Googlebot per desktop legacy, rivalutando l’elenco alcune volte all’anno. Ad ogni modo, la scansione con Googlebot per desktop legacy continuerà a essere ridotta il più possibile anche per risparmiare risorse (di Google, ma anche dei proprietari di siti).
Con il passaggio completo all’indicizzazione mobile-first, Google ha anche disattivato anche le informazioni del crawler di indicizzazione nella pagina delle impostazioni della Search Console: in effetti, ora queste informazioni non sono più necessarie poiché tutti i siti web che funzionano sui dispositivi mobili vengono sottoposti principalmente a scansione con il crawler mobile; comunque, e per curiosità, il report Statistiche di scansione mostra in che modo viene eseguita la scansione del nostro sito.
Cosa significa in concreto il mobile-first indexing per i siti
L’indice mobile-first ha avuto un impatto significativo sulla SEO, almeno dal punto di vista “filosofico”: prima di tutto, ha certificato che la versione mobile di un sito è importante e forse più importante di quella desktop.
Inoltre, ha cambiato (o avrebbe dovuto cambiare) il modo in cui i SEO specialist ottimizzano i siti web, rispettando le indicazioni per la mobile-friendliness o, ancora di più, imparando davvero a lavorare in ottica mobile-first, anche in termini di progettazione e sviluppo.
Dal punto di vista pratico gli effetti non sono stati particolarmente visibili, né per il ranking né per gli interventi correttivi per entrare nell’Indice mobile. A livello di “testimonianza storica”, ricordiamo che al completamento dello switch-off era Google a decidere se un sito Web fosse pronto per l’indicizzazione mobile-first in base a contenuto, link, immagini e video, nonché a dati strutturati e altri metadati. Secondo quanto dichiarato da voci pubbliche della compagnia in quelle fasi, l’uso massiccio di JavaScript avrebbe ad esempio potuto impedire a un sito Web di passare al nuovo indice, così come problematica era la presenza di interstitial che coprono la home page del sito. Ciò valeva solo per i siti più anziani rispetto al luglio 2019, per i quali Google continuava a monitorare e valutare le pagine per la loro disponibilità (readiness) al mobile first index e inviava una notifica tramite GSC quando erano ritenuti pronti allo switch.
Al contrario, i siti nuovi – intendendo con questo aggettivo tutti i siti pubblicati online o riconosciuti per la prima volta da Googlebot dopo il primo luglio 2019 – sono stati immediatamente inseriti per impostazione predefinita nell’indice mobile, e in questi casi, i webmaster non avevano ricevuto comunicazione tramite Search Console dell’avvenuto inserimento.
La storia dell’Indice Mobile-First: un percorso lungo 7 anni
I più navigati e attenti ricorderanno le varie tappe dell’evoluzione del mobile-first index, che ormai da sette anni fa parte dei discorsi di Mountain View e degli interessi dei SEO (almeno superficialmente), a testimonianza del fatto che la decisione di Google di passare a un indice mobile-first non è stata presa alla leggera, ma dopo attenta osservazione e analisi delle tendenze degli utenti.
Il punto di partenza è stato quanto mai pratico: sin dal 2015 le ricerche mobili su Google avevano superato le ricerche desktop, segnando un punto di svolta nel comportamento degli utenti online e rendendo quindi necessario un adattamento dell’intero ecosistema – a cominciare dal famoso “mobile friendly update”. Successivamente, nel 2016 Google ha iniziato a testare un sistema di “indicizzazione con priorità ai contenuti per dispositivi mobili”, in modo da indicizzare i contenuti che gli utenti avrebbero visto quando accedevano al sito web dal loro cellulare; la scansione e l’indicizzazione come su smartphone sono state un grande cambiamento per l’infrastruttura di Google, ma anche per il web pubblico, perché l’assunto era che una pagina web mobile doveva essere completa quanto la corrispondente versione desktop.
Visto il successo del periodo di test e dei feedback da parte degli sviluppatori web e dei SEO specialist, nel marzo 2018 Google ha quindi ufficializzato i primi trasferimenti di siti al nuovo Indice, anche in ragione del fatto che il traffico web mobile ha continuato a crescere e che, in alcune regioni del mondo, gli utenti utilizzano quasi esclusivamente il telefono per accedere a Internet.
Come accennato, il mobile-first index è IL sistema adottato da Googlebot in via prioritaria dal 1 luglio 2019 per tutti i siti web nuovi, intendendo con questo aggettivo, come specificato, sia quelli appena messi online che quelli appena scoperti ed emersi nella Ricerca Google.
Nell’occasione, la compagnia americana si era anche azzardata a prevedere una data per il completamento definitivo del passaggio definitivo al sistema di indicizzazione tramite smartphone Googlebot: la deadline era stata fissata a settembre 2020 ma, causa pandemia, era stata spostata una prima volta a marzo 2021 e poi infine “cancellata” senza ulteriori informazioni sulla tempistica di questa iniziativa, che “sarà fatta quando sarà fatta” – fino alla storia recente, che vede nel 31 ottobre 2023 il termine di questo lungo percorso.
Uno sguardo all’approccio Mobile-First in senso assoluto
Apriamo a questo punto una rapida digressione sul significato e sul concetto di “mobile-first“, usato ormai come un mantra nel mondo del web design e dello sviluppo anche se, forse, non viene poi rispettato nel concreto – e sappiamo che c’è anche un lavoro da fare per rendere i contenuti mobile friendly.
In termini semplici, dal punto di vista tecnico mobile first significa progettare e sviluppare un sito web pensando prima alla versione mobile e poi a quella desktop, riconoscendo la predominanza dei dispositivi mobili nel panorama digitale odierno e cercando di offrire la migliore esperienza possibile agli utenti mobili.
L’approccio mobile-first va oltre la semplice creazione di un sito web che funzioni su dispositivi mobili: impone di progettare e sviluppare un sito web con i dispositivi mobili come punto di partenza, così che tutte le decisioni di progettazione e sviluppo – dalla struttura del sito, alla navigazione, ai contenuti – siano prese avendo in mente gli utenti che accedono al sito da dispositivi mobili e le loro esigenze.
