
Crawl budget: cos’è, perché interessa la SEO e come ottimizzare il valore

È il parametro che identifica il tempo e le risorse che Google intende dedicare a un sito web attraverso le scansioni di Googlebot, un valore non univoco e definibile numericamente, come chiarito ripetutamente dalle fonti ufficiali della compagnia, anche se possiamo comunque intervenire per ottimizzarlo. Oggi parliamo di crawl budget, un argomento che sta diventando sempre più centrale per il miglioramento delle performance dei siti, e delle varie strategie per ottimizzare questo parametro e perfezionare l’attenzione che il crawler può dedicare a contenuti e pagine per noi prioritarie.
Che cos’è il crawl budget
Il mio sito web piace a Google? Questa è la domanda che dovrebbero farsi tutti quelli hanno un sito web che desiderano posizionare sui motori di ricerca. Esistono diversi metodi per capire se effettivamente un sito piace a Big G, ad esempio attraverso i dati presenti all’interno di Google Search Console e del rapporto Statistiche di Scansione, uno strumento che ci permette di conoscere appunto le statistiche di scansione degli ultimi 90 giorni e di scoprire quanto tempo il motore di ricerca dedica al nostro sito.
Detto in maniera ancora più semplice, in questo modo possiamo scoprire qual è il crawl budget che ci ha dedicato Big G, la quantità di tempo e risorse che Google dedica alla scansione di un sito.
La definizione di crawl budget
Il crawl budget è un parametro, o meglio un valore, che Google assegna al nostro sito. In pratica è proprio come un budget che Googlebot ha a disposizione per scansionare le pagine del nostro sito. Attraverso Search Console è possibile capire quanti file, pagine e immagini vengono scaricati e scansionati ogni giorno dal motore di ricerca.
È facile capire che più alto è questo valore, più abbiamo importanza per il motore di ricerca stesso. In pratica, se ogni giorno Google scansiona e scarica tante pagine, significa che vuole i nostri contenuti perché considerati di qualità e valore per la composizione delle sue SERP.
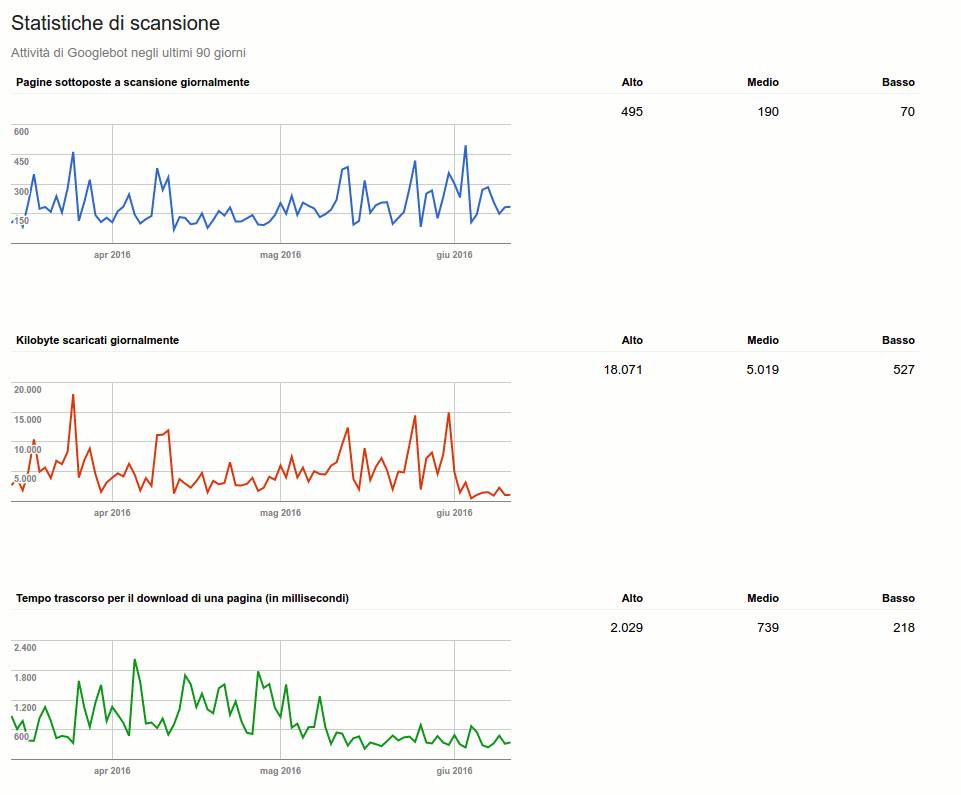
 Principalmente i valori da tenere in considerazione sono sicuramente due, ovvero il numero di pagine che Google scansiona ogni giorno e il tempo che impiega per farlo. Andiamo a vedere nel dettaglio il tutto:
Principalmente i valori da tenere in considerazione sono sicuramente due, ovvero il numero di pagine che Google scansiona ogni giorno e il tempo che impiega per farlo. Andiamo a vedere nel dettaglio il tutto:
- Pagine sottoposte a scansione giornalmente: il valore ideale è quello di avere un numero totale di pagine scansionate più alto del numero delle pagine presenti sul sito web, ma anche un pareggio (pagine scansionate uguale al numero di pagine del sito web) va più che bene.
- Tempo trascorso per il download: questo indica principalmente il tempo che impiega Googlebot per effettuare una scansione delle nostre pagine, bisognerebbe mantenere basso questo valore andando ad aumentare la velocità del nostro sito web. Questo andrà a influire anche sul numero di kb scaricati dal motore di ricerca durante le scansioni, ovvero con quanta facilità (e velocità) Google riesce a “scaricare” le pagine di un sito web.
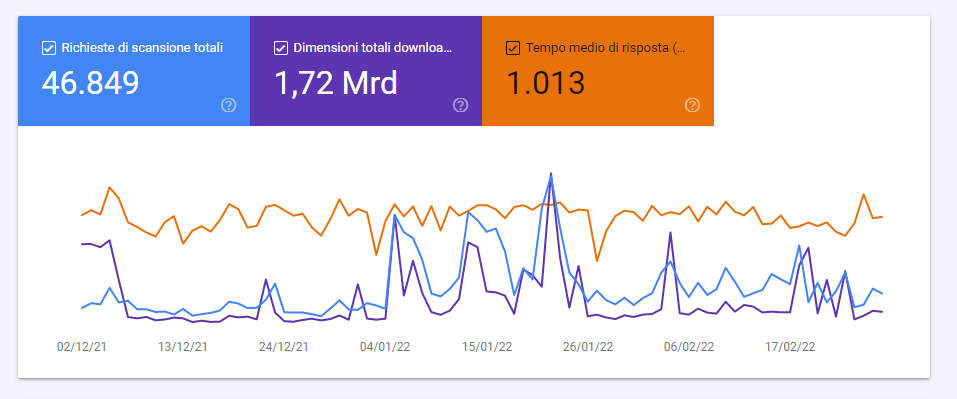
Le due immagini qui pubblicate mostrano anche l’evoluzione di questo dominio: i valori che nel 2016 (screen in alto) segnalavano un’attività media oggi sono invece indice di una richiesta di bassa intensità.