Nonostante questi concetti siano ormai dati per assodati, nella realtà l’attuazione di un approccio mobile-first presenta diverse sfide e si scontra con vari ostacoli: il primo è la resistenza al cambiamento, perché molti sviluppatori web sono abituati a progettare per il desktop e continuano ad avere un approccio desktop-first, rendendo il sito mobile una versione ridotta o limitata – nella migliore delle ipotesi, un adattamento – di quella desktop.
Un’altra sfida è la varietà di dispositivi mobili disponibili, ognuno dei quali ha le sue dimensioni di schermo, risoluzioni e capacità, e quindi progettare un sito web che funzioni bene su tutti questi dispositivi può essere un compito arduo. Inoltre, ci sono limitazioni tecniche da considerare: ad esempio, i dispositivi mobili hanno generalmente meno potenza di elaborazione e meno larghezza di banda rispetto ai desktop, e quindi i siti web devono essere leggeri e veloci da caricare sin dalla progettazione.
Infine, c’è la questione della conversione dei siti web esistenti: molti siti web sono stati progettati prima dell’avvento dell’approccio mobile-first e potrebbero non essere ottimizzati per i dispositivi mobili; convertire questi siti in un formato mobile-first può richiedere tempo e risorse significative.
Tuttavia, come spesso accade è Google a dettare la strada e i tempi, e come notava Ivano Di Biasi in occasione dello Zoomday 2023 di Napoli la notizia dell’introduzione di InteractionTo Next Paint nei Core Web Vitals conferma che è obbligatorio pensare prima ai siti mobile e che non basta più proporre semplicisticamente un sito responsive sul mobile.
A cosa serve il mobile first indexing
In occasione del rilascio ufficiale di questo sistema di indicizzazione, nel marzo 2018, il Software Engineer di Google Fan Zhang aveva descritto le caratteristiche innovative del mobile first index che, “dopo un anno e mezzo di attenta sperimentazione e test”, stava appunto per entrare in funzione con la migrazione dei primi siti che seguivano le best practices relative.
Nello stesso post si chiarivano meglio le novità: fino a quel momento, i sistemi di scansione, indicizzazione e classificazione di Google “hanno in genere utilizzato la versione desktop di una pagina”, che però “potrebbe causare problemi agli utenti mobile quando tale versione differisce di molto dalla versione mobile”. Si è resa dunque necessaria una nuova indicizzazione mobile-first, basata appunto sulla “versione mobile della pagina per l’indicizzazione e il ranking”, con l’obiettivo di “aiutare meglio i nostri utenti a trovare ciò che stanno cercando”.
Un altro aspetto subito rimarcato è che questo nuovo indice “non è separato dal nostro indice principale“: ovvero, Google continuerà ad avere un solo e unico indice per offrire i risultati di ricerca (niente “doppio indice di Google”, come si ipotizzava tempo fa), e se in questi anni è stata utilizzata la versione desktop per la classificazione, da ora e “sempre più spesso utilizzeremo le versioni mobili del contenuto”.
L’indicizzazione con priorità ai contenuti per dispositivi mobili permette solo a Googlebot di eseguire la scansione e indicizzare prima di tutto le pagine con lo smartphone agent, e non ci sono nemmeno presunti vantaggi in termini di ranking, visto che si tratta solo del modo in cui Google scansiona e indicizza i contenuti.
Per gli utenti non ci sono differenze di alcun tipo, perché continueranno a visualizzare nei risultati della Ricerca l’URL più appropriato secondo Google, che si tratti di un URL desktop o per dispositivi mobili.
Cosa cambia con l’indicizzazione mobile
Secondo Google, lo switch può produrre alcuni effetti: ad esempio, i proprietari dei siti vedranno una velocità di scansione notevolmente maggiore dallo smartphone Googlebot, e il motore di ricerca mostrerà la versione mobile delle pagine nei risultati di ricerca e nelle pagine memorizzate nella cache di Google. Altra nota importante e ufficiale, per i siti che “hanno pagine AMP e non AMP Google preferirà indicizzare la versione mobile della pagina non AMP” (un riferimento poi sparito dalle comunicazioni successive di Mountain View, a riprova del progressivo svilimento di AMP).
Una trasformazione di questa portata rischia di avere ovviamente conseguenze “psicologiche” per i SEO, ma è sempre Fan Zhang a invitare alla calma: “I siti che non si trovano in questa prima ondata non hanno bisogno di farsi prendere dal panico”, scrive, specificando che l’indicizzazione mobile-first riguarda il modo in cui “raccogliamo i contenuti, non il modo in cui viene classificato il contenuto”. In altri termini, i contenuti raccolti dall’indicizzazione mobile-first “non hanno alcun vantaggio di ranking rispetto ai contenuti mobili che non sono ancora stati raccolti in questo modo o ai contenuti desktop”; allo stesso tempo, se un sito ha “solo contenuti desktop, continuerà a essere presente nel nostro indice”, afferma Google.
Allo stesso tempo, però, gli sviluppatori di Mountain View incoraggiavano “i webmaster a rendere i loro contenuti ottimizzati per i dispositivi mobili”, perché Google avrebbe valutato “tutti i contenuti nel nostro indice, indipendentemente dal fatto che siano desktop o mobili, per determinare quanto sia mobile-friendly”, ricordando che dal 2015 questa misura può aiutare i contenuti ottimizzati per i dispositivi mobili a funzionare meglio per coloro che effettuano ricerche su dispositivi mobili e che lo Speed Update, sempre nel 2018, ha reso la velocità un fattore di ranking, determinando un potenziale declassamento per “i contenuti con caricamento lento potrebbero essere meno efficaci sia per gli utenti di desktop che per quelli via dispositivi mobili.
In sintesi, le novità apportate nel 2018 si basano sulla valutazione di alcuni fattori e tendenze a livello mondiale, a cominciare dalla diffusione della navigazione da dispositivi mobile, e si concretizzano in quanto segue:
- È partita la fase di roll out del sistema di indicizzazione mobile: secondo le premesse di Google, “essere indicizzati in questo modo non ha alcun vantaggio di rankinge opera indipendentemente dalla nostra valutazione ottimizzata per i dispositivi mobili”.
- Avere contenuti ottimizzati per i dispositivi mobiliè ancora utile per chi cerca soluzioni per ottenere performance migliori nei risultati di ricerca su dispositivi mobili.
- Offrire contenuti a caricamento rapidoè ancora utile per quanti cercano di ottenere prestazioni migliori per gli utenti mobili e desktop.
- In caso di siti che hanno pagine AMP e non AMP,Google indicizzerà la versione mobile della pagina non AMP.
- Come sempre, la classifica di Google utilizza molti fattori: gli sviluppatori di Mountain View anticipano che “potrebbero” mostrare contenuti agli utenti che non sono ottimizzati per i dispositivi mobili o che si caricano lentamente, se i “nostri numerosi altri segnali determinano che questo è il contenuto più pertinente da mostrare”.
Mobile First indexing, i consigli di Google per evitare errori
E quindi, anche Google ha riscontrato globali problemi con l’indicizzazione mobile, che si è rivelato un tema piuttosto ostico per il motore di ricerca a causa (soprattutto) dell’arretratezza e della scarsa mobile-friendliness di tantissimi siti.
Eppure, ancora nel 2018, John Mueller già offriva i primi consigli ufficiali a SEO e gestori di siti per evitare errori con la nuova indicizzazione mobile, annunciando anche che tale sistema era già usato per “oltre la metà delle pagine mostrate nei risultati di ricerca a livello globale”.
Più in dettaglio, il Search Advocate aveva fornito qualche indicazione su come funziona la scansione di Google, che sposta “i siti sull’indicizzazione mobile-first quando i nostri test ci assicurano che sono pronti”, comunicando immediatamente al proprietario del sito tramite un messaggio in Search Console questo passaggio. È possibile confermare il passaggio controllando i log file del server, dato che la maggior parte delle richieste dovrebbe provenire da Googlebot Smartphone, o in maniera ancora più semplice il citato URL inspection tool di GSC.
Di base, comunque, un sito era pronto allo switch al mobile-first index se “utilizzava tecniche di responsive design“, mentre per gli altri siti si potevano verificare alcuni problemi frequenti.
Dati strutturati e alt text causano problemi all’indicizzazione mobile
Il primo limite è l’assenza di dati strutturati sulle pagine mobili che, come dovremmo sapere, sono utili al motore di ricerca per comprendere meglio il contenuto delle pagine e per evidenziare le tue pagine nei risultati di ricerca “in modi fantasiosi”, per usare le ironiche parole di Mueller. Per questo, chi utilizza dati strutturati nelle versioni desktop delle proprie pagine dovrebbe prestare attenzione a inserire le stesse informazioni nelle versioni mobili delle pagine: un elemento importante perché con l’indicizzazione per dispositivi mobili Google userà solo la versione mobile della pagina per l’indicizzazione e, dunque, in caso contrario gli structured data risulteranno mancanti.
Per superare i problemi a testare le pagine, Google suggerisce di verificare i dati strutturati in generale e quindi confrontarli con la versione mobile della pagina; per il lato mobile, inoltre, è bene controllare il codice sorgente durante la simulazione di visione da dispositivo mobile, o di verificare la correttezza del formato con il rich results test di Google. Bisogna inoltre ricordare che “una pagina non ha bisogno di essere mobile friendly (per così dire, ottimizzata per i dispositivi mobili) per poter essere scansionata attraverso il mobile first index”, come dice ancora Mueller.
Il secondo problema evidenziato dal post di Big G riguarda l’assenza di alt-text per immagini su pagine mobili: il valore degli attributi alt delle immagini rappresenta un ottimo modo per descrivere le immagini agli utenti con screen-reader che, ricorda Mueller, sono usati anche sui dispositivi mobili. Inoltre, servono per l’identificazione da parte dei crawler dei motori di ricerca, perché senza alt-text è molto più difficile per Google comprendere il contesto delle immagini che sono utilizzate su un sito. Il consiglio, dunque, è di verificare i tag “img” nel codice sorgente della versione mobile per le pagine rappresentative dei propri siti web, usando un browser per simulare un dispositivo mobile o utilizzando il test Mobile-Friendly per verificare la versione renderizzata di Googlebot: l’importante è che la pagina fornisca attributi alt appropriati che si desidera eventualmente ritrovare in Google Immagini.
Le raccomandazioni di Google per i siti mobile
Qualche mese dopo, lo stesso John Mueller è tornato sull’argomento con nuove indicazioni per chi vuole ottimizzare le pagine di un sito per rendere a prova di indicizzazione mobile-first, dando come direttiva di massima “rendere i siti mobile friendly e scansionabili da user-agents mobile”.
Con la Rete che diventa inevitabilmente mobile-friendly, perché la navigazione da smartphone è quella più comunemente diffusa in gran parte del mondo, webmaster, sviluppatori e professionisti online devono comprendere questo cambiamento e rendere i loro siti più scansionabili e indicizzabili per user-agents mobile (l’espressione originale è “crawlable and indexable”).
Inoltre, l’articolo spiega anche il metodo con cui Googlebot valuta la readiness di un sito, che prende in considerazione la parità dei contenuti (testo, immagini, video e link inclusi), dati strutturati e altri meta-dati (ad esempio, titoli, descrizioni o meta tag robots). Si tratta di fattori tecnici, dunque, che prescindono da altri elementi come le proporzioni di traffico da desktop e mobile, come spiegato da Martin Splitt in risposta a un utente su Twitter.
In concreto, poi, Mueller ribadisce il suggerimento a utilizzare responsive web design per rendere i siti web davvero mobile friendly, anche se Google continua a supportare sistemi come il dynamic serving e gli URL mobili separati (noti anche come m.dot) per i siti web mobili.
Secondo l’esperienza maturata nel corso degli anni, infatti, l’utilizzo di URL differenti in base ai dispositivi può generare problemi e confusione sia agli utenti che ai motori di ricerca, e quindi sarebbe più opportuno utilizzare un unico URL per i siti Web desktop e mobili.
Le indicazioni per i siti con URL separati
Per i siti che continuano ad avere URL separati, Google indica nello specifico 3 best practices da rispettare per evitare errori nel crawling:
- Avere stessi contenuti per sito mobile e sito desktop (comprese risorse come video e immagini con relativi attributi ALT).
- Presentare dati strutturati per entrambe le versioni del sito
- Avere metadati (titoli e meta description) uguali in entrambe le versioni del sito.