Che cos’è il crawl budget per Google
Cambiando approccio, il crawl budget è il numero di URL che Googlebot può (in base alla velocità del sito) e vuole (in base alla domanda degli utenti) sottoporre a scansione. Concettualmente, quindi, è la frequenza bilanciata tra i tentativi di Googlebot di non sovraccaricare il server e il desiderio generale di Google di eseguire la scansione del dominio.
Curare questo aspetto potrebbe permettere di aumentare la velocità con cui i robot dei motori di ricerca visitano le pagine del sito; maggiore è la frequenza di questi passaggi, più rapidamente l’indice rileva gli aggiornamenti delle pagine. Quindi, un valore più alto di ottimizzazione del crawl budget può potenzialmente aiutare a mantenere aggiornati i contenuti popolari e impedire che i contenuti più vecchi diventino obsoleti.
Come dice la nuova guida ufficiale a questa tematica, aggiornata l’ultima volta alla fine di febbraio 2023, il crawl budget nasce in risposta a un problema: il Web è uno spazio praticamente infinito e l’esplorazione e l’indicizzazione di ogni URL disponibile va ben oltre le capacità di Google, ed è per questo che il tempo che Googlebot può dedicare alla scansione di un singolo sito è limitato – ovvero, il parametro del budget di scansione. Inoltre, non tutti gli elementi sottoposti a scansione sul sito verranno necessariamente indicizzati: ogni pagina deve essere valutata, accorpata e verificata per stabilire se verrà indicizzata dopo la scansione.
Come si misura il crawl budget
Il crawl budget si può allora definire come il numero di URL che Googlebot può e desidera sottoporre a scansione, e determina il numero di pagine che i motori di ricerca scansionano durante una sessione di ricerca per la indicizzazione. In termini tecnici, il suo valore dipende dal limite di capacità di scansione (crawl rate) e dalla domanda di scansione (crawl demand).
Che cosa sono il crawl rate e crawl demand
Con l’espressione crawl rate si fa riferimento al numero di richieste al secondo che uno spider effettua verso un sito e il tempo che passa tra le fetches, mentre la crawl demand è la frequenza con cui tali bot eseguono la scansione. Per questo, secondo i consigli ufficiali di Google, i siti che devono essere più attenti a questi aspetti sono quelli di dimensioni maggiori e con più pagine o quelli che hanno pagine auto-generate basate su parametri URL.
Andando più a fondo con le spiegazioni, il compito di Googlebot è eseguire la scansione di ogni sito senza sovraccaricare i suoi server, e quindi calcola questo limite di capacità di scansione rappresentato dal numero massimo di connessioni simultanee che può utilizzare per eseguire la scansione di un sito e dal ritardo tra recuperi, in modo comunque da fornire la copertura di tutti i contenuti importanti, senza sovraccaricare i server.
Il limite del crawl rate o capacità di scansione è dato innanzitutto dal rispetto per il sito: Googlebot cercherà di non peggiorare mai l’esperienza degli utenti a causa di un sovraccarico di fetching. Dunque, esiste per ogni sito un numero massimo di connessioni parallele simultanee che Googlebot può utilizzare per eseguire la scansione, e la velocità di scansione può aumentare o diminuire in base:
- Alla salute del sito e del server. In sintesti, se un sito risponde velocemente, il limite si alza e Google usa più connessioni per il crawling; se la scansione è lenta o si presentano errori di server, il limite scende.
- Al limite imposto dal proprietario in Search Console, ricordando che l’impostazione di limiti più elevati non aumenta automaticamente la frequenza di scansione
- Ai limiti di scansione di Google, che come detto dispone di risorse ragguardevoli, ma non illimitate, e deve pertanto assegnare priorità per ottimizzarne l’impiego.
La crawl demand, invece, è legata alla popolarità: gli URL che sono più popolari sul Web sono tendenzialmente sottoposti a scansione più frequentemente per tenerli “più freschi” nell’Indice di Google. Inoltre, i sistemi del motore di ricerca cercano di impedire la staleness, ovvero che gli URL diventino obsoleti nell’indice.
In genere, specifica la citata guida, Google dedica tutto il tempo necessario alla scansione di un sito in base a dimensioni del sito stesso, frequenza di aggiornamento, qualità delle pagine e pertinenza, in modo commisurato agli altri siti. Pertanto, i fattori che svolgono un ruolo significativo nel determinare la domanda di scansione sono i seguenti:
- Inventario percepito: in mancanza di indicazioni del sito, Googlebot proverà a eseguire la scansione di tutti gli URL o della maggior parte degli URL noti sul sito stesso. Se trova un numero elevato di URL duplicati o pagine che non è necessario sottoporre a scansione perché rimosse, non importanti o altro, Google potrebbe impiegare più tempo del dovuto per eseguirne la scansione. Questo è il fattore che possiamo tenere maggiormente sotto controllo.
- Popolarità: gli URL più popolari su Internet tendono a essere sottoposti più spesso a scansione per tenerli costantemente aggiornati nell’Indice.
- Mancato aggiornamento: i sistemi ripetono la scansione dei documenti con una frequenza sufficiente a rilevare eventuali modifiche.
- Eventi a livello di sito, come il trasferimento del sito, possono generare un aumento della domanda di scansione per reindicizzare i contenuti in base ai nuovi URL.
Riassumendo, quindi, Google determina la quantità di risorse di scansione da assegnare a ciascun sito in base a fattori come popolarità, valore per l’utente, unicità e capacità di pubblicazione; ai fini del budget viene conteggiato qualsiasi URL di cui Googlebot esegue la scansione, compresi gli URL alternativi, come AMP o hreflang, i contenuti incorporati, come CSS e JavaScript, e i recuperi XHR, che possono quindi consumare il budget di scansione di un sito. Inoltre, anche se il limite di capacità di scansione non viene raggiunto, la frequenza di scansione di Googlebot può essere inferiore se la domanda di scansione del sito è bassa.
Gli unici due modi per aumentare il crawl budget sono aumentare la capacità di pubblicazione per le scansioni e, soprattutto, aumentare il valore dei contenuti del sito per gli utenti che effettuano ricerche.