A questi consigli di massima si aggiungono poi altre indicazioni più specifiche:
- Verificare entrambe le versioni del sito nella Google Search Console.
- Testare i link hreflang negli URL separati.
- Garantire una capacità sufficiente del server per gestire un eventuale incremento di frequenza di scansione di Googlebot.
- Controllare le direttive robots.txt in entrambe le versioni.
- Esaminare l’impostazione corretta per gli elementi link rel=canonical e rel=alternate tra la versione per dispositivi mobili e quella per desktop.
Mobile first indexing, le best practices consigliate da Google
Ben più specifica è la pagina con i consigli ufficiali di Google per il mobile-first index, costantemente aggiornata con nuove informazioni per fornire indicazioni precise a chi vuole ottimizzare il proprio sito per il mobile, in modo che gli utenti che navigano da un cellulare possano avere un’ottima esperienza di navigazione.
Ci sono tre configurazioni tra cui puoi scegliere per creare un sito ottimizzato per il mobile:
- Responsive design, la scelta suggerita da Google perché è il modello di progettazione più semplice da implementare e gestire: consiste, in estrema sintesi, di pubblicare lo stesso codice HTML in corrispondenza dello stesso URL a prescindere dal dispositivo dell’utente (desktop, tablet, dispositivi mobili, browser non visivi), in quanto il codice è in grado di mostrare i contenuti in modo diverso a seconda delle dimensioni dello schermo.
- Pubblicazione dinamica o dynamic servering: consiste nell’utilizzare lo stesso URL indipendentemente dal dispositivo, basandosi sullo sniffing di user-agent e sull’intestazione della risposta HTTP Vary: user-agent per gestire una versione diversa del codice HTML in base ai differenti dispositivi.
- URL distinti: consiste nel pubblicare codice HTML diverso per ogni dispositivo e su URL distinti, anche in questo caso basandosi sulle intestazioni HTTP user-agent e Vary per reindirizzare gli utenti alla versione del sito appropriata per il dispositivo.
La guida e i consigli di Google si applicano solo alle configurazioni di pubblicazione dinamica e URL separati, perché nel caso del responsive design “il contenuto e i metadati sono gli stessi nella versione mobile e desktop delle pagine”.
La guida e i consigli di Google si applicano solo alle configurazioni di pubblicazione dinamica e URL separati, perché nel caso del responsive design “il contenuto e i metadati sono gli stessi nella versione mobile e desktop delle pagine”.
- Assicurare che Google possa accedere e renderizzare i contenuti
La prima regola è verificare che Google possa accedere ai contenuti e alle risorse della pagina mobile e che abbia possibilità di farne il rendering. In particolare, dobbiamo badare a:
- Usare lo stesso robots meta tag sul sito mobile e desktop. Usare un diverso file robots meta sul sito per dispositivi mobili (in particolare i tag noindex o nofollow), Google potrebbe non riuscire a eseguire la scansione e l’indicizzazione della pagina quando il sito è abilitato per l’indicizzazione con priorità ai dispositivi mobili.
- Non caricare in modo lento i contenuti principali in seguito all’interazione dell’utente. Google non caricherà contenuti che richiedono l’interazione dell’utente (ad esempio scorrimento, clic o digitazione) per essere caricati; ciò implica l’importanza di assicurare che che Google possa vedere i contenuti caricati in modalità lazy.
- Consentire a Google di eseguire la scansione delle risorse. Alcune risorse hanno URL diversi sul sito mobile rispetto a quelli sul sito desktop: se desideriamo che Google esegua la scansione degli URL, non dobbiamo bloccare l’URL con la regola disallow.
- Assicurare che contenuti per desktop e dispositivi mobili siano gli stessi
La seconda indicazione riguarda un aspetto pratico: anche con contenuti equivalenti, le differenze nel DOM o nel layout tra la pagina desktop e quella mobile possono far sì che Google comprenda il contenuto in modo diverso. Tuttavia, avere gli stessi contenuti sulla versione desktop e mobile garantisce che le due versioni possano posizionarsi per le stesse parole chiave, e in concreto dobbiamo fare attenzione a:
- Assicurare che il sito mobile contenga gli stessi contenuti del sito desktop. Se il sito mobile ha meno contenuti del sito desktop, dovremmo valutare la possibilità di aggiornare il sito mobile in modo che i suoi contenuti principali siano equivalenti a quelli della versione desktop. Possiamo scegliere di avere un design diverso sui dispositivi mobili per massimizzare l’esperienza dell’utente (ad esempio, spostando i contenuti in accordion o schede), e ciò che conta è che il contenuto sia equivalente a quello del sito desktop, poiché quasi tutta l’indicizzazione del sito proviene dal sito mobile.
Google avverte che scegliere intenzionalmente di offrire meno contenuti sulla versione mobile di una pagina rispetto alla versione desktop può esporre il sito a un calo di traffico “quando sul sito viene abilitata l’indicizzazione con priorità ai contenuti per dispositivi mobili”, perché “Google non riesce a ottenere la stessa quantità di informazioni dalla pagina rispetto a prima”, quando usava la versione desktop. Invece di rimuovere contenuti, Google suggerisce di spostarli in fisarmoniche o schede per risparmiare spazio.
- Utilizzare sul sito mobile gli stessi titoli chiari e significativi usati sul sito desktop.
- Controllare i dati strutturati
Anche gli eventuali dati strutturati implementati sul sito devono essere presenti su entrambe le versioni. Tra le cose specifiche da controllare:
- Corrispondenza dei dati strutturati su siti mobili e desktop, iniziando col dare la priorità per il mobile ai tipi di dati strutturati Breadcrumb, Product e VideoObject.
- Utilizzo di URL corretti nei dati strutturati, verificando chegli URL nei dati strutturati nelle versioni per dispositivi mobili siano aggiornati agli URL per dispositivi mobili.
- Usare bene Evidenziatore di dati (Data Highlighter): se usiamo Data Highlighter per fornire dati strutturati, è opportuno controllarne regolarmente la dashboard per verificare la presenza di errori di estrazione.
- Inserire gli stessi metadati su entrambe le versioni del sito
L’elemento title e la meta descrizione – i classici snippet di anteprima – per ogni pagina devono essere equivalenti in entrambe le versioni del sito.
- Controllare il posizionamento degli annunci
Google invita espressamente a “non lasciare che gli annunci danneggino il ranking della pagina mobile”, consigliando di seguire il Better Ads Standard quando visualizziamo annunci sui dispositivi mobili. Ad esempio, gli annunci nella parte superiore della pagina possono occupare troppo spazio su un dispositivo mobile, il che rappresenta un’esperienza utente negativa.
- Controllare il contenuto visivo
Molto importante anche il lavoro da fare sugli aspetti visual e multimediali del sito, ovvero immagini e video.
- Controllare le immagini
Intuitivamente, le immagini sul sito mobile devono rispettare le best practice SEO per le immagini e, in particolare devono:
-
- Essere di alta qualità, né troppo piccole o con una bassa risoluzione sul sito mobile.
- Essere in formato e tag supportati – ad esempio, Google supporta le immagini in formato SVG, ma i suoi sistemi non possono indicizzare un’immagine .jpg nel <image>tag all’interno di un SVG incorporato.
- Pubblicati su URL stabili e non su URL che cambiano ogni volta che la pagina viene caricata per le immagini, altrimenti Google non sarà in grado di elaborare e indicizzare correttamente le risorse.
- Presentare lo stesso testo alternativo tra desktop e mobile.
- Presentare la stessa qualità dei contenuti tra desktop e mobile, usando gli stessi titoli, didascalie, nomi di file e testo pertinenti alle immagini su entrambe le versioni.
- Controllare i video
In modo simile, dobbiamo rispettare le best practice SEO per i video, e in particolare:
-
- Non utilizzare URL che cambiano ogni volta che viene caricata la pagina per i video, altrimentiGoogle non sarà in grado di elaborare e indicizzare correttamente le nostre risorse se utilizziamo URL in continua evoluzione.
- Utilizza un formato supportato per i video e inserire i video nei tag HTML supportati (ad esempio: <video>, <embed> o <object>)
- Utilizzare gli stessi dati strutturati videosia sul sito mobile che su quello desktop.
- Posizionare il video in una posizione facile da trovare sulla pagina quando viene visualizzato su un dispositivo mobile. Ad esempio, il posizionamento del video potrebbe essere danneggiato se gli utenti devono scorrere troppo verso il basso per trovarlo.
- Best practice aggiuntive per URL separati
C’è poi un elenco aggiuntivo di indicazioni per i siti che usano URL separati per le versioni desktop e mobile:
- Servire lo stesso stato della pagina di errore sia sul sito desktop che su quello mobile. Se una pagina sul sito desktop offre contenuti normali e la versione del sito mobile di quella pagina pubblica una pagina di errore, questa pagina mancherà dall’indice.
- Evitare gli URL frammentati nella versione mobile. La parte frammento dell’URL è quella che inizia con #: nella maggior parte dei casi, gli URL di frammenti non sono indicizzabili, quindi queste pagine mancheranno dall’indice.
- Controllare che le versioni desktop che offrono contenuti diversi abbiano versioni mobili equivalenti. Se URL diversi reindirizzano allo stesso URL (ad esempio, alla home page sui dispositivi mobili), tutte queste pagine mancheranno dall’indice.
- Verificare entrambe le versioni del sito in Search Console per assicurarti di avere accesso ai dati e ai messaggi per entrambe le versioni.
- Controllare i link hreflang su URL separati. Quando usiamo gli elementi link rel=hreflang per l’internazionalizzazione, dobbiamo collegare separatamente gli URL per dispositivi mobili e desktop: gli URL per dispositivi mobili hreflang devono puntare a URL per dispositivi mobili e, analogamente, l’URL per desktop hreflang deve puntare a URL per desktop.
- Avere un sito mobile di capacità sufficiente per gestire un potenziale aumento della velocità di scansione sulla versione mobile del sito stesso.
- Verificare che le regole del file robots.txt funzionino come previsto per entrambe le versioni del sito, utilizzando quando possibile le stesse regole del file robots.txt sia per la versione mobile che per quella desktop del sito.
- Utilizzare gli elementi corretti link rel=canonical e rel=alternate tra la versione mobile e quella desktop: l’URL desktop è sempre quello canonico e la versione mobile è l’alternativa a tale URL.
- Principali problemi con il mobile first indexing e troubleshooting
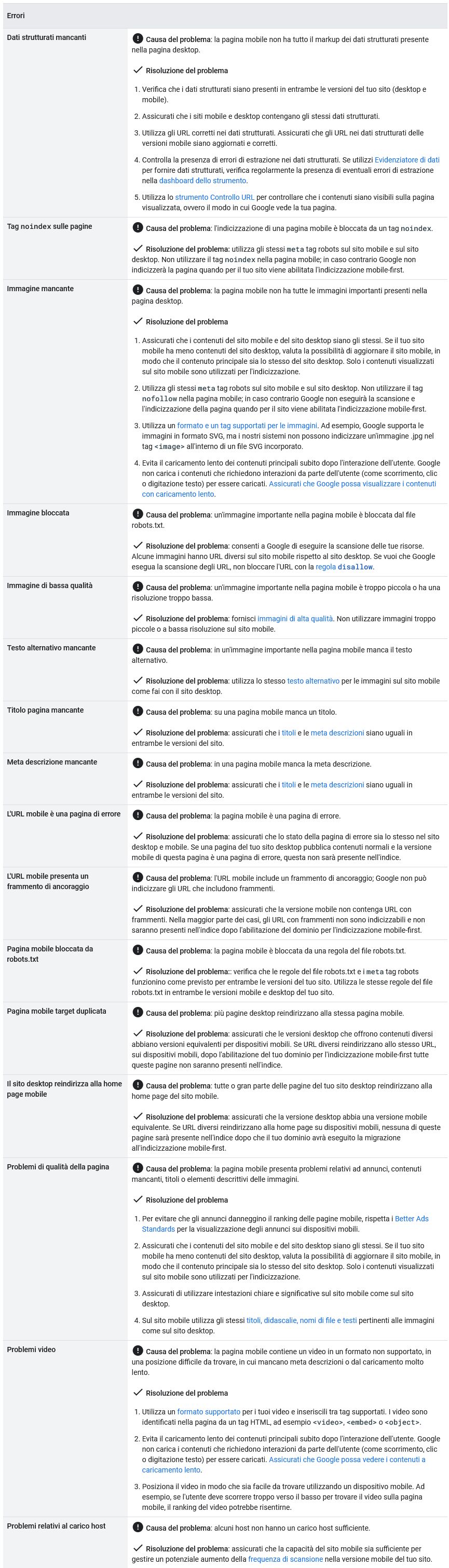
La guida di Google riporta anche un elenco degli errori più comuni che possono causare un calo del ranking dopo che un sito è stato abilitato per l’indicizzazione con priorità ai dispositivi mobili e delle possibili soluzioni, che riportiamo in questa infografica.