Perché il crawl budget è importante per la SEO
Quando ottimizzato, il crawl budget consente ai webmaster di assegnare una priorità alle pagine che devono scansionate e indicizzate per prime, nel caso in cui i crawler possano analizzare ogni percorso. Al contrario, sprecare risorse del server in pagine che non generano risultati e non producono effettivamente un valore produce un effetto negativo e rischia di non far emergere i contenuti di qualità di un sito.
Come aumentare il crawl budget
Ma esiste un modo per andare ad aumentare il crawl budget che Google stesso ci mette a disposizione? La risposta è sì e bastano alcuni accorgimenti.
Uno dei metodi per incrementare il crawl budget è sicuramente quello di aumentare il trust del sito. Come sappiamo bene, tra i fattori di posizionamento di Google ci sono sicuramente i link: se un sito è linkato vuol dire che è “consigliato” e di conseguenza il motore di ricerca lo interpreta proprio come un consiglio e, quindi, va a prendere in considerazione quel contenuto.
A influire sul crawl budget è anche la frequenza di aggiornamento del sito, ovvero quanti contenuti nuovi vengono creati e con quale periodicità. In pratica, se Google arriva su un sito web e scopre ogni giorno pagine nuove quello che farà è ridurre il tempo di scansione del sito stesso. Un esempio concreto: di solito, un sito di notizie che pubblica 30 articoli al giorno avrà un tempo di scansione più corto rispetto a un blog che pubblica un articolo al giorno.
Un altro modo per aumentare il crawl budget è sicuramente la velocità del sito web, ovvero la risposta del server nel servire a Googlebot la pagina richiesta. Possiamo, infine, usare anche il file robots.txt per evitare che Googlebot vada a scansionare quelle pagine che hanno all’interno il tag “noindex” o il tag “canonical”, per evitare che debba comunque vederle e scansionarle per sapere se può indicizzarle o meno; usando il robots.txt in modo intelligente, quindi, possiamo permettere al crawler di concentrarsi sulle pagine migliori del sito web.
Come migliorare il crawl budget
Più in generale, uno dei modi più immediati per ottimizzare il crawl budget è limitare la quantità di URL a basso valore presenti su un sito Web, che possono come detto sottrarre tempo e risorse preziose all’attività di scansione delle pagine più importanti di un sito.
Tra le pagine a basso valore rientrano quelle che presentano contenuto duplicato, le pagine di errore soft, la faceted navigation e i session identifiers, e poi ancora pagine compromesse da hacking, spazi e proxy infiniti e ovviamente contenuti di bassa qualità e spam. Un primo lavoro che si può fare è dunque verificare la presenza di questi problemi sul sito, controllando anche i rapporti sugli errori di scansione in Search Console e riducendo al minimo gli errori del server.
I consigli di Google per ottimizzare l’efficienza del crawling
Prima di scoprire quali sono i suggerimenti sponda SEO, possiamo leggere quali sono le best practice per massimizzare l’efficienza delle scansioni che arrivano direttamente da Google.
Come ripetuto spesso, a preoccuparsi del crawl budget dovrebbero essere in particolare tre categorie di siti (le cifre indicate sono solo una stima approssimativa e non sono da considerarsi soglie precise):
- Siti di grandi dimensioni (oltre un milione di pagine univoche) con contenuti che cambiano con una certa frequenza (una volta a settimana).
- Siti di medie o grandi dimensioni (oltre 10.000 pagine univoche) con contenuti che cambiano molto spesso (ogni giorno).
- Siti con una porzione consistente di URL totali classificati da Search Console come Rilevata, ma attualmente non indicizzata.
Ma ovviamente anche tutti gli altri siti possono trarre giovamento e spunti di ottimizzazione da questi interventi.
- Gestire l’inventario di URL, utilizzando gli strumenti appropriati per comunicare a Google quali pagine è necessario o meno sottoporre a scansione. Se Google dedica troppo tempo alla scansione di URL non idonei all’indicizzazione, Googlebot potrebbe decidere che non vale la pena esaminare il resto del sito (né tantomeno aumentare il budget per farlo). In concreto, possiamo:
- Accorpare i contenuti duplicati, per concentrare la scansione su contenuti univoci anziché su URL univoci.
- Bloccare la scansione degli URL utilizzando il file robots.txt., così da ridurre la probabilità di indicizzazione degli URL che non desideriamo siano visualizzati nei risultati della Ricerca, ma che fanno riferimento a pagine importanti per gli utenti, e quindi da mantenere intatte. Un esempio sono le pagine a scorrimento continuo che duplicano informazioni su pagine collegate o le versioni della stessa pagina ordinate in modo diverso.
A questo proposito, la guida invita a non utilizzare il tag noindex, in quanto Google ne eseguirà comunque la richiesta, anche se poi abbandonerà la pagina non appena rileva un meta tag o un’intestazione noindex nella risposta HTTP, sprecando tempo per la scansione. Parimenti, non dobbiamo utilizzare il file robots.txt per riallocare temporaneamente del budget di scansione per altre pagine, ma solo per bloccare le pagine o le risorse che non vogliamo che siano sottoposte a scansione. Google non trasferirà il nuovo budget di scansione disponibile ad altre pagine, a meno che non stia già raggiungendo il limite di pubblicazione del sito.
- Restituire un codice di stato 404 o 410 per le pagine rimosse Google non eliminerà un URL noto, ma un codice di stato 404 segnala in modo chiaro di evitare la nuova scansione di quel dato URL; gli URL bloccati continueranno a rimanere nella coda di scansione, anche se verranno sottoposti nuovamente a scansione solo con la rimozione del blocco.
- Eliminare gli errori soft 404. Le pagine soft 404 continueranno a essere sottoposte a scansione e a incidere negativamente sul budget.
- Mantenere aggiornate le Sitemap, includendo tutti i contenuti che vogliamo che siano sottoposti a scansione. Se il sito include contenuti aggiornati, dobbiamo includere il tag <lastmod>.
- Evitare lunghe catene di reindirizzamento, che hanno un effetto negativo sulla scansione.
- Verificare che le pagine si carichino in modo efficiente: se Google riesce a caricare e visualizzare le pagine più velocemente, è possibile che riesca a leggere più contenuti sul sito.
- Monitorare la scansione del sito, controllando se il sito ha riscontrato problemi di disponibilità durante la scansione e cercando dei modi per renderla più efficiente.
Come migliorare l’efficienza della scansione di un sito
La guida del motore di ricerca ci offre anche altre indicazioni preziose per provare a gestire in modo efficiente il budget di scansione. In particolare, ci sono una serie di interventi che ci permettono di aumentare la velocità di caricamento della pagina e delle risorse presenti.
Come detto, la scansione di Google è limitata da fattori come larghezza di banda, tempo e disponibilità delle istanze di Googlebot: quanto più veloce è risposta del sito, tanto maggiore è il numero di pagine che è possibile vengano sottoposte a scansione. Di fondo, però, Google vorrebbe eseguire solo (o comunque prioritariamente) la scansione di contenuti di alta qualità, e quindi velocizzare il caricamento di pagine di scarsa qualità non induce Googlebot a estendere la scansione del sito e ad aumentare il budget di scansione, cosa che potrebbe avvenire invece se facciamo capire a Google che può rilevare contenuti di alta qualità. Tradotto in termini pratici, possiamo ottimizzare in questo modo le pagine e le risorse per la scansione:
- Impedire a Googlebot il caricamento di risorse di grandi dimensioni, ma non importanti, utilizzando il file robots.txt, bloccando solo le risorse non critiche, ossia risorse non importanti per comprendere il significato della pagina (come immagini a scopo decorativo).
- Verificare che le pagine vengano caricate rapidamente.
- Evitare lunghe catene di reindirizzamento, che hanno un effetto negativo sulla scansione.
- Verificare il tempo di risposta alle richieste del server e il tempo necessario per il rendering delle pagine, incluso il tempo di caricamento e di esecuzione delle risorse incorporate, come immagini e script, che sono tutti importanti, facendo attenzione a risorse voluminose o lente necessarie per l’indicizzazione.
Sempre dal punto di vista tecnico, un consiglio diretto è di specificare le modifiche ai contenuti con codici di stato HTTP, perché generalmente Google supporta per la scansione le intestazioni delle richieste HTTP If-Modified-Since e If-None-Match. I crawler di Google non inviano le intestazioni con tutti i tentativi di scansione, ma dipende dal caso d’uso della richiesta: quando i crawler inviano l’intestazione If-Modified-Since, il valore dell’intestazione equivale alla data e all’ora dell’ultima scansione dei contenuti, in base al quale il server potrebbe scegliere di restituire un codice di stato HTTP 304 (Not Modified) senza un corpo della risposta, spingendo Google a riutilizzare la versione dei contenuti sottoposta a scansione l’ultima volta. Se i contenuti sono successivi alla data specificata dal crawler nell’intestazione If-Modified-Since, il server può restituire un codice di stato HTTP 200 (OK) con il corpo della risposta. Indipendentemente dalle intestazioni della richiesta, se i contenuti non sono cambiati dall’ultima volta che Googlebot ha visitato l’URL possiamo però inviare un codice di stato HTTP 304 (Not Modified) e nessun corpo della risposta per qualsiasi richiesta di Googlebot: ciò consentirà di risparmiare tempo e risorse di elaborazione del server, il che potrebbe migliorare indirettamente l’efficienza della scansione.
Altro intervento pratico è nascondere gli URL che non desideriamo siano visualizzati nei risultati di ricerca: lo spreco di risorse del server su pagine superflue può compromettere l’attività di scansione di pagine per noi importanti, comportando un ritardo significativo nel rilevamento di contenuti nuovi o aggiornati su un sito. Se è vero che bloccare o nascondere le pagine già sottoposte a scansione non trasferirà il budget di scansione a un’altra parte del sito, a meno che Google non stia già raggiungendo i limiti di pubblicazione del sito, possiamo comunque lavorare sulla riduzione delle risorse utili, e in particolare evitare di mostrare a Google un numero elevato di URL del sito che non vogliamo vengano sottoposti a scansione dalla Ricerca. In genere, questi URL rientrano nelle seguenti categorie:
- Navigazione per facet e identificatori di sessione: la navigazione per facet estrapola in genere contenuti duplicati dal sito e gli identificatori di sessione, così come altri parametri URL, ordinano o filtrano la pagina ma non forniscono nuovi contenuti.
- Contenuti duplicati, che generano una scansione superflua.
- Pagine soft 404.
- Pagine compromesse, da ricercare e correggere attraverso il report Problemi di sicurezza.
- Spazi infiniti e proxy.
- Scarsa qualità e contenuti spam.
- Pagine del carrello degli acquisti, pagine a scorrimento continuo e pagine che eseguono un’azione (come pagine con invito a registrarsi o ad acquistare).
Il file robots.txt è il nostro strumento utile quando non vogliamo che Google esegua la scansione di una risorsa o di una pagina (ma riservando le entrate solo per quelle pagine o risorse che non vogliamo vengano visualizzate su Google per lunghi periodi di tempo); inoltre, se una stessa risorsa viene riutilizzata su più pagine (ad esempio un’immagine o un file JavaScript condiviso), il consiglio è di far riferimento alla risorsa utilizzando il medesimo URL in ogni pagina, in modo che Google possa memorizzare e riutilizzare tale risorsa, senza doverla richiedere più volte.
Sono invece sconsigliate pratiche come aggiungere o rimuovere con assiduità pagine o directory dal file robots.txt per riallocare il budget di scansione per il sito e alternare tra Sitemap o utilizzare altri meccanismi di occultamento temporanei per riallocare il budget.
Come ridurre le richieste di scansione di Google
Se il problema è esattamente l’opposto – e quindi siamo di fronte a un caso di scansione eccessiva del sito – abbiamo alcune azioni da seguire per evitare il sovraccarico del sito, ricordando comunque che Googlebot è dotato di algoritmi che gli impediscono di sovraccaricare il sito con richieste di scansione. La diagnosi di questa situazione va fatta attraverso un monitoraggio del server, per verificare che effettivamente il sito sia in difficoltà a causa di eccessive richieste da Googlebot, mentre la gestione prevede di:
- Restituire temporaneamente codici di stato della risposta HTTP 503 o 429 per le richieste di Googlebot quando il tuo server è sovraccarico. Googlebot riproverà a eseguire nuovamente la scansione di questi URL per circa 2 giorni, ma la restituzione dei codici di tipo “nessuna disponibilità” per più di alcuni giorni comporterà il rallentamento o l’interruzione definitiva della scansione degli URL sul sito (e l’eliminazione dall’indice), quindi dobbiamo procedere con gli altri step
- Ridurre la frequenza di scansione di Googlebot per il sito. Questa operazione può richiedere fino a due giorni per diventare effettiva e richiede l’autorizzazione dell’utente proprietario della proprietà in Search Console, e va eseguita solo se nel grafico di Disponibilità dell’host > Utilizzo dell’host del report Statistiche di scansione notiamo che Google sta eseguendo da diverso tempo un numero eccessivo di scansioni ripetute.
- Se la frequenza di scansione diminuisce, interrompere la restituzione dei codici di stato della risposta HTTP 503 o 429 per le richieste di scansione; se restituisci 503 o 429 per più di 2 giorni.
- Eseguire il monitoraggio della scansione e della capacità dell’host nel tempo e, se necessario, aumentare di nuovo la frequenza di scansione o abilitare la frequenza di scansione predefinita.