Come essere certi di avere un sito pronto e adatto al mobile-first index
Ancora nel 2022, come dicevamo, il lavoro di Googlebot mobile non era concluso e c’erano molti siti che non pronti allo switch, al punto che si rese necessario un ennesimo e ulteriore articolo di approfondimento, pubblicato sul blog ufficiale della compagnia per offrire altri spunti, indicazioni e consigli per preparare meglio i siti al mobile first indexing per tutti – che valgono anche ora come bussola per essere certi di aver lavorato bene.
Le informazioni (e le immagini successive) arrivano dal lavoro di Yingxi Wu, Google Mobile-First Indexing team, che inizia menzionando i vari tipi di problemi emersi nel corso degli anni di test e valutazioni di Google sull’indicizzazione mobile, che di fatto hanno portato alla consapevolezza che molti siti non sono ancora pronti.
Il nocciolo della questione è semplice (ma evidentemente di difficile realizzazione): nel mobile first indexing, Google ottiene le informazioni solo dalla versione mobile di un sito, quindi è fondamentale assicurarsi che Googlebot possa vedere l’intero contenuto e tutte le risorse in questa versione, facendo attenzione in particolare ad alcuni elementi.
Meta tag robots nella versione mobile
Il primo consiglio di Yingxi Wu è di utilizzare nella versione mobile gli meta tag robotsdi quelli previsti sulla versione desktop. Se ne usiamo uno differente sulla versione mobile (come noindex o nofollow), Google potrebbe non riuscire a indicizzare o seguire i link sulla pagina quando il sito è abilitato per l’indicizzazione mobile-first.
Lazy-loading nella versione mobile
Il sistema lazy-loading è più usato su dispositivi mobili che su desktop, soprattutto per il caricamento di immagini e video: la Googler raccomanda di far riferimento alle best practices (anche per la ottimizzazione delle immagini), e in particolare di caricare automaticamente il contenuto in base alla sua visibilità nella viewport e, soprattutto, evitare il lazy loading di contenuti primari basato sulle interazioni dell’utente (come scorrimento, clicking o digitazione), perché Googlebot non le attiverà.

Un esempio ci aiuta a comprendere meglio questo aspetto: se una pagina ha 10 immagini primarie sulla versione desktop e la versione mobile ne ha solo 2, con le altre 8 immagini caricate dal server solo quando l’utente fa clic sul pulsante “+”, Googlebot non cliccherà sul pulsante per caricare queste ulteriori 8 immagini, e quindi Google non vedrà quelle immagini. Il risultato è che tali risorse non saranno indicizzate o mostrate Google Immagini.
Consapevolezza di ciò che blocchiamo
Alcune risorse hanno URL diversi sulla versione mobile rispetto a quelli sulla versione desktop, a volte offerti anche su host diversi: se vogliamo che Google esegua la scansione di questi URL, dobbiamo verificare di non averli bloccati con un disallow nel file robots.txt.
Anche qui ci supporta un esempio: il blocco degli URL dei file .css impedirà a Googlebot di visualizzare correttamente le nostre pagine, con conseguente rischio di danneggiare il posizionamento delle stesse nella Ricerca. Allo stesso modo, il blocco degli URL delle immagini le farà scomparire da Google Immagini.
Fornire lo stesso contenuto primario su mobile e desktop
In linea di massima, quindi, ciò che conta è assicurarci che su desktop e dispositivo mobile ci sia lo stesso contenuto principale, ovvero “il contenuto con cui vuoi posizionarti o il motivo per cui gli utenti arrivano sul tuo sito”.
Con il nuovo (e neppure più tanto nuovo…) sistema, Google utilizza per l’indicizzazione e il posizionamento in Search solo i contenuti mostrati nella versione mobile: pertanto, se la nostra versione mobile ha meno contenuti rispetto a quella desktop, potrebbe essere necessario aggiornarla e riequilibrare questa situazione, o altrimenti il nostro sito rischierà di perdere un po’ di traffico al momento dell’abilitazione al mobile first indexing, perché Google non sarà più in grado di ottenere le informazioni complete.
Usare gli stessi titoli ed heading
Questo consiglio generale vale anche per gli aspetti più pratici.
Il primo elemento citato nell’articolo è usare gli stessi heading chiari e significativi sia sulla versione mobile sia sulla versione desktop: l’assenza di titoli significativi (l’aggettivo è ripetuto anche da Google) può influire negativamente sulla visibilità della nostra pagina sul motore di ricerca, perché Google potrebbe non essere in grado di comprendere appieno la pagina.
Ad esempio, se la pagina desktop ha il seguente tag per l’intestazione della pagina:
<h1>Foto di cuccioli carini sulla coperta</h1>
anche la versione mobile dovrebbe usare lo stesso tag con le stesse parole, anziché avere titoli come:
<h1>Foto</h1> (non chiaro e significativo)
<div>Foto di cuccioli carini sulla coperta</div> (non utilizzando un tag di intestazione)
Controllare immagini e video
Immagini e video hanno un ruolo sempre più decisivo per offrire agli utenti un’esperienza positiva e immersiva: per questo, Yingxi Wu consiglia di controllare alcuni aspetti specifici per ottimizzare il nostro sito e di rispettare alcune best practices sulle immagini.
In particolare, non dobbiamo utilizzare immagini troppo piccole o con una bassa risoluzione nella versione mobile, perché potrebbero non essere selezionate per l’inclusione in Google Immagini o mostrate positivamente quando indicizzate.