- Se a causare il problema è uno dei crawler di AdsBot, è possibile che abbiamo creato target per gli annunci dinamici della rete di ricerca per il sito e che Google stia tentando di eseguirne la scansione. Questa scansione viene ripetuta ogni due settimane. Se la capacità del server non è sufficiente a gestire queste scansioni, possiamo limitare i target degli annunci o richiedere un aumento della capacità di pubblicazione.
Ottimizzazione del crawl budget per la SEO, le best practices
Un approfondimento su Search Engine Land di Aleh Barysevich presenta un elenco di consigli per ottimizzare il crawl budget e migliorare la crawlability di un sito, con 8 regole semplici da seguire per ogni sito:
- Non bloccare le pagine importanti.
- Resta fedele al codice HTML quando possibile, evitando file pesanti in JavaScript o altri formati.
- Risolvi le catene di redirect troppo lunghe.
- Segnala a Googlebot i parametri degli URL.
- Correggi gli errori HTTP.
- Mantieni aggiornate le Sitemap.
- Usa il rel canonical per evitare contenuti duplicati.
- Usa i tag hreflang per indicare il Paese e la lingua.
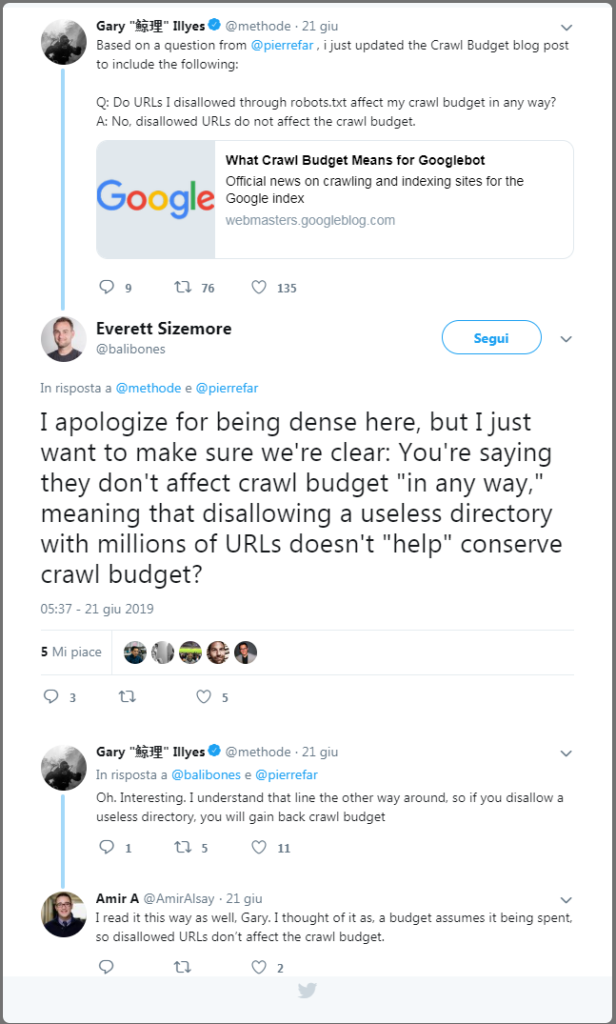
Un ulteriore consiglio tecnico per ottimizzare il crawl budget di un sito arriva da Gary Illyes, che spiega come impostare il disallow sugli URL non rilevanti permette di non pesare sul crawl budget, e dunque usare il comando disallow nel file robots può consentire di gestire meglio la scansione di Googlebot. Nello specifico, in una conversazione su Twitter il Googler ha spiegato che “se usi il disallow su una directory inutile con milioni di URL guadagni crawl budget”, perché il bot dedicherà il suo tempo ad analizzare e sottoporre a scansione risorse più utili del sito.
I possibili interventi di ottimizzazione sul sito
Approfondendo i consigli descritti possiamo quindi definire alcuni interventi specifici che potrebbero aiutare a gestire meglio il crawl budget del sito: nulla di particolarmente “nuovo”, perché si tratta di alcuni noti segnali della salute del sito web.
Il primo suggerimento è quasi banale, ovvero consentire la scansione delle pagine importanti del sito nel file robots.txt, un passo semplice ma decisivo per avere sotto controllo le risorse sottoposte a scansione e quelle bloccate. Ugualmente, è bene prendersi cura della sitemap XML, così da dare ai robot un modo semplice e più veloce di comprendere dove conducono i collegamenti interni; ricordiamoci di usare solo gli URL canonici per la sitemap e di aggiornarla sempre alla versione più recente caricata del robots.txt – mentre invece non serve a molto comprimere le Sitemap, perché devono comunque essere recuperate sul server e questo non equivale a un risparmio sensibile in termini di tempo o di impegno per Google.
Sarebbe poi bene verificare – o evitare del tutto – le catene di reindirizzamento, che costringono Googlebot a sottoporre a scansione più URL: in presenza di una quota eccessiva di redirect, il crawler del motore di ricerca potrebbe improvvisamente terminare la scansione senza raggiungere la pagina che deve indicizzare. Se i 301 e 302 andrebbero limitati, altri codici di stato HTTP sono ancora più nocivi: le pagine in 404 e 410 pagine tecnicamente consumano crawl budget e, per di più, danneggiano anche l’user experience del sito. Non meno fastidiosi sono gli errori 5xx legati al server, motivo per il quale è bene fare un’analisi periodica e un checkup di salute del sito, usando magari il nostro SEO spider!
Un’altra riflessione da fare riguarda i parametri URL, perché gli URL separati vengono conteggiati dai crawler come pagine separate, e quindi sprecano in modo inestimabile parte del budget e rischiano anche di sollevare dubbi sui contenuti duplicati. Nei casi di siti multilingua, poi, dobbiamo usare al meglio il tag hreflang, informando nel modo più chiaro possibile Google delle versioni geolocalizzate delle pagine, sia con l’header che con l’elemento <loc> per un dato URL.
Una scelta di fondo per migliorare la scansione e semplificare l’interpretazione di Googlebot potrebbe essere infine quella di preferire sempre l’HTML agli altri linguaggi: anche se Google sta imparando a gestire JavaScript in maniera sempre più efficace (e ci sono tante tecniche per l’ottimizzazione SEO di JavaScript), il vecchio HTML resta ancora il codice che dà maggiori garanzie.
Le criticità SEO del crawl budget
Uno dei Googler che più spesso si è dedicato a questo tema è John Mueller che, in particolare, ha ribadito anche su Reddit che non c’è un benchmark per il crawl budget di Google, e che quindi non esiste un “numero” di riferimento ottimale verso cui tendere con gli interventi sul sito.
Quello che possiamo fare, in termini pratici, è cercare di ridurre gli sprechi sulle pagine “inutili” del nostro sito – vale a dire quelle che non hanno keyword posizionate o che non generano visite – per ottimizzare l’attenzione che Google dedica ai contenuti per noi importanti e che possono rendere di più in ottica di traffico.
L’assenza di un parametro di riferimento o un valore ideale a cui tender fa basare tutta la discussione sul crawl budget si basa su astrazioni e teorie: quel che sappiamo di certo è che Google solitamente è più lento a eseguire la scansione di tutte le pagine di un piccolo sito che non si aggiorna spesso o non ha molto traffico rispetto a quella di un grande sito con molte modifiche giornaliere e una quantità significativa di traffico organico.
Il problema sta nel quantificare i valori di “spesso” e “molto”, ma soprattutto nell’individuare un numero univoco sia per i siti enormi e potenti che per i piccoli blog; ad esempio, sempre in linea teorica, un valore X di crawl budget raggiunto da un sito web di rilievo potrebbe essere problematico, mentre per un blog con poche centinaia di pagine e poche centinaia di visitatori al giorno potrebbe essere il livello massimo raggiunto, difficile da migliorare.
Dare priorità alle pagine rilevanti per noi
Per questo motivo, un’analisi seria di questo “budget di ricerca per indicizzazione” si deve concentrare su una gestione complessiva del sito, cercando di migliorare la frequenza dei risultati su pagine importanti (quelle che convertono o che attraggono traffico) utilizzando strategie diverse, piuttosto che cercare di ottimizzare la frequenza complessiva dell’intero sito.
Tattiche rapide per raggiungere questo obiettivo sono i redirect per portar via Googlebot da pagine meno importanti (bloccandole dalla scansione) e l’uso dei link interni per incanalare una maggiore importanza sulle pagine che si desidera promuovere (che, ça va sans dire, devono fornire contenuti di qualità). Se operiamo bene in questa direzione – usando anche gli strumenti di SEOZoom per verificare su quali URL conviene concentrarsi e concentrare le risorse – potremmo aumentare la frequenza dei passaggi di Googlebot sul sito, perché Google dovrebbe teoricamente vedere più valore nell’inviare traffico alle pagine che indicizza, aggiorna e classifica del sito.
Capire se un sito piace a Google senza Search Console (e con SEOZoom)
Se non abbiamo accesso alla Search Console (ad esempio, se il sito non è nostro), c’è comunque un modo per capire se il sito sta piacendo al motore di ricerca grazie a SEOZoom e alla Zoom Authority, la nostra metrica nativa che fa individuare immediatamente quanto è influente e rilevante un sito per Google.
La ZA prende in considerazione molti criteri e, dunque, non solo le pagine posizionate nella top 10 di Google o il numero di link ottenuti, e quindi un valore elevato equivale a un gradimento generale del motore di ricerca, che premia con visibilità frequente i contenuti di quel sito – e possiamo anche analizzare la pertinenza per argomento attraverso la metrica della Topical Zoom Authority.
Ancora più precisamente, la rinnovata sezione Pagine di SEOZoom e lo strumento “Rendimento Pagine” catalogano le pagine web di ogni sito inserito a progetto e le raggruppa in base al rendimento sui motori di ricerca, così da sapere in maniera chiara dove intervenire, come farlo e quando è il caso di eliminare pagine inutili o duplicate che sprecano il crawl budget.

In pratica, questo strumento ci offre una visualizzazione sintetica e immediata degli URL che impegnano e sprecano più risorse dei crawler, così da poter intervenire e rendere più efficace la gestione del sito nel suo complesso.
Le considerazioni finali sul crawl budget
In definitiva, dovrebbe essere abbastanza chiaro che avere sotto controllo il crawl budget è molto importante, perché può essere un’indicazione positiva del fatto che le nostre pagine piacciano a Google, soprattutto se il nostro sito viene scansionato ogni giorno, più volte al giorno.
Secondo Illyes – autore già nel 2017 di un approfondimento sul blog ufficiale di Google – però il crawl budget non dovrebbe preoccupare troppo se “le nuove pagine tendono a essere sottoposte a scansione lo stesso giorno in cui vengono pubblicate” o “se un sito ha meno di qualche migliaio di URL”, perché in genere questo significa che la scansione di Googlebot funziona in modo efficiente.
Anche altre voci pubbliche di Google hanno spesso invitato proprietari di siti e webmaster a non preoccuparsi in maniera esagerata del crawl budget, o meglio a non pensare esclusivamente agli aspetti tecnici assoluti quando si eseguono interventi di ottimizzazione onsite. Ad esempio, in uno scambio su Twitter John Mueller consiglia piuttosto di concentrarsi prima sugli effetti positivi in termini di user experience e di incremento delle conversioni che potrebbero derivare da questa strategia.
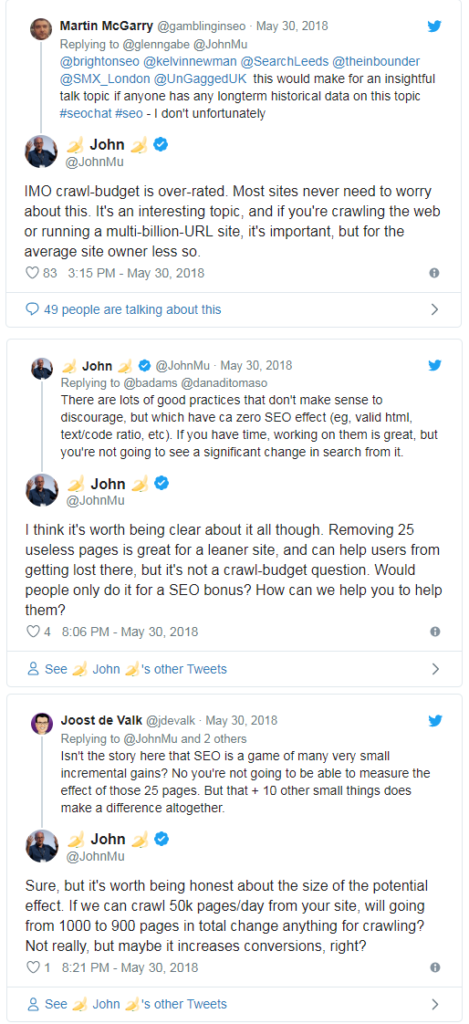
Per la precisione, il Search Advocat sostiene che esistono molte buone pratiche per ottimizzare il crawl budget, ma possono avere pochi effetti pratici: ad esempio, rimuovere 25 pagine inutili è un’ottima soluzione per rendere i siti più snelli ed evitare che gli utenti si perdano durante la navigazione, ma non è un’operazione che si deve fare per migliorare il crawl budget (crawl-budget question) o per sperare in riscontri concreti sul ranking.