Ad esempio, se la nostra pagina ha 10 immagini primarie sulla versione desktop, normali e di buona qualità, è una cattiva pratica utilizzare miniature molto piccole nella versione mobile per adattarle tutte alla dimensione di schermo più piccola. Tali miniature potrebbero essere considerate “di bassa qualità” da Google perché appunto troppo piccole e con una bassa risoluzione.
Anche l’utilizzo di attributi alt meno significativi potrebbe influire negativamente sulla visualizzazione delle immagini in Google Immagini.
Una buona prassi è la seguente:
<img src=”dogs.jpg” alt=”Una foto di cucciolo carino sulla coperta”> (alt text significativo)
mentre sono sconsigliate le formulazioni seguenti:
<img src=”dogs.jpg” alt> (testo alternativo assente)
<img src=”dogs.jpg” alt=”Foto”> (alt text non significativo)
Gestire gli URL di immagine diversi tra versione desktop e mobile
Se il nostro sito utilizza URL di immagini diversi per la versione desktop e mobile, potremmo riscontrare una perdita temporanea di traffico da Google Immagini mentre il sito passa all’indicizzazione mobile-first. Il motivo dipende dal fatto che gli URL delle immagini nella versione mobile sono nuovi nel sistema di indicizzazione di Google e ci vuole del tempo prima siano compresi in modo appropriato.
Per ridurre al minimo questa perdita temporanea di traffico, possiamo verificare la possibilità di conservare gli URL di immagine utilizzati dal desktop.
Come gestire i video
Se per la versione desktop usiamo i dati strutturati VideoObject per descrivere i video, è importante che anche la versione mobile includa il VideoObject, fornendo informazioni equivalenti. In caso contrario, i sistemi di indicizzazione video di Google potrebbero avere difficoltà a ottenere informazioni sufficienti, e quindi i nostri video non saranno visibili nella Ricerca.
Anche la struttura della pagina mobile è un nodo cruciale, e la Googler suggerisce di sistemare video e immagini in una posizione facile da trovare. In caso contrario, si rischia di influire negativamente sull’esperienza dell’utente, e Google potrebbe non mostri in modo visibile nelle ricerche le nostre risorse multimediali.

Ad esempio, se abbiamo un video incorporato nei contenuti in una posizione facile da trovare sul desktop, dobbiamo fare attenzione a replicare questa struttura anche nella versione mobile.

Inserire un annuncio nella parte superiore della pagina, che occupa gran parte della stessa, potrebbe comportare lo spostamento del video fuori dalla pagina e richiedere agli utenti di scorrere molto verso il basso per trovare il video. In questo caso, la pagina potrebbe non essere considerata una landing page utile per i video dagli algoritmi di Google, e il video non sarà mostrato nella ricerca.
Mobile First Indexing, come risolvere i principali problemi
Un tema così caldo è finito inevitabilmente anche al centro di un episodio della serie Webmaster Conference Lightning Talks, che nel periodo del lockdown ha sostituito i classici eventi live di Google, con Martin Splitt che ha affrontato i possibili problemi che i siti (e SEO) possono riscontrare su questo versante e le best practices per preparare il sito a questo switch.
Che cos’è il mobile-first indexing, la scansione di Googlebot mobile
Si comincia comprensibilmente da un recap sulla definizione di mobile-first indexing e del funzionamento dell’indicizzazione da parte di Google.
In sintesi, dice Splitt, Googlebot esegue il crawl degli URL dal sito con user agent desktop e mobile. Con il vecchio sistema desktop-first indexing, il sistema di indicizzazione ottiene le informazioni della pagina dal contenuto della pagina in versione desktop; poi, se l’algoritmo ritiene che contiene informazioni di sufficiente rilevanza per le query degli utenti, la pagina sarà mostrata nei risultati di ricerca.
Con l’indicizzazione mobile, il sistema di indicizzazione cercherà le informazioni sulla pagina nella versione per dispositivi mobile invece che su quella desktop.
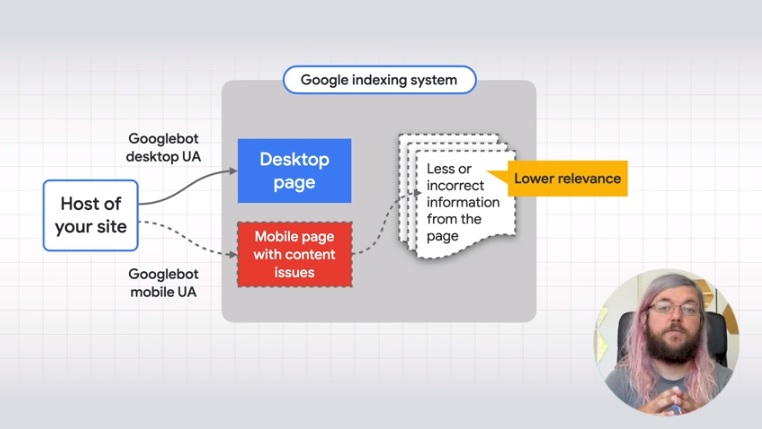
Le sfide e i possibili problemi per i siti
Chiarita la (basilare) differenza tra desktop-first e mobile-first indexing, il Googler si dedica a fare una panoramica delle possibili sfide che attendono i proprietari dei siti e i webmaster rispetto al sistema di indicizzazione per dispositivi mobile.
Ci possono essere errori durante il crawling, ad esempio, oppure problemi con i contenuti della pagina sottoposta a scansione: vediamo in dettaglio cosa si può fare in questi casi e come intervenire.
Caso 1, i problemi di crawling
Un problema frequente riguarda possibili errori nel crawling con Googlebot mobile: il nostro server potrebbe trattare in modo diverso la richiesta basata sull’user agent o potrebbero esserci altri problemi legati a una richiesta alle pagine mobili.
Quando si verificano queste situazioni, Google riuscirà a ricavare poche informazioni (o addirittura nessuna) dalle nostre pagine, e quindi ovviamente non potrà avere dati sufficienti per decidere di mostrare la pagina nei risultati di ricerca, col risultato che sarà esclusa dalle SERP.
Caso 2, problemi con i contenuti mobile
Un altro caso problematico è quando Google nota che la nostra pagina mobile ha problemi di contenuto: il bot otterrà minori informazioni dalla pagina, o addirittura riceverne di sbagliate, e quindi non potrà determinare in modo efficace la sua rilevanza per le query degli utenti.