Come funzionano crawl budget e rendering? La sintesi di Google
Ed è lo stesso John Mueller a darci qualche indicazione sintetica, ma comunque interessante, su crawl budget, tecniche per cercare di ottimizzarne la gestione e aspetti correlati, come la caching o la riduzione delle risorse embedded e il loro impatto sulla velocità del sito per gli utenti.
Lo spunto di partenza per questa riflessione, approfondita in un episodio della serie #AskGooglebot, nasce dalla domanda di un utente via Twitter, che chiede se “un utilizzo intenso di WRS può anche ridurre il crawl budget di un sito”.
Come di consueto, il Search Advocate chiarisce le definizioni dei termini e delle attività, ricordando che:
- WRS è il Web Rendering Service, ovvero il sistema che Googlebot usa per renderizzare le pagine come un browser, in modo da poter indicizzare tutto allo stesso modo in cui lo vedrebbero gli utenti.
- Crawl Budget si riferisce al sistema che “usiamo per limitare il numero di richieste che facciamo ad un server, in modo da non causare problemi durante il nostro crawling”.
Come Google gestisce il crawl budget di un sito
Mueller ribadisce ancora una volta che il crawl budget non è un tema che dovrebbe preoccupare tutti i siti, perché in genere “Google non ha problemi a fare crawling di sufficienti URL per la maggior parte dei siti”. E anche se non c’è una soglia specifica o un benchmark di riferimento, in linra di massima il crawl budget “è un argomento che dovrebbe interessare per lo più grandi siti web, quelli con oltre centomila URL”.
In generale, i sistemi di Google riescono automaticamente a determinare il numero massimo di richieste che un server può elaborare in un determinato periodo di tempo. Questa operazione viene “fatta automaticamente e regolata nel tempo”, spiega Mueller, perché “appena vediamo che il server inizia a rallentare o a restituire errori del server, riduciamo il crawl budgeta disposizione dei nostri crawler”.
Google e rendering
Il Googler si sofferma anche sul rendering, spiegando ai siti che i servizi del motore di ricerca devono “poter accedere a contenuti embedded, come file JavaScript, CSS, file, immagini e video e alle risposte del server dalle API che sono utilizzate nelle pagine”.
Google fa un “largo uso di caching per cercare di ridurre il numero di richieste necessarie per renderizzare una pagina, ma nella maggior parte dei casi il rendering risulta più di una semplice richiesta, quindi più di un semplice file HTML che viene inviato al server”.
Ridurre le risorse embedded aiuta anche gli utenti
In definitiva, secondo Mueller, soprattutto quando si opera su grandi siti può essere d’aiuto per il crawling “ridurre il numero di risorse embedded necessarie per renderizzare una pagina”.
Questa tecnica permette anche di offrire pagine più veloci per gli utenti e di ottenere quindi due risultati importanti per la nostra strategia.
Dubbi e falsi miti: Google chiarisce le questioni sul crawl budget
La rilevanza sempre crescente del tema ha portato, quasi inevitabilmente, alla nascita e alla proliferazione di tantissimi falsi miti sul crawl budget, alcuni dei quali elencati anche nella guida ufficiale di Google: ad esempio, tra le notizie sicuramente false ci sono che
- Possiamo controllare Googlebot con la regola “crawl-delay” (in realtà, Googlebot non elabora la regola non standard “crawl-delay” del file robots.txt).
- URL alternativi e contenuti incorporati non contano ai fini del budget di scansione (qualsiasi URL di cui Googlebot esegue la scansione viene conteggiato al budget).
- Google preferisce URL puliti privi di parametri di ricerca (in realtà può eseguire la scansione dei parametri).
- Google preferisce contenuti vecchi, che hanno più peso, rispetto a contenuti nuovi (se la pagina è utile, resta tale indipendentemente dall’età dei contenuti).
- Google preferisce che i contenuti siano i più aggiornati possibili, quindi conviene continuare ad apportare piccole modifiche alla pagina (i contenuti vanno aggiornati secondo necessità, e non serve a nulla far apparire le pagine rinnovate apportandovi solo banali modifiche e aggiornandone la data).
- La scansione è un fattore di ranking (non è così).
Il crawl budget è stato anche il tema centrale di un appuntamento con SEO Mythbusting season 2, la serie in cui il Developer Advocate di Google Martin Splitt cerca di sfatare miti e chiarire i dubbi frequenti sui topic SEO.
Nello specifico, nell’episodio che avuto come ospite Alexis Sanders, Senior Account Manager presso l’agenzia di marketing Merkle, il focus è andato sulle definizioni e dai consigli di gestione del budget di scansione, un argomento che crea parecchie difficoltà di comprensione a chi opera nel search marketing.
Martin Splitt inizia quindi il suo approfondimento dicendo che “quando parliamo di Google Search, di indicizzazione e di crawling, dobbiamo fare una sorta di compromesso: Google vuole sottoporre a scansione la quantità massima di informazioni nel più breve tempo possibile, ma senza sovraccaricare i server”, trovando cioè il crawl limit o crawl rate.
La definizione di crawl rate
Per la precisione, il crawl rate viene definito come il numero massimo di richieste parallele che Googlebot può fare in simultanea senza sovraccaricare un server, e quindi in pratica indica la quota massima di stress che Google può esercitare su un server senza portare nulla al crash o generare disagi per questo sforzo.
Google deve però fare attenzione solo alle risorse altrui, ma anche alle proprie, perché “il Web è enorme e non possiamo sottoporre a scansione tutto per tutto il tempo, ma fare alcune distinzioni”, spiega Splitt.
Ad esempio, prosegue, “un sito di news probabilmente cambia piuttosto spesso, e quindi noi probabilmente dobbiamo stare al suo passo con una frequenza elevata: al contrario, un sito sulla storia del kimchi probabilmente non cambierà così assiduamente, perché la storia non ha lo stesso passo rapido del settore delle notizie di attualità”.
Che cos’è il crawl demand
Si spiega così che cos’è il crawl demand, ovvero la frequenza con cui Googlebot sottopone a scansione un sito (o, meglio, a una tipologia di sito) in base alla sua probabilità di aggiornamento. Come dice Splitt nel video, “cerchiamo di capire se è il caso di passare più spesso o se invece possiamo dare una controllata di tanto in tanto”.
Il processo di decisione di questo fattore si basa sull’identificazione che Google fa del sito alla prima scansione, quando in pratica prende le “impronte digitali” dei suoi contenuti, vedendo il topic della pagina (che sarà usato anche per la deduplicazione, in fase successiva) e analizzando anche la data dell’ultima modifica.
Il sito ha la possibilità di comunicare le date a Googlebot – ad esempio, attraverso i dati strutturati o altri elementi temporali in pagina – che “più o meno tiene traccia della frequenza e della tipologia dei cambiamenti: se rileviamo che la frequenza delle modifiche è molto bassa, allora non sottoporremo il sito a scansione con particolare cadenza”.
La frequenza di scansione non riguarda la qualità dei contenuti
Molto interessante è la puntualizzazione successiva del Googler: questo tasso di scansione non ha nulla a che vedere con la qualità, dice. “Puoi avere contenuti fantastici che si posizionano benissimo, che non cambiano mai”, perché ciò la questione in questo caso è “se Google deve passare di frequente sul sito per un crawling o se può lasciarlo tranquillo per un certo periodo di tempo”.
Per aiutare Google a rispondere in modo corretto a questa domanda, i webmaster hanno a disposizione vari strumenti che danno “suggerimenti”: oltre ai già citati dati strutturati, si possono usare ETag o gli HTTP headers, utili per segnalare la data dell’ultima modifica nelle sitemap. È però importante che gli aggiornamenti siano utili: “Se aggiorni solo la data nella sitemap e ci accorgiamo che non c’è alcuna modifica vera sul sito, o che sono cambiamenti minimi, non ci sei di aiuto” nell’individuare la probabile frequenza di modifiche.
Quando il crawl budget è un problema?
Secondo Splitt, il crawl budget è comunque un tema che prioritariamente dovrebbe interessare o preoccupare i siti enormi, “diciamo con milioni di url e di pagine”, a meno che tu “non abbia un server scadente e inaffidabile”. Ma in quel caso, “più che sul crawl budget dovresti concentrarti sull’ottimizzazione del server”, prosegue.
Di solito, secondo il Googler, si parla di crawl budget a sproposito, quando non c’è un vero problema collegato; per lui, i crawl budget issues capitano quando un sito nota che Google scopre ma non scansiona le pagine di cui gli importa per un periodo ampio di tempo e tali pagine non presentano problemi o errori di sorta.
Nella maggioranza dei casi, invece, Google decide di sottoporre a scansione ma non indicizzare le pagine perché “non ne vale la pena a causa della scarsa qualità del contenuto presente”. In genere, questi url sono marcati come “esclusi” nel rapporto sulla copertura dell’Indice della Google Search Console, chiarisce il video.
La crawl frequency non è un indicatore di qualità
Avere un sito sottoposto a scansione con grande frequenza non rappresenta necessariamente un aiuto per Google perché la crawl frequency non è un segnale di qualità, spiega ancora Splitt, perché per il motore di ricerca è OK anche se “avere qualcosa sottoposto a crawling, indicizzato e che non cambia più” e non richiede altri passaggi del bot.
Qualche consiglio più mirato arriva per gli e-Commerce: se ci sono tantissime piccole pagine molto simili tra loro con contenuti affini, bisognerebbe pensare alla loro utilità chiedendosi innanzitutto se abbia senso la loro esistenza. Oppure, valutare la possibilità di estendere il contenuto per renderlo migliore? Ad esempio, se si tratta solo di prodotti che variano per una piccola caratteristica, si potrebbero raggruppare in una sola pagina con un testo descrittivo che include tutte le variazioni possibili (anziché avere 10 piccole pagine per ogni possibilità).
Il peso di Google sui server
Il crawl budget si collega a una serie di questioni, quindi: tra quelle citate ci sono appunto la duplicazione o la ricerca delle pagine, ma anche la velocità del server è un tema delicato. Se il sito si appoggia a un server che di tanto in tanto crolla, Google potrebbe avere difficoltà a comprendere se questo succeda per le caratteristiche povere del server o a causa di un sovraccarico delle sue richieste.
A proposito di gestione delle risorse del server, poi, Splitt spiega anche come funziona l’attività del bot (e quindi quello che si vede nei log files) nelle fasi iniziali della scoperta di Google o quando, ad esempio, si compie una migrazione del server: inizialmente, un incremento dell’attività di crawling, seguito da una lieve riduzione, che continua creando quindi un’onda. Spesso, però, il cambio di server non richiede una nuova riscoperta da parte di Google (a meno di passare da qualcosa di rotto a qualcosa che funziona!) e quindi l’attività del bot per il crawling resta stabile come prima dello switch.
Crawl budget e migrazione, i consigli di Google
Piuttosto delicata è anche la gestione dell’attività di scansione di Googlebot nel corso delle migrazioni complessive del sito: il consiglio che arriva dal video a chi si trova nel mezzo di queste situazioni è di aggiornare progressivamente la sitemap e segnalare a Google che cosa sta cambiando, così da informare il motore di ricerca che ci sono state modifiche utili da seguire e verificare.
Questa strategia offre ai webmaster un piccolo controllo di come Google scopre i cambiamenti nel corso di una migrazione, anche se in linea di massima è possibile anche attendere semplicemente che l’operazione si completi.
Ciò che conta è assicurare (e assicurarsi) che entrambi i server siano funzionanti e lavorino regolarmente, senza crolli improvvisi momentanei o status code di errore; importante è anche impostare correttamente i redirect e verificare che non ci siano risorse rilevanti bloccate sul nuovo sito attraverso un file robots.txt non adeguatamente aggiornato al nuovo sito post-migrazione.

Come funziona il crawl budget
Una domanda di Alexis Sanders ci riporta al tema centrale dell’appuntamento e consente a Martin Splitt di spigare come funziona il crawl budget e su quale livello del sito interviene: solitamente, Google opera sul livello del sito, quindi considera tutto ciò che trova sullo stesso dominio. I sottodomini possono essere scansionati a volte, mentre in altri casi risultano esclusi, mentre per i CDN “non c’è nulla di cui preoccuparsi”.
Un altro suggerimento pratico che arriva dal Googler riguarda la gestione dei contenuti user-generated, o più in generale le ansie sulla quantità di pagine presenti su un sito: “Puoi dirci di non indicizzare o di non scansionare contenuti che sono di bassa qualità”, ricorda Splitt, e quindi per lui la crawl budget optimization è “qualcosa che riguarda più il lato dei contenuti che l’aspetto dell’infrastruttura tecnica”, (approccio che è in linea con quello dei nostri strumenti!).
Non sprecare il tempo e le risorse di Google
In definitiva, lavorare sul crawl budget significa anche non sprecare il tempo e le risorse di Google, anche attraverso una serie di soluzioni molto tecniche come la gestione della cache.
In particolare, Splitt spiega che Google “cerca di essere il più aggressivo possibile quando fa caching di sub-risorse, come CSS, JavaScript, chiamate API, tutto questo genere di cose”. Se un sito ha “chiamate API che non sono richieste GET, allora non possiamo metterli in cache, e quindi bisogna essere molto attenti a fare le richieste POST o simili, che alcune API fanno di default”, perché Google non può “metterle in cache e questo consumerà più rapidamente il crawl budget del sito”.