Ciò si verifica soprattutto se un sito ha pagine mobili separate, che offrono contenuti diversi dalla versione desktop.
Riconoscere i principali problemi di crawling mobile
Entrambe queste situazioni impediscono a Google di servire bene il sito “quando è abilitato per il mobile-first indexing”, che è “qualcosa che probabilmente vorrai evitare”, ironizza il Developer Advocate nel video.
Per non incappare in questi problemi e risolverli, Splitt offre alcune indicazioni utili ed elementi da valutare per assicurarci che non ci siano issues durante la scansione delle pagine per dispositivi mobile. In particolare, NON dobbiamo:
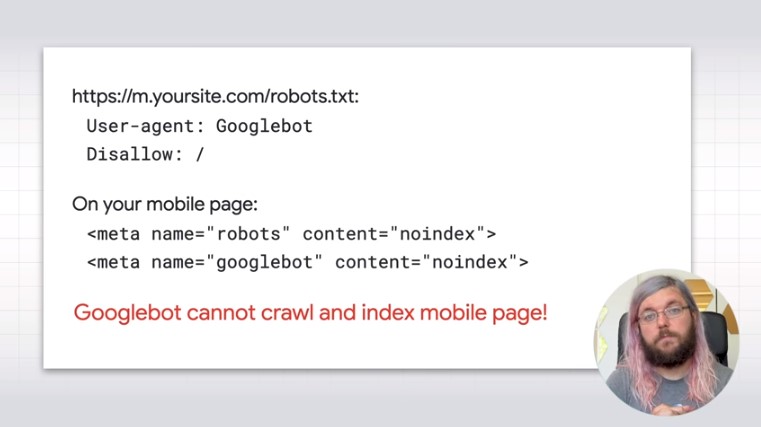
- Usare una direttiva Disallow nel file robots.txt per le pagine mobile.
- Utilizzare il meta tag noindex sulle pagine mobili.
Questi due errori non consentono a Googlebot di eseguire la scansione e l’indicizzazione delle pagine mobile (come si vede nell’immagine).
- Usare una direttiva disallow sui file CSS mobili con una regola nel robots.txt.
- Utilizzare il meta tag nofollow sui link interni.
Questi due errori non consentono a Googlebot di fare la scansione delle risorse mobile.

In generale, se diamo accesso a Googlebot a risorse sulla pagina desktop dovremmo fare lo stesso anche nella versione mobile, o altrimenti il bot non potrà analizzare e comprendere la pagina mobile a pieno.
In aggiunta a queste best practices su direttive robots.txt, tag noindex e nofollow, i proprietari dei siti dovrebbero anche controllare la capacità di scansione del proprio server: a livello ideale, un server dovrebbe essere in grado di gestire la stessa quantità di scansioni desktop e mobile.
Individuare i problemi di contenuto delle pagine mobile
Impostare correttamente il contenuto della pagina mobile è importante quanto verificare che siano esatte le impostazioni del crawler mobile. Il suggerimento generale di Google è di assicurarsi di servire un contenuto primario identico in entrambe le versioni, desktop e mobile, ma in alcuni casi questo potrebbe essere differente.
Contenuti diversi tra mobile e desktop
Ad esempio, dice Splitt, potremmo avere una pagina desktop che si presenta con varie immagini e un po’ di testo, mentre nella versione mobile decidiamo di presentare due sole immagini e pochissimo testo: gli utenti devono cliccare sul pulsante + (più) per far caricare la parte rimanente della pagina.
Tuttavia, Googlebot non farà clic sul pulsante, e quindi tutte le informazioni non immediatamente caricate saranno invisibili per Google. Pertanto – anche come nota generale – il Googler dice che se abbiamo intenzione di avere meno contenuto sulla pagina mobile, dobbiamo essere consapevoli che Google potrebbe non essere in grado di servire il nostro sito così come prima del mobile-first indexing, proprio perché ottiene (diamo) meno informazioni rispetto all’indicizzazione desktop.
Gestione degli heading
Gli heading sono importanti per Googlebot per capire la nostra pagina: usare i classici tag è un “buon esempio di intestazione”, mentre è sbagliato utilizzare i comandi <div>.
In questo caso, indipendentemente dalla sua classe, Googlebot tratterà questa porzione di testo come se fosse un testo normale e non un titolo; ciò influenzerà quindi la comprensione della pagina da parte di Googlebot.

Il consiglio pratico è quindi di far riferimento ai tag di intestazione semantici sulle nostre pagine mobili.
Gestione delle immagini e dei video
“Se ci tieni al traffico generato da immagini e video, devi fare qualche check extra su tali risorse”, ci dice Splitt.
In primis, è importante curare la creazione dell’alt text per definire un’immagine e non lasciare vuoto il campo o inserire termini troppo generici, perché tale pratica può provocare una cattiva esperienza per alcuni utenti, che non avrebbero modo di capire il topic dell’immagine quando non riescono a visualizzarla. Come nel caso precedente, non possiamo inserire gli attributi nell’immagine in un campo <div> perché Googlebot non può leggere e indicizzare le risorse in questo modo, ma utilizzare quindi solo tag di immagine semantici.

Oltre a questi classici consigli per gestione SEO delle immagini, per le pagine mobile è importante anche curare la posizione delle risorse multimediali: se un video è in posizione facile da vedere nella versione desktop, la presenza di un annuncio potrebbe spostarlo nella pagina mobile, costringendo gli utenti a scrollare molto in basso per vedere finalmente il contenuto e generando, ancora una volta, una cattiva user experience.
Controllare le parti invisibili delle pagine
L’ultimo aspetto a cui prestare attenzione è la gestione delle parti invisibili della pagina – ovviamente, Splitt non si riferisce a tattiche di black hat SEO e contenuti nascosti! – che non hanno effetti sulla user experience, ma possono influenzare il modo in cui Googlebot comprende i contenuti presenti e i topic trattati.
Un esempio di parte invisibile della pagina sono i dati strutturati: la best practice è mantenere gli stessi markup su desktop e pagine mobili.
Un altro esempio sono le meta description, e Google invita a non dimenticare di aggiungere queste informazioni alle nostre pagine mobili, perché le meta descrizioni “sono molto importanti anche per Googlebot”.
